var1 = 'Hello World!'
var2 = "Python Programming" |
#!/usr/bin/python
var1 = 'Hello World!'
var2 = "Python Programming"
print "var1[0]: ", var1[0]
print "var2[1:5]: ", var2[1:5] |
var1[0]: H
var2[1:5]: ytho |
可以在“更新”现有的由(重新)分配一个变量赋值给另一个字符串的字符串。新的值可以与它以前的值或一个串完全不同。下面是一个简单的例子:
#!/usr/bin/python
var1 = 'Hello World!'
print "Updated String :- ", var1[:6]
+ 'Python' |
Updated String :- Hello Python |
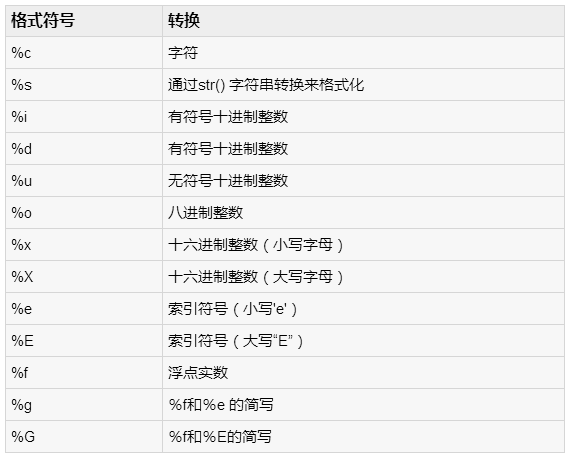
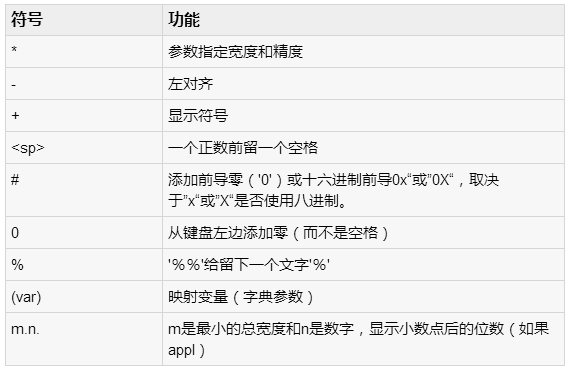
Python最酷的功能是字符串格式运算符%。这种操作是唯一的字符串,弥补了C语言的printf()系列函数功能。下面是一个简单的例子:
#!/usr/bin/python
print "My name is %s and weight is %d kg!"
% ('Zara', 21) |
My name is Zara and weight is 21 kg! |
#!/usr/bin/python
para_str = """this is a long string
that is made up of
several lines and non-printable characters such
as
TAB ( ) and they will show up that way when displayed.
NEWLINEs within the string, whether explicitly
given like
this within the brackets [
], or just a NEWLINE within
the variable assignment will also show up.
"""
print para_str; |
当执行上面的代码中,产生以下结果。请注意如何每一个特殊字符被转换到打印形式,一直到最后的换行符之间的字符串“up”结束闭三重引号。还要注意的是发生或者使用显式回车在一行或它的转义代码(
n)的尾部的换行:
this is a long string that is made up of
several lines and non-printable characters such as
TAB ( ) and they will show up that way when displayed.
NEWLINEs within the string, whether explicitly given like
this within the brackets [
], or just a NEWLINE within
the variable assignment will also show up. |
#!/usr/bin/python
print 'C:\nowhere' |
#!/usr/bin/python
print r'C:\nowhere' |
在Python普通字符串在内部存储为8位ASCII,而Unicode字符串被作为16位Unicode存储。这使得一组字符更加多样化,包括大多数语言在世界上的特殊字符。限制处理Unicode字符串,注意以下几点:
#!/usr/bin/python
print u'Hello, world!' |
| SN |
方法及描述 |
| 1 |
capitalize()
字符串的第一个字母大写 |
| 2 |
center(width, fillchar)
返回一个空格填充字符串为中心,以总宽度列的原始字符串 |
| 3 |
count(str, beg= 0,end=len(string))
开始索引beg和结束索引结束str多少次出现在字符串或字符串的子串 |
| 4 |
decode(encoding='UTF-8',errors='strict')
使用注册编码的编解码器的字符串进行解码。编码默认为默认的字符串编码。 |
| 5 |
encode(encoding='UTF-8',errors='strict')
返回编码字符串的字符串版本;对错误,默认是引发ValueError除非错误被赋予了“ignore”或“replace”。 |
| 6 |
endswith(suffix, beg=0, end=len(string))
判断字符串或字符串的一个子串(如果起始索引beg和给出end结束索引)与后缀结尾;如果是则返回true,否则为false, |
| 7 |
expandtabs(tabsize=8)
扩展选项卡中的字符串多个空格;如果未提供tab大小默认为每片8位 |
| 8 |
find(str, beg=0 end=len(string))
确定str开始索引beg和end索引并返回索引,如果找到出现在字符串或字符串的子串,否则返回-1 |
| 9 |
index(str, beg=0, end=len(string))
与find()一样,但会引发一个异常如果str没找到 |
| 10 |
isalnum()
如果string至少有1个字符,所有字符为字母数字则返回true,否则为false |
| 11 |
isalpha()
如果string至少有1个字符,所有字符都是字母,否则为false,则返回true |
| 12 |
isdigit()
如果字符串只包含数字则返回true,否则为false |
| 13 |
islower()
如果字符串至少有1个字符,所有字符是小写则返回true,否则为false |
| 14 |
isnumeric()
如果一个Unicode字符串只包含数字字符则返回true,否则为false。 |
| 15 |
isspace()
如果字符串只包含空格字符则返回true,否则返回false, |
| 16 |
istitle()
返回true如果字符串是正确的“首字母大写”,否则为false |
| 17 |
isupper()
返回true如果字符串至少有一个小写字符,所有字符符为大写字母,否则返回false。 |
| 18 |
join(seq)
合并(会连接)序列seq元素连接成一个字符串的字符串表示形式,用分隔符的字符串 |
| 19 |
len(string)
字返回字符串的长度 |
| 20 |
ljust(width[, fillchar])
返回一个空格填充字符串,原始字符串左对齐,以总宽列 |
| 21 |
lower()
将所有大写字母的字符串转化为小写 |
| 22 |
lstrip()
删除字符串中的所有前导空格 |
| 23 |
maketrans()
返回要用于转换功能的转换表 |
| 24 |
max(str)
从字符串str返回的最大字母字符 |
| 25 |
min(str)
从字符串str返回最小字母字符 |
| 26 |
replace(old, new [, max])
取代了旧的所有出现在字符串使用新的或max,如果给定max |
| 27 |
rfind(str, beg=0,end=len(string))
与find()一样,但反向搜索字符串 |
| 28 |
rindex( str, beg=0, end=len(string))
与index()一样,但反向搜索字符串 |
| 29 |
rjust(width,[, fillchar])
返回一个空格填充字符串右对齐,以原始字符串总宽度列。 |
| 30 |
rstrip()
删除字符串的所有行尾空白 |
| 31 |
split(str="", num=string.count(str))
根据分隔符str (如果没有提供空间)和子字符串返回分割字符串列表;分成最多num子字符串。 |
| 32 |
splitlines( num=string.count(' '))
Splits string at all (or num) NEWLINEs and returns
a list of each line with NEWLINEs removed |
| 33 |
startswith(str, beg=0,end=len(string))
判断字符串或字符串的一个子串(如果起始索引beg和end索引)开始字符串str;如果是则返回true,否则为false |
| 34 |
strip([chars])
在字符串执行两种lstrip()和rstrip() |
| 35 |
swapcase()
反转大小写,在字符串中的所有字母 |
| 36 |
title())
返回“标题大字”版本字符串,也就是所有的字以大写,其余为小写 |
| 37 |
translate(table, deletechars="")
根据转换表str(256字)转换字符串,删除那些del字符串 |
| 38 |
upper()
字符串小写转换为大写字母 |
| 39 |
zfill (width)
返回leftpadded零合共宽字符原字符串;用于数字zfill()保留给予任何迹象(减去一个零) |
| 40 |
isdecimal()
如果一个Unicode字符串只包含十进制字符则返回true,否则返回false |