|
БОеТНЋНщЩмШчКЮАВзАHBaseКЭГѕЪМХфжУЁЃ ашвЊгУJavaКЭHadoopРДДІРэHBaseЃЌЫљвдБиаыЯТдиjavaКЭHadoopВЂАВзАЯЕЭГжаЁЃ
АВзАЧАЩшжУ
АВзАHadoopдкLinuxЛЗОГЯТжЎЧАЃЌашвЊНЈСЂКЭЪЙгУLinux SSH(АВШЋShell)ЁЃАДееЯТУцЩшСЂLinuxЛЗОГЬсЙЉЕФВНжшЁЃ
ДДНЈвЛИігУЛЇ
ЪзЯШЃЌНЈвщДгUnixДДНЈвЛИіЕЅЖРЕФHadoopгУЛЇЃЌЮФМўЯЕЭГИєРыHadoopЮФМўЯЕЭГЁЃАДееЯТУцИјГіДДНЈгУЛЇЕФВНжшЁЃ
ПЊЦєrootЪЙгУУќСю “su”.
ЪЙгУrootеЪЛЇУќСюДДНЈгУЛЇ “useradd username”.
ЯждкЃЌПЩвдЪЙгУУќСюДђПЊвЛИіЯжгаЕФгУЛЇеЪЛЇ “su username”.
ДђПЊLinuxжеЖЫЃЌЪфШывдЯТУќСюРДДДНЈвЛИігУЛЇ
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwd |
SSHЩшжУКЭУмдПЩњГЩ
SSHЩшжУашвЊдкМЏШКЩЯжДааВЛЭЌЕФВйзїЃЌШчЦєЖЏЃЌЭЃжЙКЭЗжВМЪНЪиЛЄshellВйзїЁЃНјааЩэЗнбщжЄВЛЭЌЕФHadoopгУЛЇЃЌашвЊвЛжжгУгкHadoopЕФгУЛЇЬсЙЉЕФЙЋдП/ЫНдПЖдЃЌВЂгУВЛЭЌЕФгУЛЇЙВЯэЁЃ
вдЯТЕФУќСюБЛгУгкЩњГЩЪЙгУSSHУмдПжЕЖдЁЃИДжЦЙЋдПДгid_rsa.pubЮЊauthorized_keysЃЌВЂЬсЙЉЫљгаепЃЌЖСаДШЈЯоЕНauthorized_keysЮФМўЁЃ
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys |
бщжЄssh
АВзАJava
JavaЪЧHadoopКЭHBaseжївЊЯШОіЬѕМўЁЃЪзЯШгІИУЪЙгУ"java -verion"МьВщjavaЪЧЗёДцдкдкФњЕФЯЕЭГЩЯЁЃ java -version УќСюЕФгяЗЈШчЯТЁЃ
ШчЙћвЛЧае§ГЃЃЌЫќЛсЕУЕНЯТУцЕФЪфГіЁЃ
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode) |
ШчЙћJavaЛЙУЛгаАВзАдкЯЕЭГжаЃЌШЛКѓАДееЯТУцИјГіЕФВНжшАВзАJavaЁЃ
ВНжш 1
ЯТдиJavaЃЈJDK - X64.tar.gzЃЉЃЌПЩвдЭЈЙ§ЗУЮЪвдЯТСДНгhttp://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.htmlЁЃ
jdk-7u71-linux-x64.tar.gz НЋБЛЯТдиЕНЯЕЭГЁЃ
ВНжш 2
вЛАуРДЫЕЃЌЯТдиЮФМўМажаАќКЌгаJavaЮФМўЁЃбщжЄЫќЃЌЪЙгУЯТУцЕФУќСюЬсШЁjdk-7u71-linux-x64.gzЮФМўЁЃ
$ cd Downloads/
$ ls
jdk-7u71-linux-x64.gz
$ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gz |
ВНжш 3
ЮЊСЫЪЙJavaЬсЙЉИјЫљгагУЛЇЃЌБиаыНЋЫќвЦЖЏЕН“/usr/local/”ЁЃДђПЊжеЖЫШЛКѓвдrootгУЛЇЩэЗнМќШывдЯТУќСюЁЃ
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exit |
ВНжш 4
гаЙиЩшжУPATHКЭJAVA_HOMEБфСПЃЌЬэМгвдЯТУќСюЕН?/.bashrcЮФМўЁЃ
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH= $PATH:$JAVA_HOME/bin |
ЯждкДгжеЖЫбщжЄ java -version УќСюШчЩЯЪіЫЕУї
ЯТдиHadoop
АВзАJavaжЎКѓЃЌНгЯТРДОЭЪЧАВзАHadoopЁЃЪзЯШЪЙгУ“Hadoop version” УќСюбщжЄ Hadoop ЪЧЗёДцдкЃЌШчЯТЫљЪОЁЃ
ШчЙћвЛЧае§ГЃЃЌЫќЛсЕУЕНЯТУцЕФЪфГіЁЃ
Hadoop 2.6.0
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using
/home/hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jar |
ШчЙћЯЕЭГЩЯЪЧЮоЗЈевЕН HadoopЃЌФЧУДжЄУїЛЙЮДАВзАЃЌЯждкЯТдиHadoopдкФњЕФЯЕЭГЩЯЁЃАДееЯТУцИјГіЕФУќСюЁЃ
ДгApacheШэМўЛљН№ЛсЯТдиВЂЪЙгУЯТУцЕФУќСюЬсШЁ Hadoop-2.6.0ЁЃ
$ su
password:
# cd /usr/local
# wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop-
2.6.0/hadoop-2.6.0-src.tar.gz
# tar xzf hadoop-2.6.0-src.tar.gz
# mv hadoop-2.6.0/* hadoop/
# exit |
АВзА Hadoop
ПЩдкШЮКЮашвЊЕФЗНЪНАВзАHadoopЁЃдкетРяНЋеЙЪО HBase ФЃФтЗжВМЪНФЃЪНЙІФмЃЌвђДЫФЃФтЗжВМЪНФЃЪНЕФHadoopАВзАЁЃ
АДЯТУцЕФВНжшРДАВзА Hadoop 2.4.1.
Ек1ВН - ЩшжУHadoop
ПЩвдЭЈЙ§ИНМгЯТУцЕФУќСюдк ?/ .bashrcЮФМўжавдЩшжУ Hadoop ЛЗОГБфСПЁЃ
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME; |
ЯждкЃЌгІгУЫљгаИќИФЕНЕБЧАе§дкдЫааЕФЯЕЭГЁЃ
Ек2ВН - HadoopХфжУ
евЕНЮЛгк “$HADOOP_HOME/etc/hadoop” ФПТМЯТЫљгаЕФHadoopХфжУЮФМўЁЃИљОнашвЊHadoopНЋХфжУЮФМўжаЕФФкШнзїаоИФЁЃ
$ cd $HADOOP_HOME/etc/hadoop |
ЮЊСЫЪЙгУJavaПЊЗЂHadoopГЬађЃЌБиаыгУjavaдкЯЕЭГжаЕФЮЛжУРДЬцЛЛ hadoop-env.shЮФМўжаЕФ javaЛЗОГБфСПJAVA_HOMEЕФжЕЁЃ
export JAVA_HOME=/usr/local/jdk1.7.0_71 |
БрМвдЯТЮФМўРДХфжУHadoopЁЃ
core-site.xml
core-site.xmlЮФМўжаАќКЌЃЌШчЃКгУгкHadoopЪЕР§ЕФЖЫПкКХЃЌЗжХфИјЮФМўЯЕЭГЃЌДцДЂЦїЯожЦгУгкДцДЂЪ§ОнДцДЂЦїКЭЖС/аДЛКГхЦїЕФДѓаЁЕФаХЯЂЁЃ
ДђПЊcore-site.xmlЃЌВЂдк<configuration>КЭ</configuration>БъЧЉжЎМфЬэМгвдЯТЪєадЁЃ
<configuration>
<property>
<name> fs.default.</name>
<value> /hdfs://localhost:9000</value>
</property>
</configuration> |
hdfs-site.xml
hdfs-site.xmlЮФМўжаАќКЌЃЌШчЃКИДжЦЪ§ОнЕФжЕЃЌNameNodeЕФТЗОЖЃЌБОЕиЮФМўЯЕЭГЃЌвЊДцДЂHadoopЛљДЁМмЙЙЕФDatanodeТЗОЖЕФаХЯЂЁЃ
МйЩшгавдЯТЪ§ОнЁЃ
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file
system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanode |
ДђПЊетИіЮФМўЃЌВЂдк<configuration>КЭ</configuration> БъМЧжЎМфЬэМгвдЯТЪєадЁЃ
<configuration>
<property>
<name> dfs.replication</name>
<value> 1</value>
<property>
</property>
<name> ;dfs.name.dir</name>
<value> ;file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
<property>
</property>
<name> dfs.data.dir</name>
<value> file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration> |
зЂЃКЩЯУцЕФЮФМўЃЌЫљгаЕФЪєаджЕЪЧгУЛЇЖЈвхЕФЃЌПЩвдИљОнздМКЕФHadoopЕФЛљДЁМмЙЙНјааИќИФЁЃ
yarn-site.xml
ДЫЮФМўгУгкХфжУГЩyarnдкHadoopжаЁЃДђПЊyarn-site.xmlЮФМўЃЌВЂдк<configuration><configuration>БъЧЉжЎЧАЬэМгвдЯТЪєадЕНетИіЮФМўжаЁЃ
<configuration> ;
<property>
<name> yarn.nodemanager.aux-services</name>
<value> mapreduce_shuffle</value>
</property> ;
<configuration> |
mapred-site.xml
ДЫЮФМўгУгкжИЖЈMapReduceПђМмвдЪЙгУЁЃФЌШЯЧщПіЯТHadoopАќКЌyarn-site.xmlФЃАхЁЃЪзЯШЃЌЫќашвЊДгmapred-site.xmlИДжЦФЃАхЕНmapred-site.xmlЮФМўЃЌЪЙгУЯТУцЕФУќСюРДЁЃ
$ cp mapred-site.xml.template mapred-site.xml |
ДђПЊ mapred-site.xml ЮФМўЃЌВЂдк<configuration> КЭ </configuration>БъЧЉжЎМфЬэМгвдЯТЪєадЁЃ
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> |
бщжЄHadoopАВзА
ЯТУцЕФВНжшЪЧгУРДбщжЄHadoopЕФАВзАЁЃ
Ек1ВН - УћГЦНкЕуЩшжУ
ЩшжУУћГЦНкЕуЪЙгУ“hdfs namenode -format”УќСюШчЯТ
$ cd ~
$ hdfs namenode -format |
дЄЦкЕФНсЙћШчЯТЁЃ
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/ |
Ек2ВН - бщжЄHadoop DFS
ЯТУцЕФУќСюгУРДЦєЖЏDFSЁЃжДааетИіУќСюНЋЦєЖЏHadoopЮФМўЯЕЭГЁЃ
дЄЦкЕФНсЙћШчЯТЁЃ
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0] |
Ек3ВН - бщжЄYarnНХБО
ЯТУцЕФУќСюгУРДЦєЖЏyarnНХБОЁЃжДааДЫУќСюНЋЦєЖЏyarnЪиЛЄНјГЬЁЃ
дЄЦкЕФНсЙћШчЯТЁЃ
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.out |
Ек4ВН - ЗУЮЪHadoopЩЯЕФфЏРРЦї
