AUTOSARзҡ„NvM Blockжңүдёүз§ҚNativeгҖҒRedundantе’ҢDataSetпјҢз”Ёеҫ—жңҖеӨҡзҡ„жҳҜNativeпјҢдҪҶдҪ зҹҘйҒ“е…¶д»–дёӨз§ҚжҳҜе№Ід»Җд№Ҳзҡ„еҗ—пјҹ
AUTOSAR NVMпјҲNon-Volatile MemoryпјүжҳҜAUTOSARж ҮеҮҶдёӯе®ҡд№үзҡ„дёҖз§Қз”ЁдәҺеӯҳеӮЁйқһжҳ“еӨұжҖ§ж•°жҚ®зҡ„жңәеҲ¶гҖӮеңЁAUTOSAR NVMдёӯпјҢж•°жҚ®иў«еӯҳеӮЁеңЁдёҖдёӘжҲ–еӨҡдёӘNVMеқ—дёӯгҖӮжҜҸдёӘNVMеқ—з”ұдёҖдёӘжҲ–еӨҡдёӘNVMж•°жҚ®йӣҶз»„жҲҗпјҢеҸҜд»ҘеӯҳеӮЁдёҚеҗҢзұ»еһӢзҡ„ж•°жҚ®гҖӮ
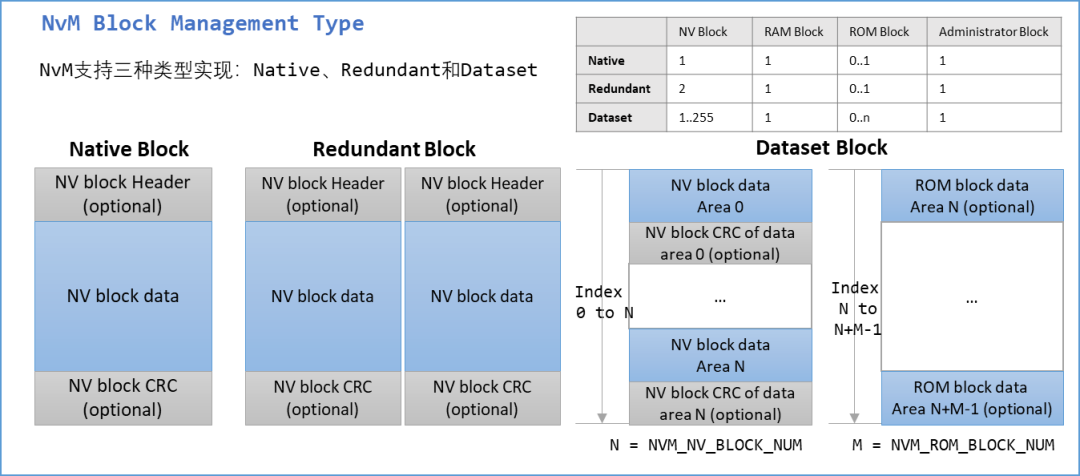
еңЁAUTOSAR NVMеқ—дёӯзҡ„дёүз§Қзұ»еһӢпјҢе®ғ们д№Ӣй—ҙзҡ„еҢәеҲ«еҰӮдёӢпјҡ
