| ����Ĺ���������˼,
������ Python ����¼��վ, ��Cookies��¼��¼��Ϣ, Ȼ��Ϳ���ץȡ��¼֮����ܿ�������Ϣ.
����������֪��������ʾ��. Ϊʲô��֪��? ������ѽ���, ���ǿ϶�����֪����ô����ô�ɹ�����վ��ȫ����������������.
֪�����ĵ�¼�Ƚϼ�, �����ʱ��û�ж��û������������, ȴ�ֲ�ʧ������, ��һ���������ҳ��ת��¼�Ĺ���.
���ò�˵һ��, Fiddler ��������� Tpircsboy �����ҵ�. ��л�����Ҵ�����ô����Ķ���.
��һ��: ʹ�� Fiddler �۲��������Ϊ
�ڿ��� Fiddler �����������������, ����֪��������ַ http://www.zhihu.com
�س��� Fiddler �о��ܿ���������������Ϣ. �����ѡ��һ�� 200 ����, ���ұߴ� Inspactors
��ͼ, �Ϸ��Ǹ������ӵ���������Ϣ, �·�����Ӧ������Ϣ.
���� Raw ��ǩ����ʾ���ĵ�ԭ��. �·�����Ӧ���ĺ��п�����û�о�����ѹ���߽����, ��������������м䲿λ��һ��С��ʾ,
���һ�¾��ܽ�����ʾ��ԭ����.
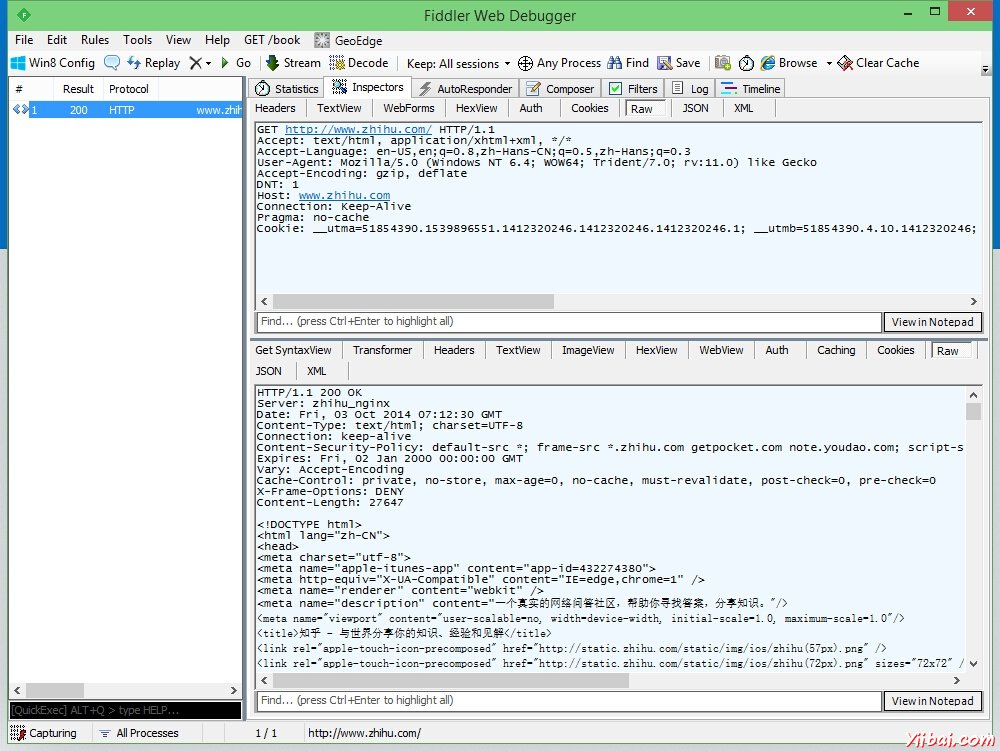
���������ͼ����δ��¼��ʱ����� http://www.zhihu.com �õ���. ���������������û����������½֪����,
�ٿ����������֪��������֮�䷢����ʲô.