ЗУЮЪHadoopЕФФЌШЯЖЫПкКХЮЊ50070ЁЃЪЙгУвдЯТЭјжЗЃЌвдЛёШЁHadoopЗўЮёдкфЏРРЦїжаЁЃ
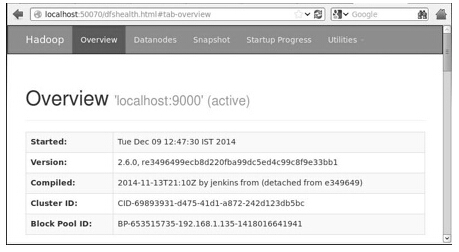
Ек5ВН - бщжЄМЏШКжаЕФЫљгагІгУГЬађ
ЗУЮЪШКМЏЕФЫљгагІгУГЬађЕФФЌШЯЖЫПкКХЮЊ8088ЁЃЪЙгУвдЯТURLЗУЮЪИУЗўЮёЁЃ
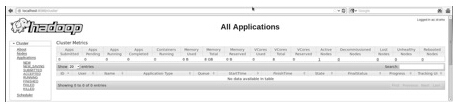
HBaseАВзА
ЕЅЛњФЃЪНЃЌФЃФтЗжВМЪНФЃЪНЃЌвдМАШЋЗжВМЪНФЃЪНЃКПЩвддкШЮКЮЕФШ§жжФЃЪНРДАВзАHBaseЁЃ
дкЕЅЛњФЃЪНЯТАВзАHBase
ЪЙгУ “wget” УќСюЯТдиHBaseЃЌЯТдиЭјжЗЮЊЃК>http://www.interiordsgn.com/apache/hbase/stable/ ЃЌбЁдёзюаТЕФЮШЖЈАцБОЃЌВЂЪЙгУ tar “zxvf” УќСюНЋЦфНтбЙЫѕЁЃЧыВЮМћЯТУцЕФУќСюЁЃ
$cd usr/local/
$wget http://www.interior-dsgn.com/apache/hbase/stable/hbase-0.98.8-
hadoop2-bin.tar.gz
$tar -zxvf hbase-0.98.8-hadoop2-bin.tar.gz |
ЧаЛЛЕНГЌМЖгУЛЇФЃЪНЃЌНЋHBaseЮФМўИДжЦЕН/usr/localЃЌШчЯТЭМЫљЪОЁЃ
$su
$password: enter your password here
mv hbase-0.99.1/* Hbase/ |
дкЕЅЛњФЃЪНЯТХфжУHBase
дкМЬајHBaseжЎЧАЃЌашвЊБрМЯТСаЮФМўКЭХфжУHBaseЁЃ
hbase-env.sh
ЮЊHBaseЩшжУJavaФПТМЃЌВЂДгconfЮФМўМаДђПЊhbase-env.shЮФМўЁЃБрМJAVA_HOMEЛЗОГБфСПЃЌИФБфТЗОЖЕНЕБЧАJAVA_HOMEБфСПЃЌШчЯТЭМЫљЪОЁЃ
cd /usr/local/Hbase/conf
gedit hbase-env.sh |
етНЋДђПЊHBaseЕФenv.shЮФМўЁЃЯждкЪЙгУЕБЧАжЕЬцЛЛЯжгаJAVA_HOMEжЕЃЌШчЯТЭМЫљЪОЁЃ
export JAVA_HOME=/usr/lib/jvm/java-1.7.0 |
hbase-site.xml
етЪЧHBaseЕФжїХфжУЮФМўЁЃЭЈЙ§дк /usr/local/HBase ДђПЊHBaseжїЮФМўМаЃЌЩшжУЪ§ОнФПТМЕНКЯЪЪЕФЮЛжУЁЃдк conf ЮФМўМаРяУцгаМИИіЮФМўЃЌЯждкДђПЊhbase-site.xmlЮФМўЃЌШчЯТЭМЫљЪОЁЃ
#cd /usr/local/HBase/
#cd conf
# gedit hbase-site.xml |
дкhbase-site.xmlЮФМўРяУцЃЌевЕН <configuration> КЭ </configuration> БъЧЉЁЃВЂдкЦфжаЃЌЩшжУЪєадМќУћЮЊ“hbase.rootdir”ЃЌШчЯТЭМЫљЪОЕФHBaseФПТМЁЃ
<configuration>
//Here you have to set the path where you want HBase to store its files.
<property>
<name>hbase.rootdir</name>
<value>file:/home/hadoop/HBase/HFiles</value>
</property>
//Here you have to set the path where you want HBase to store its built in zookeeper files.