1.Native
Nativeж•°жҚ®жҳҜNVMеқ—дёӯеӯҳеӮЁзҡ„еҺҹе§Ӣж•°жҚ®пјҢжҳҜеә”з”ЁзЁӢеәҸйңҖиҰҒиҜ»еҶҷзҡ„ж•°жҚ®гҖӮNativeж•°жҚ®еҸӘеңЁNVMеқ—дёӯеӯҳеӮЁдёҖд»ҪпјҢеҰӮжһңж•°жҚ®жҚҹеқҸжҲ–дёўеӨұпјҢе°Ҷж— жі•жҒўеӨҚгҖӮеӣ жӯӨпјҢеңЁеҶҷе…ҘNativeж•°жҚ®ж—¶пјҢйңҖиҰҒзЎ®дҝқж•°жҚ®зҡ„еҸҜйқ жҖ§е’ҢдёҖиҮҙжҖ§гҖӮ
дёҫдҫӢиҜҙжҳҺпјҡжұҹж№–дёӯзҡ„гҖҠд№қйҳізҘһеҠҹгҖӢеҸӘжңүдёҖд»ҪпјҢеј„дёўдәҶе°ұдёўдәҶгҖӮ

2.Redundant
Redundantж•°жҚ®жҳҜдёәдәҶеўһеҠ ж•°жҚ®зҡ„еҸҜйқ жҖ§иҖҢеӯҳеӮЁеңЁNVMеқ—дёӯзҡ„еӨҮд»Ҫж•°жҚ®гҖӮдёҺNativeж•°жҚ®дёҚеҗҢпјҢRedundantж•°жҚ®йҖҡеёёеӯҳеӮЁеңЁNVMеқ—дёӯзҡ„дёҚеҗҢдҪҚзҪ®пјҢд»ҘеўһеҠ ж•°жҚ®зҡ„еҶ—дҪҷеәҰгҖӮеҰӮжһңNativeж•°жҚ®жҚҹеқҸжҲ–дёўеӨұпјҢеҸҜд»ҘдҪҝз”ЁRedundantж•°жҚ®иҝӣиЎҢжҒўеӨҚгҖӮеңЁеҶҷе…ҘRedundantж•°жҚ®ж—¶пјҢйңҖиҰҒзЎ®дҝқж•°жҚ®зҡ„еҸҜйқ жҖ§е’ҢдёҖиҮҙжҖ§пјҢд»ҘзЎ®дҝқRedundantж•°жҚ®еҸҜд»ҘжҲҗеҠҹең°з”ЁдәҺж•°жҚ®жҒўеӨҚгҖӮ
дёҫдҫӢиҜҙжҳҺпјҡжұҹж№–дёӯпјҢеҰӮжһңдҪ е·§еҗҲеҫ—еҲ°дәҶдёҖд»ҪгҖҠи‘өиҠұе®қе…ёгҖӢпјҢдҪ д№ҹеҫҲжё…жҘҡиҝҷзҺ©ж„Ҹзҡ„вҖңйӯ…еҠӣвҖқпјҢдҪ дёҚжғіжӢҘжңүе®ғд№ҹдёҚеёҢжңӣе®ғеӨұдј пјҢдәҺжҳҜеҒ·еҒ·жҠ„дәҶдёҖд»ҪпјҢжҠҠеҺҹ件жү”еҲ°жұҹж№–дёӯпјҢзҲұе’Ӣе’Ӣең°гҖӮеҰӮжһңжұҹж№–дёӯзҡ„еҺҹ件丢дәҶпјҢйӮЈдҪ еҸҜд»ҘеҒ·еҒ·жӢҝеҮәдҪ зҡ„жүӢжҠ„зЁҝж…ўж…ўз ”з©¶пјҢе’іе’і~~

3.DataSet
DataSetж•°жҚ®жҳҜAUTOSAR NVMдёӯзҡ„дёҖдёӘзү№ж®Ҡж•°жҚ®зұ»еһӢпјҢе®ғжҳҜдёҖз»„ж•°жҚ®зҡ„йӣҶеҗҲгҖӮDataSetж•°жҚ®йҖҡеёёз”ЁдәҺеӯҳеӮЁеә”з”ЁзЁӢеәҸзҡ„й…ҚзҪ®ж•°жҚ®жҲ–зҠ¶жҖҒж•°жҚ®пјҢдҫӢеҰӮиҪҰиҫҶеҸӮж•°гҖҒж•…йҡңз ҒзӯүгҖӮдёҺNativeе’ҢRedundantж•°жҚ®дёҚеҗҢпјҢDataSetж•°жҚ®еҸҜд»ҘеңЁеә”з”ЁзЁӢеәҸиҝҗиЎҢжңҹй—ҙиҝӣиЎҢиҜ»еҶҷпјҢ并且еҸҜд»ҘдҪҝз”ЁAUTOSARй…ҚзҪ®е·Ҙе…·иҝӣиЎҢй…ҚзҪ®е’Ңз®ЎзҗҶгҖӮ
DataSetж•°жҚ®з”ұдёҖдёӘжҲ–еӨҡдёӘDataBlockз»„жҲҗпјҢжҜҸдёӘDataBlockз”ұдёҖдёӘжҲ–еӨҡдёӘDataElementз»„жҲҗгҖӮеңЁеҶҷе…ҘDataSetж•°жҚ®ж—¶пјҢйңҖиҰҒзЎ®дҝқж•°жҚ®зҡ„еҸҜйқ жҖ§е’ҢдёҖиҮҙжҖ§пјҢ并且йңҖиҰҒиҖғиҷ‘еҲ°ж•°жҚ®зҡ„зүҲжң¬з®ЎзҗҶе’Ңж•°жҚ®жӣҙж–°зӯүй—®йўҳгҖӮ
дёҫдҫӢиҜҙжҳҺпјҡжұҹж№–дёӯзҡ„гҖҠйҷҚйҫҷеҚҒе…«жҺҢгҖӢжңүеҘҪеӨҡдёӘзүҲжң¬пјҢдҫӢеҰӮжңүжҙӘдёғе…¬зүҲгҖҒйғӯйқ–зүҲе’Ңд№”еі°зүҲпјҢжҜҸдёӘзүҲжң¬йғҪжңүзӮ№дёҚдёҖж ·гҖӮ