�����½��, �ص� Fiddler ��鿴�³��ֵ�һ�� 200 ����. ���������Я�����ҵ��ʺ������֪��������������һ��
POST, ��������:
POST http://www.zhihu.com/login HTTP/1.1
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Accept: */*
X-Requested-With: XMLHttpRequest
Referer: http://www.zhihu.com/#signin
Accept-Language: en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/5.0 (Windows NT 6.4; WOW64; Trident/7.0; rv:11.0) like Gecko
Content-Length: 97
DNT: 1
Host: www.zhihu.com
Connection: Keep-Alive
Pragma: no-cache
Cookie: __utma=
51854390.1539896551.1412320246.1412320246.1412320246.1;
__utmb=51854390.6.10.1412320246; __utmc=
51854390; __utmz=51854390.1412320246.1.1.utmcsr=
(direct)|utmccn=(direct)|utmcmd=(none);
__utmv=51854390.000�C|3=entry_date=20141003=1
_xsrf=4b41f6c7a9668187ccd8a610065b9718&email=
�˴�Ϳ��%40gmail.com&password=�˴����ɼ�&rememberme=y |
��ͼ����:
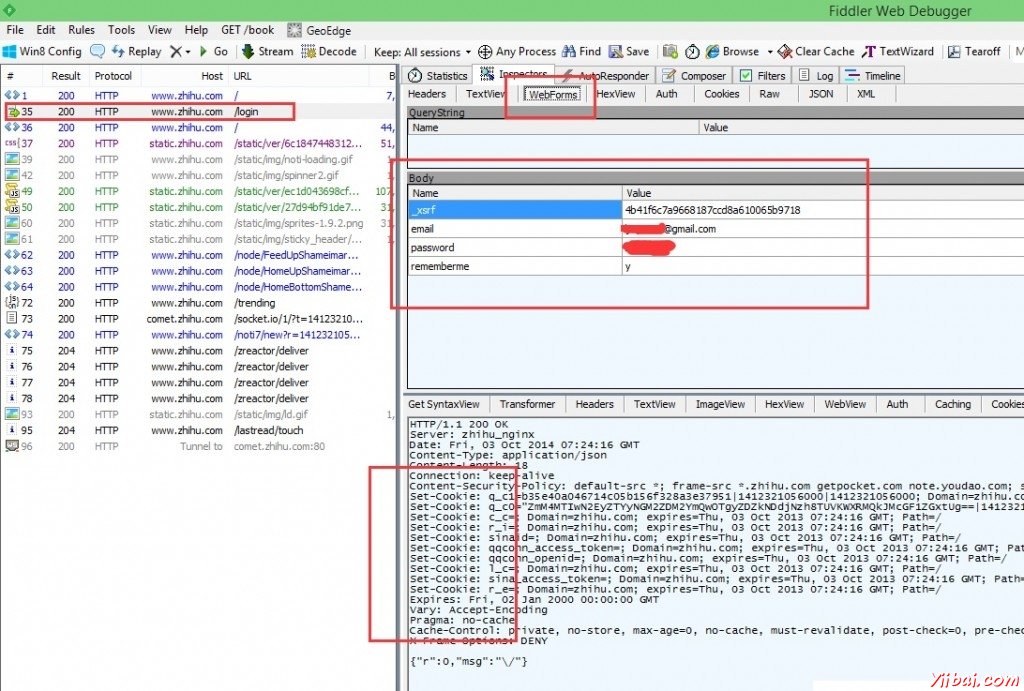
�ҵ�������� http://www.zhihu.com/login �����ַ(����һ��/login)
������һ��POST, ���ݶ��Ѿ��������г�����, ���û���, ������, ��һ������ס�ҡ��� yes, �������
WebForms ��ǩ�� Fiddler �ܹ��ȽϾ����������г��� POST ������. ���������� Python
Ҳ������ͬ�����ݾ��ܵ�¼��. �������������һ�� Name Ϊ _xsrf ����, ����ֵ�� 4b41f6c7a9668187ccd8a610065b9718.
����Ҫ�Ȼ�ȡ���ֵ, Ȼ����ܸ�����.
���������λ�ȡ����, ���Ǹո����ȷ����� http://www.zhihu.com/ �����ַ, ������ҳ,
Ȼ���¼��ʱ����ȴ�� http://www.zhihu.com/login �����ַ����Ϣ. ��������̽һ���˼άȥ˼���������,
�ͻᷢ�ֿ϶�����ҳ�� _xsrf ���ɷ�������, Ȼ�������ٰ���� _xsrf ���� /login
��� url. ����һ����������Ǿ�Ҫ�ӵ�һ�� GET �õ�����Ӧ��������ȥѰ�� _xsrf
��ͼ�·��ķ���˵��, ���Dz�����¼�ɹ���, ���ҷ��������������ǵ��������α����������� Cookies
��Ϣ. ��������ҲҪ�� Python ����Щ Cookies ��Ϣ��¼����.
���� Fiddler �Ĺ����ͻ���������!
�ڶ���: ��ѹ��
��дһ�� GET ����, ��֪����ҳ GET ����, Ȼ�� decode() һ�½���, �������.