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zookeeper</value>
</property>
</configuration> |
ЕНДЫ HBase ЕФАВзАХфжУвбГЩЙІЭъГЩЁЃПЩвдЭЈЙ§ЪЙгУ HBase ЕФ bin ЮФМўМажаЬсЙЉ start-hbase.sh НХБОЦєЖЏ HBaseЁЃЮЊДЫЃЌДђПЊHBase жїЮФМўМаЃЌШЛКѓдЫаа HBase ЦєЖЏНХБОЃЌШчЯТЭМЫљЪОЁЃ
<
$cd /usr/local/HBase/bin
$./start-hbase.sh |
ШчЙћвЛЧаЫГРћЃЌЕБдЫааHBaseЦєЖЏНХБОЃЌЫќЛсЬсЪОвЛЬѕЯћЯЂЃКHBase has started
starting master, logging to /usr/local/HBase/bin/../logs/hbase-tpmaster-localhost.localdomain.out |
дкФЃФтЗжВМЪНФЃЪНАВзАHBase
ЯждкЃЌРДПДПДШчКЮАВзАHBaseдкФЃФтЗжВМЪНФЃЪНЁЃ
CONFIGURING HBASE
МЬајНјааHBaseжЎЧАЃЌдкБОЕиЯЕЭГЛђдЖГЬЯЕЭГЩЯХфжУHadoop HDFSВЂШЗБЃЫќУЧе§дкдЫааЁЃШчЙћЫќе§дкдЫаадђЯШЭЃжЙHBaseЁЃ
hbase-site.xml
БрМhbase-site.xmlЮФМўжаЬэМгвдЯТЪєадЁЃ
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property> |
ЫќЛсЬсЕНдкHBaseЕФФФжжФЃЪНдЫааЁЃ ДгБОЕиЮФМўЯЕЭГЯрЭЌЕФЮФМўИФБфhbase.rootdirЃЌHDFSЪЕР§ЕижЗЪЙгУhdfs://// URI гяЗЈЁЃдкБОЕижїЛњЕФЖЫПк8030ЩЯдЫааHDFSЁЃ
<property>
<name>>hbase.rootdir</name>
<value>hdfs://localhost:8030/hbase</value>
</property> |
ЦєЖЏHBase
ОЙ§ХфжУНсЪјКѓЃЌфЏРРЕНHBaseЕФжїЮФМўМаЃЌВЂЪЙгУвдЯТУќСюЦєЖЏHBaseЁЃ
$cd /usr/local/HBase
$bin/start-hbase.sh |
зЂЃКдкЦєЖЏ HBase жЎЧАЃЌЧыШЗБЃ Hadoop дЫааЁЃ
МьВщдкHDFSЕФHBaseФПТМ
HBaseДДНЈЦфФПТМдкHDFSжаЁЃвЊВщПДДДНЈЕФФПТМЃЌфЏРРЕНHadoop binВЂМќШывдЯТУќСю
$ ./bin/hadoop fs -ls /hbase |
ШчЙћвЛЧаЫГРћЕФЛАЃЌЫќЛсИјЯТУцЕФЪфГіЁЃ
Found 7 items
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/.tmp
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/WALs
drwxr-xr-x - hbase users 0 2014-06-25 18:48 /hbase/corrupt
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/data
-rw-r--r-- 3 hbase users 42 2014-06-25 18:41 /hbase/hbase.id
-rw-r--r-- 3 hbase users 7 2014-06-25 18:41 /hbase/hbase.version
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/oldWALs |
ЦєЖЏКЭЭЃжЙжїЗўЮёЦї
ЪЙгУ“local-master-backup.sh”ОЭПЩвдЦєЖЏЖрДя10ЬЈЗўЮёЦїЁЃДђПЊHBaseЕФmasterжїЮФМўМаЃЌВЂжДаавдЯТУќСюРДЦєЖЏЫќЁЃ
$ ./bin/local-master-backup.sh 2 4 |