жҖ»д№ӢпјҢеңЁAUTOSAR NVMдёӯпјҢNativeж•°жҚ®жҳҜеә”з”ЁзЁӢеәҸйңҖиҰҒиҜ»еҶҷзҡ„еҺҹе§Ӣж•°жҚ®пјҢRedundantж•°жҚ®жҳҜдёәдәҶеўһеҠ ж•°жҚ®зҡ„еҸҜйқ жҖ§иҖҢеӯҳеӮЁзҡ„еӨҮд»Ҫж•°жҚ®пјҢDataSetж•°жҚ®жҳҜдёҖз»„ж•°жҚ®зҡ„йӣҶеҗҲпјҢйҖҡеёёз”ЁдәҺеӯҳеӮЁй…ҚзҪ®ж•°жҚ®жҲ–зҠ¶жҖҒж•°жҚ®пјҢдёҖиҲ¬еҸҜд»ҘжҳҜиҪҰеҺӮдёҚеҗҢиҪҰеһӢзҡ„й…ҚзҪ®ж•°жҚ®гҖӮ
зҗҶи®әжҳҜиҝҷдёӘж ·еӯҗпјҢиҜқд№ҹжҳҜиҝҷд№ҲиҜҙпјҢдҪҶжҖ»еҫ—жӢҝеҮәжқҘйҒӣдёҖйҒӣпјҢзңӢзңӢе®һйҷ…зҡ„ж ·еӯҗгҖӮ
дәҺжҳҜд№ҺпјҢдёҠд»Јз ҒгҖҒж”№й…ҚзҪ®пјҢзӣҙжҺҘиҝҗиЎҢиҜ•иҜ•ж•Ҳжһңпјҡ
