|
HiveЪЧвЛИіЪ§ОнВжПтЛљДЁЙЄОпдкHadoopжагУРДДІРэНсЙЙЛЏЪ§ОнЁЃЫќМмЙЙдкHadoopжЎЩЯЃЌзмЙщЮЊДѓЪ§ОнЃЌВЂЪЙЕУВщбЏКЭЗжЮіЗНБуЁЃВЂЬсЙЉМђЕЅЕФsqlВщбЏЙІФмЃЌПЩвдНЋsqlгяОфзЊЛЛЮЊMapReduceШЮЮёНјаадЫааЁЃ
Ъѕгя“ДѓЪ§Он”ЪЧДѓаЭЪ§ОнМЏЃЌЦфжаАќРЈЬхЛ§ХгДѓЃЌИпЫйЃЌвдМАИїжжгЩгыШеОудіЕФЪ§ОнЕФМЏКЯЁЃЪЙгУДЋЭГЕФЪ§ОнЙмРэЯЕЭГЃЌЫќЪЧФбвдМгЙЄДѓаЭЪ§ОнЁЃвђДЫЃЌApacheШэМўЛљН№ЛсЭЦГіСЫвЛПюУћЮЊHadoopЕФНтОіДѓЪ§ОнЙмРэКЭДІРэФбЬтЕФПђМмЁЃ
Hadoop
HadoopЪЧвЛИіПЊдДПђМмРДДцДЂКЭДІРэДѓаЭЪ§ОндкЗжВМЪНЛЗОГжаЁЃЫќАќКЌСНИіФЃПщЃЌвЛИіЪЧMapReduceЃЌСэЭтвЛИіЪЧHadoopЗжВМЪНЮФМўЯЕЭГЃЈHDFSЃЉЁЃ
MapReduceЃКЫќЪЧвЛжжВЂааБрГЬФЃаЭдкДѓаЭМЏШКЦеЭЈгВМўПЩгУгкДІРэДѓаЭНсЙЙЛЏЃЌАыНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнЁЃ
HDFSЃКHadoopЗжВМЪНЮФМўЯЕЭГЪЧHadoopЕФПђМмЕФвЛВПЗжЃЌгУгкДцДЂКЭДІРэЪ§ОнМЏЁЃЫќЬсЙЉСЫвЛИіШнДэЮФМўЯЕЭГдкЦеЭЈгВМўЩЯдЫааЁЃ
HadoopЩњЬЌЯЕЭГАќКЌСЫгУгкажњHadoopЕФВЛЭЌЕФзгЯюФПЃЈЙЄОпЃЉФЃПщЃЌШчSqoop, Pig КЭ HiveЁЃ
Sqoop: ЫќЪЧгУРДдкHDFSКЭRDBMSжЎМфРДЛиЕМШыКЭЕМГіЪ§ОнЁЃ
Pig: ЫќЪЧгУгкПЊЗЂMapReduceВйзїЕФНХБОГЬађгябдЕФЦНЬЈЁЃ
Hive: ЫќЪЧгУРДПЊЗЂSQLРраЭНХБОгУгкзіMapReduceВйзїЕФЦНЬЈЁЃ
зЂЃКгаЖржжЗНЗЈРДжДааMapReduceзївЕЃК
ДЋЭГЕФЗНЗЈЪЧЪЙгУJava MapReduceГЬађНсЙЙЛЏЃЌАыНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнЁЃ
еыЖдMapReduceЕФНХБОЕФЗНЪНЃЌЪЙгУPigРДДІРэНсЙЙЛЏКЭАыНсЙЙЛЏЪ§ОнЁЃ
HiveВщбЏгябдЃЈHiveQLЛђHQLЃЉВЩгУHiveЮЊMapReduceЕФДІРэНсЙЙЛЏЪ§ОнЁЃ
HiveЪЧЪВУДЃП
HiveЪЧвЛИіЪ§ОнВжПтЛљДЁЙЄОпдкHadoopжагУРДДІРэНсЙЙЛЏЪ§ОнЁЃЫќМмЙЙдкHadoopжЎЩЯЃЌзмЙщЮЊДѓЪ§ОнЃЌВЂЪЙЕУВщбЏКЭЗжЮіЗНБуЁЃ
зюГѕЃЌHiveЪЧгЩFacebookПЊЗЂЃЌКѓРДгЩApacheШэМўЛљН№ЛсПЊЗЂЃЌВЂзїЮЊНјвЛВННЋЫќзїЮЊУћвхЯТApache HiveЮЊвЛИіПЊдДЯюФПЁЃЫќгУдкКУЖрВЛЭЌЕФЙЋЫОЁЃР§ШчЃЌбЧТэбЗЪЙгУЫќдк Amazon Elastic MapReduceЁЃ
Hive ВЛЪЧ
вЛИіЙиЯЕЪ§ОнПт
вЛИіЩшМЦгУгкСЊЛњЪТЮёДІРэЃЈOLTPЃЉ
ЪЕЪБВщбЏКЭааМЖИќаТЕФгябд
HiverЬиЕу
ЫќДцДЂМмЙЙдквЛИіЪ§ОнПтжаВЂДІРэЪ§ОнЕНHDFSЁЃ
ЫќЪЧзЈЮЊOLAPЩшМЦЁЃ
ЫќЬсЙЉSQLРраЭгябдВщбЏНаHiveQLЛђHQLЁЃ
ЫќЪЧЪьжЊЃЌПьЫйЃЌПЩРЉеЙКЭПЩРЉеЙЕФЁЃ
HiveМмЙЙ
ЯТУцЕФзщМўЭМУшЛцСЫHiveЕФНсЙЙЃК

ИУзщМўЭМАќКЌВЛЭЌЕФЕЅдЊЁЃЯТБэУшЪіУПИіЕЅдЊЃК

HiveЙЄзїдРэ
ЯТЭМУшЪіСЫHive КЭHadoopжЎМфЕФЙЄзїСїГЬЁЃ

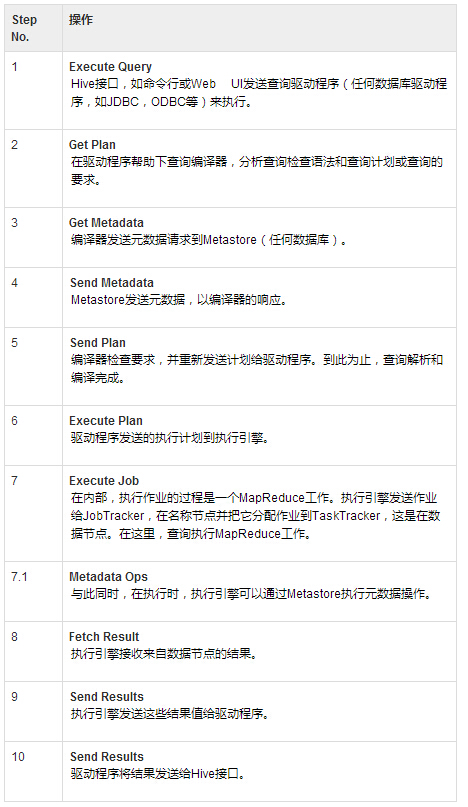
ЯТБэЖЈвхHiveКЭHadoopПђМмЕФНЛЛЅЗНЪНЃК
|