вЊжажЙБИЗнжїЗўЮёЃЌашвЊЫќЕФНјГЬIDЃЌЫќБЛДцДЂдквЛИіЮФМўУћЮЊ“/tmp/hbase-USER-X-master.pid”жаЃЌПЩвдЪЙгУЯТУцЕФУќСюжажЙБИЗнжїЗўЮёЁЃ
$ cat /tmp/hbase-user-1-master.pid |xargs kill -9 |
ЦєЖЏКЭЭЃжЙЧјгђЗўЮёЦї
ПЩвдЪЙгУЯТУцЕФУќСюРДдЫаадкЕЅвЛЯЕЭГжаЕФЖрИіЧјгђЕФЗўЮёЦїЁЃ
$ .bin/local-regionservers.sh start 2 3 |
вЊЭЃжЙЧјгђЗўЮёЦїЃЌПЩвдЪЙгУЯТУцЕФУќСюЁЃ
$ .bin/local-regionservers.sh stop 3 |
ЦєЖЏHBaseShell
ЯТУцИјГіЕФЪЧЦєЖЏHBase shellЕФВНжшЁЃДђПЊжеЖЫЃЌВЂЕЧТМЮЊГЌМЖгУЛЇЁЃ
ЦєЖЏHadoopЮФМўЯЕЭГ
ЭЈЙ§HadoopжїФПТМЯТЕФsbinФПТМЮФМўМафЏРРВЂЦєЖЏHadoopЮФМўЯЕЭГЃЌШчЯТЫљЪОЁЃ
$cd $HADOOP_HOME/sbin
$start-all.sh |
ЦєЖЏHBase
ЭЈЙ§HBaseИљФПТМЯТЕФbinЮФМўМафЏРРВЂЦєЖЏHBaseЁЃ
$cd /usr/local/HBase
$./bin/start-hbase.sh |
ЦєЖЏHBaseжїЗўЮёЦї
етдкЯрЭЌФПТМЁЃЦєЖЏЫќЃЌШчЯТЭМЫљЪОЃК
$./bin/local-master-backup.sh start 2 (number signifies specific server.) |
ЦєЖЏЧјгђЗўЮё
ЦєЖЏЧјгђЗўЮёЦїЃЌШчЯТЫљЪОЁЃ
$./bin/./local-regionservers.sh start 3 |
ЦєЖЏHBase Shell
ПЩвдЪЙгУвдЯТУќСюЦєЖЏHBase shell
етЛсИјГіHBase shell ЕФЬсЪОЗћЃЌШчЯТЭМЫљЪОЁЃ
2014-12-09 14:24:27,526 INFO [main] Configuration.deprecation:
hadoop.native.lib is deprecated. Instead, use io.native.lib.available
HBase Shell; enter 'help' for list of supported commands.
Type "exit" to leave the HBase Shell
Version 0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri
Nov 14 18:26:29 PST 2014
hbase(main):001:0> |
HBaseЕФWebНчУц
вЊЗУЮЪ HBase ЕФ WebНчУцЃЌдкфЏРРЦїжаМќШывдЯТURL
вдЯТНчУцСаГіСЫЕБЧАе§дкдЫааЕФЧјгђЗўЮёЦїЃЌБИЗнжїЗўЮёвдМАHBaseБэЁЃ
HBaseЧјгђЗўЮёЦїКЭБИЗнжїЗўЮё
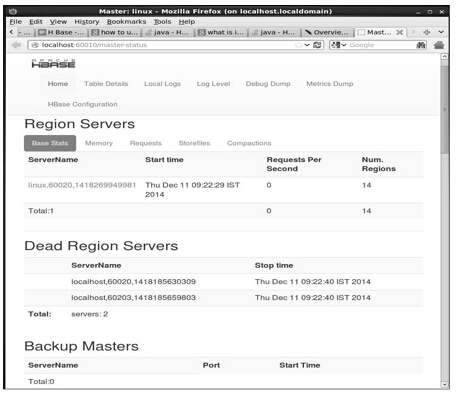
HBase Бэ
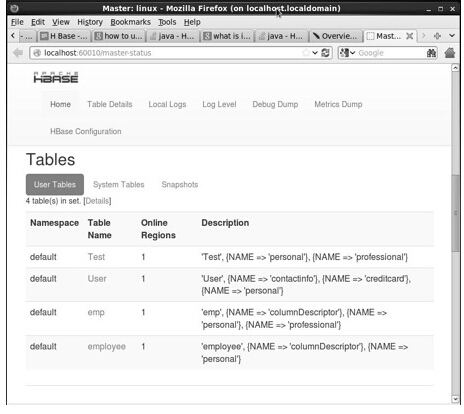
ЩшжУJavaЛЗОГ
вВПЩвдЪЙгУJavaПтНЛЛЅHBaseЃЌЕЋЗУЮЪHBaseЪЙгУJava APIжЎЧАЃЌашвЊЩшжУРрПтЕФТЗОЖЁЃ
ЩшжУРрТЗОЖ
МЬајНјаажЎЧАБрГЬЃЌдк.bashrcЮФМўжаЩшжУРрТЗОЖЕНHBaseПтЁЃДђПЊ.bashrcЮФМўБрМЃЌШчЯТЫљЪОЁЃ
ЮЊHBaseПтЩшжУРрТЗОЖЃЈHBaseЕФlibЮФМўМаЃЉЃЌШчЯТЭМЫљЪОЁЃ
export CLASSPATH=$CLASSPATH://home/hadoop/hbase/lib/* |
етЪЧЮЊСЫЗРжЙ“ЮДевЕНРрЃЈclass not foundЃЉ”вьГЃЃЌЭЌЪБЪЙгУJava APIЗУЮЪHBaseЁЃ
|