д»ҘдёӢе·ҘзЁӢйӘҢиҜҒиҝҳжҳҜеҹәдәҺгҖҠ AUTOSAR NvMжЁЎеқ—й…ҚзҪ®иҜҰи§Ј гҖӢжЎҲдҫӢжқҘдҝ®ж”№гҖӮ
1.Native
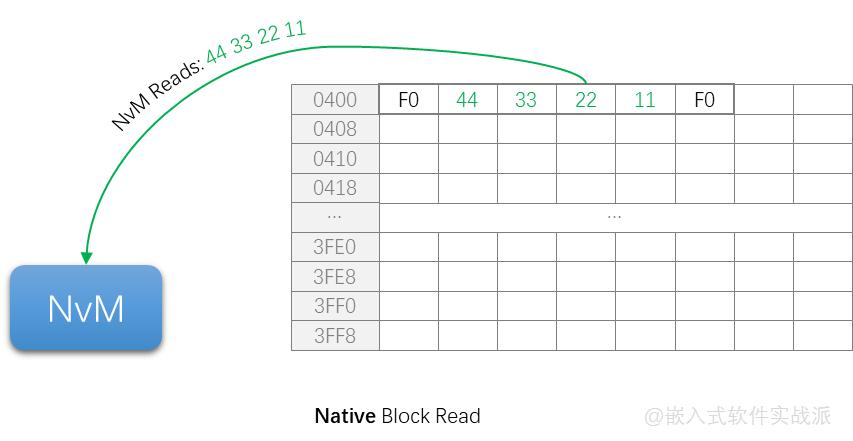
иҝҷдёӘеңЁеҺҹжқҘж•ҷзЁӢжңүеұ•зӨәдәҶпјҢд№ҹжҳҜз”Ёеҫ—жҜ”иҫғеӨҡдёҖз§ҚпјҢе°ұй…ҚзҪ®жҲҗNativeе°ұеҘҪдәҶпјҢеңЁEEPROMжҲ–FLASHдёӯеӯҳеӮЁзҡ„ж•°жҚ®еҸӘжңүдёҖд»ҪгҖӮ
е®ғзҡ„иҜ»еҶҷзӨәж„ҸеӣҫжҳҜиҝҷж ·зҡ„пјҡ

2.Redundant
Redundantе°ұжҳҜеҶ—дҪҷгҖҒйҮҚеӨҚзҡ„ж„ҸжҖқпјҢжңҖзӣҙи§Ӯзҡ„зҗҶи§Је°ұжҳҜжңүеӨҡдёҖдёӘеӨҮд»ҪBlockгҖӮиҝҷж ·еҸҜд»Ҙи®©ж•°жҚ®жӣҙеҠ еҸҜйқ гҖҒе®№й”ҷжҖ§жӣҙеҘҪпјҢеҸҜз”ЁжҖ§д№ҹжӣҙеҘҪгҖӮ