��ϸһ��, ����֪�����������ǵ��Ǿ��� gzip ѹ��֮�������. �������Ǿ���Ҫ�ȶ����ݽ�ѹ. Python
���� gzip ��ѹ�ܷ���, ��Ϊ�����п������. ����Ƭ������:
import gzip
def ungzip(data):
try: # ���Խ�ѹ
print('���ڽ�ѹ.....')
data = gzip.decompress(data)
print('��ѹ���!')
except:
print('δ��ѹ��, �����ѹ')
return data |
ͨ�� opener.read() ��ȡ����������, ���� ungzip �Զ�������, ����һ�� decode()
�Ϳ��Եõ������� str ��
������: ʹ���������ʽ��ȡɳĮ֮��
_xsrf �������ֵ��ãã�ʵĻ�����ɳĮ֮��ָ����������ȷ����������¼֪��, ���� _xsrf ��νɳĮ֮��.
���û�� _xsrf, ���ǻ������û���������Ҳ����¼֪��(��û�Թ�, ��������ѧУ�Ľ���ϵͳȷʵ���)
��������˵, �����ڵ�һ�� GET ��ʱ����Դ���Ӧ�����е� HTML ��������õ����ɳĮ֮��. ���º���ʵ�����������,
���ص� str ���� _xsrf ��ֵ.
import re
def getXSRF(data):
cer = re.compile('name=\"_xsrf\" value=\"(.*)\"', flags = 0)
strlist = cer.findall(data)
return strlist[0] |
���IJ�: ���� POST !!
���� _xsrf, id, password ����, ���ǿ��Է��� POST ��. ��� POST
һ�������ȥ, ���Ǿ͵�½���˷�����, �������ͻᷢ������ Cookies. �������� Cookies
�Ǹ��鷳������, ���� Python �� http.cookiejar ��������Ǻܷ���Ľ������, ֻҪ�ڴ���
opener ��ʱ��һ�� HTTPCookieProcessor �Ž�ȥ, Cookies ������Ͳ������ǹ���.
����Ĵ�����������һ��.
import http.cookiejar
import urllib.request
def getOpener(head):
# deal with the Cookies
cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener |
getOpener ��������һ�� head ����, ���������һ���ֵ�. �������ֵ�ת����Ԫ�鼯��, �Ž�
opener. �������ǽ�������� opener ����������:
�Զ�����ʹ�� opener ������������ Cookies
�Զ��ڷ����� GET ���� POST �����м����Զ���� Header
���岿: ��ʽ����
��ʽ���л���һ���, ����Ҫ��Ҫ POST ������Ū�� opener.open() ֧�ֵĸ�ʽ. ���Ի�Ҫ
urllib.parse ����� urlencode() ����. ����������� �ֵ� ���� Ԫ�鼯��
���͵�����ת���� & ���ӵ� str.
str ������, ��Ҫͨ�� encode() ������, ���ܵ��� opener.open() ���� urlopen()
�� POST ���ݲ�����ʹ��. ��������:
url = 'http://www.zhihu.com/'
opener = getOpener(header)
op = opener.open(url)
data = op.read()
data = ungzip(data) # ��ѹ
_xsrf = getXSRF(data.decode())
url += 'login'
id = '���������֪���ʺ�'
password = '���������֪������'
postDict = {
'_xsrf':_xsrf,
'email': id,
'password': password,
'rememberme': 'y'
}
postData = urllib.parse.urlencode(postDict).encode()
op = opener.open(url, postData)
data = op.read()
data = ungzip(data)
print(data.decode()) # ����Ը������ϲ��������ץȡ������������! |
�������к�, ���Ƿ����Լ���ע���˵Ķ�̬(��ʾ�ڵ�½���֪����ҳ����Щ), ����ץȡ������. ��һ����һ��ͳ�Ʒ�����,
�����Զ�������, �������ݷּ��Զ�������, ������.
������������:
import gzip
import re
import http.cookiejar
import urllib.request
import urllib.parse
def ungzip(data):
try: # ���Խ�ѹ
print('���ڽ�ѹ.....')
data = gzip.decompress(data)
print('��ѹ���!')
except:
print('δ��ѹ��, �����ѹ')
return data
def getXSRF(data):
cer = re.compile('name=\"_xsrf\" value=\"(.*)\"', flags = 0)
strlist = cer.findall(data)
return strlist[0]
def getOpener(head):
# deal with the Cookies
cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
header = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Accept-Encoding': 'gzip, deflate',
'Host': 'www.zhihu.com',
'DNT': '1'
}
url = 'http://www.zhihu.com/'
opener = getOpener(header)
op = opener.open(url)
data = op.read()
data = ungzip(data) # ��ѹ
_xsrf = getXSRF(data.decode())
url += 'login'
id = '���������֪���ʺ�'
password = '���������֪������'
postDict = {
'_xsrf':_xsrf,
'email': id,
'password': password,
'rememberme': 'y'
}
postData = urllib.parse.urlencode(postDict).encode()
op = opener.open(url, postData)
data = op.read()
data = ungzip(data)
print(data.decode()) |
|