жіЁж„ҸпјҡеҸӘиҰҒж•°жҚ®дәҶпјҢеӨҮд»ҪжҜҸж¬ЎйғҪиҰҒйҮҚж–°еҗҢжӯҘзҡ„гҖӮ

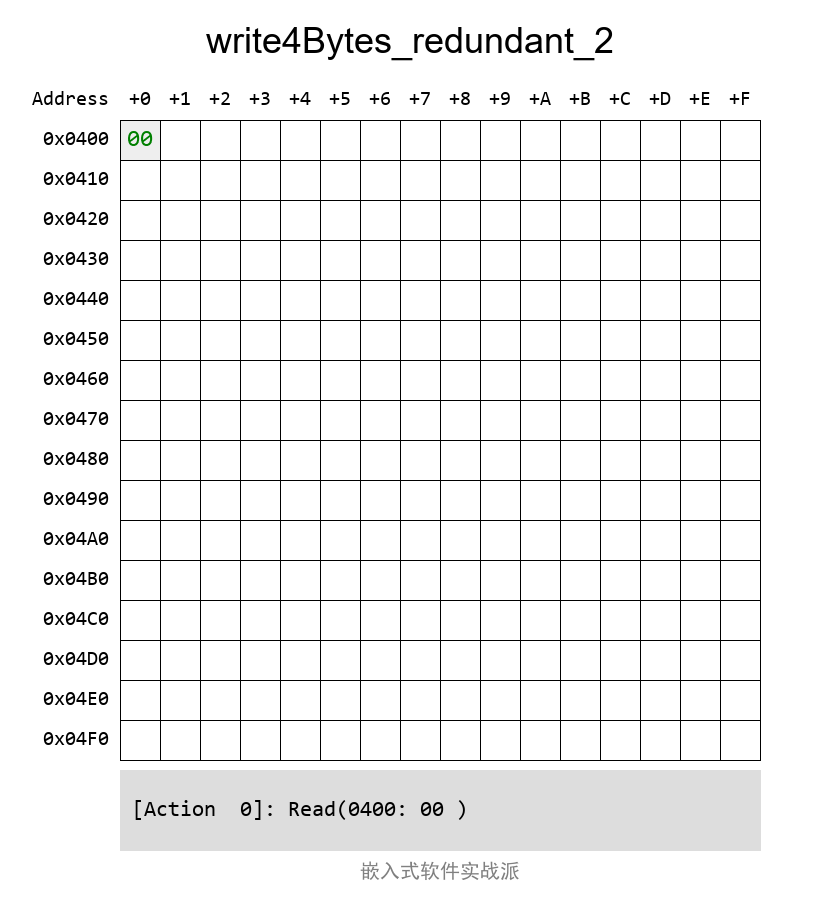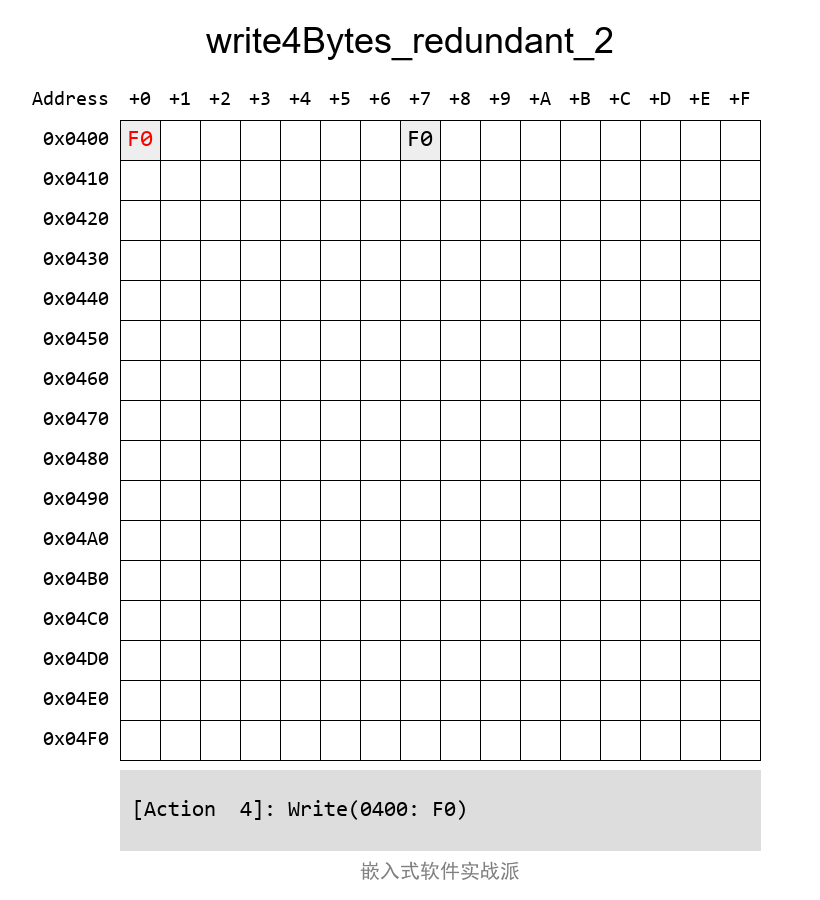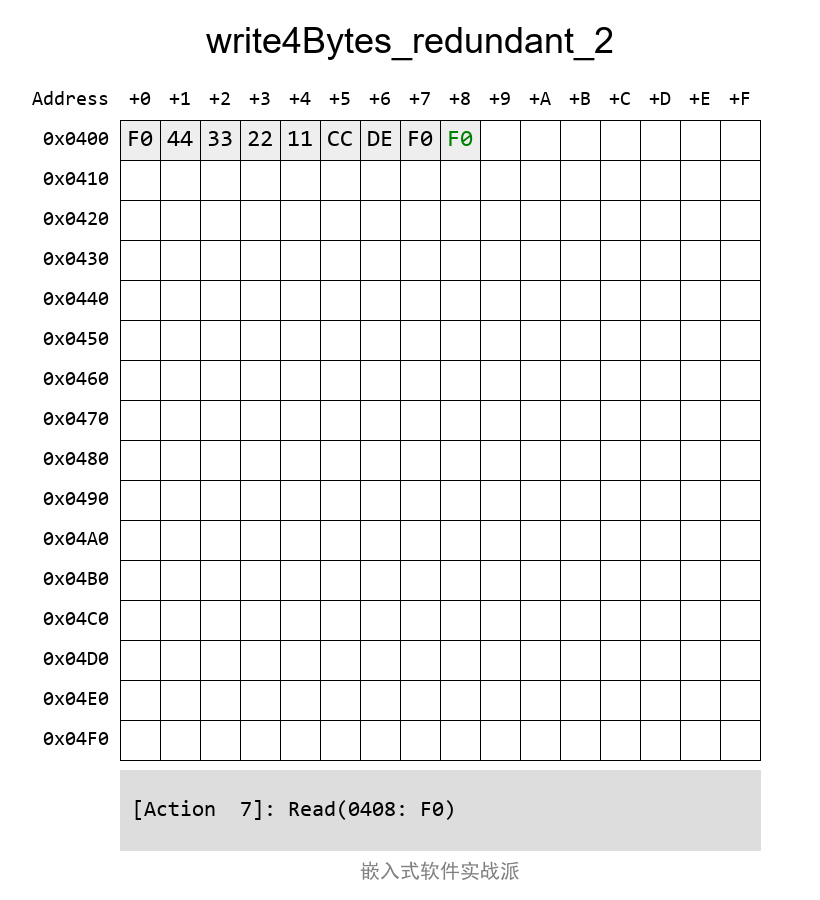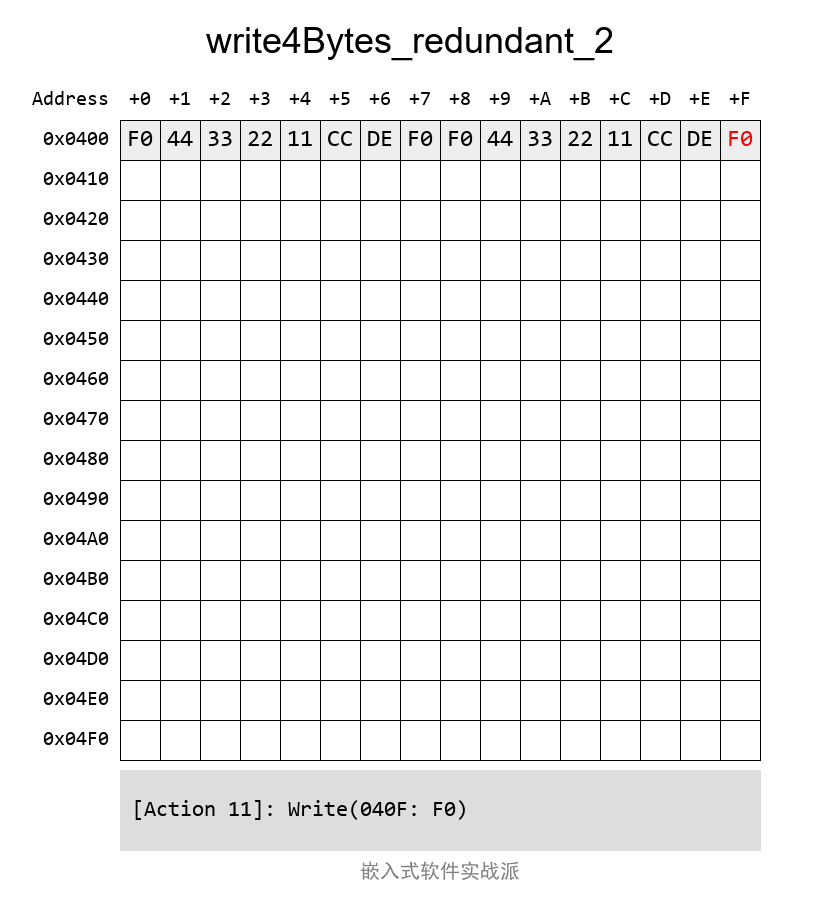
е®һйҷ…жЎҲдҫӢдёӯзҡ„еҶҷе…ҘиҝҮзЁӢеҠЁеӣҫжҳҜиҝҷж ·зҡ„пјҡ
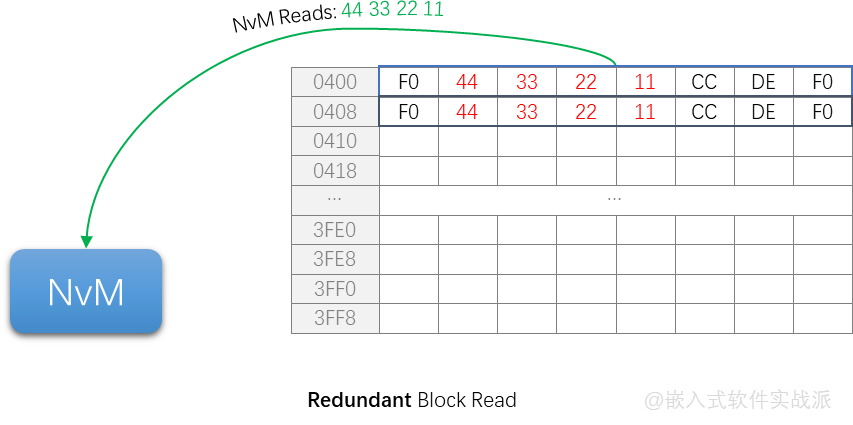
еңЁиҜ»зҡ„ж—¶еҖҷпјҢиҜ»еҲ°е…¶дёӯдёҖд»ҪжҳҜжӯЈзЎ®зҡ„е°ұOKдәҶ
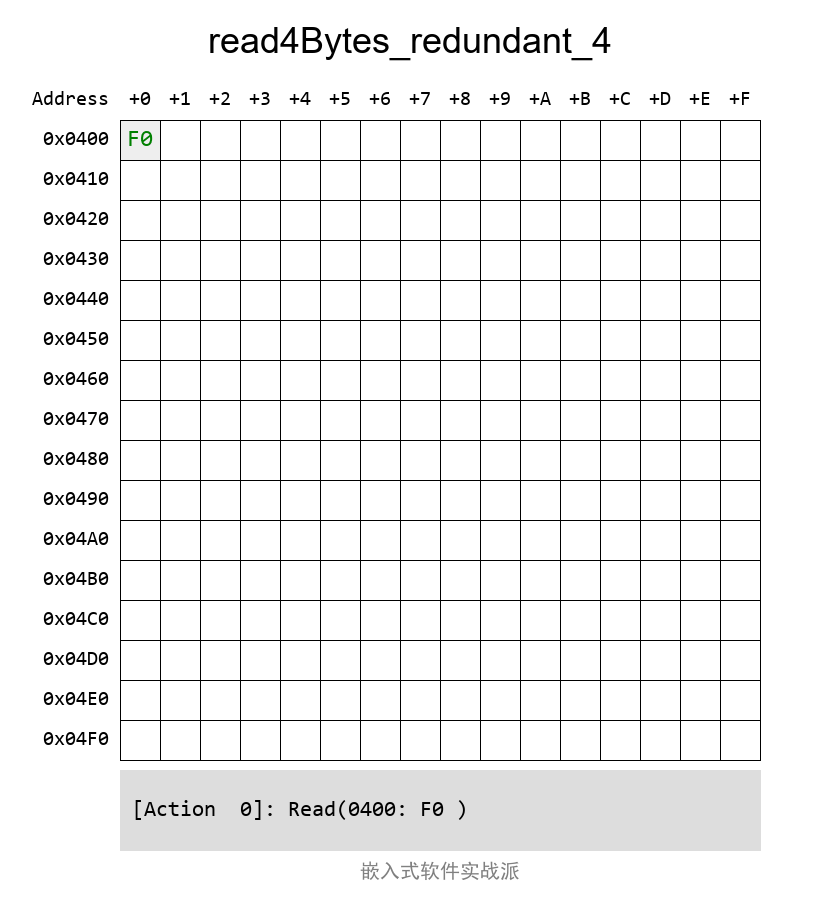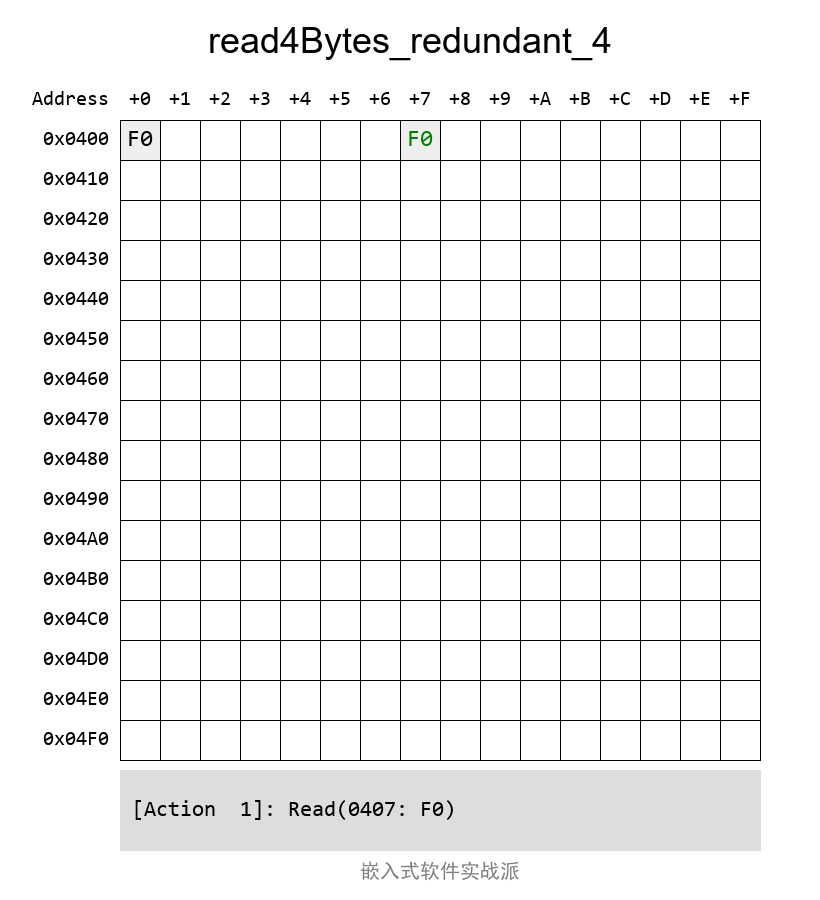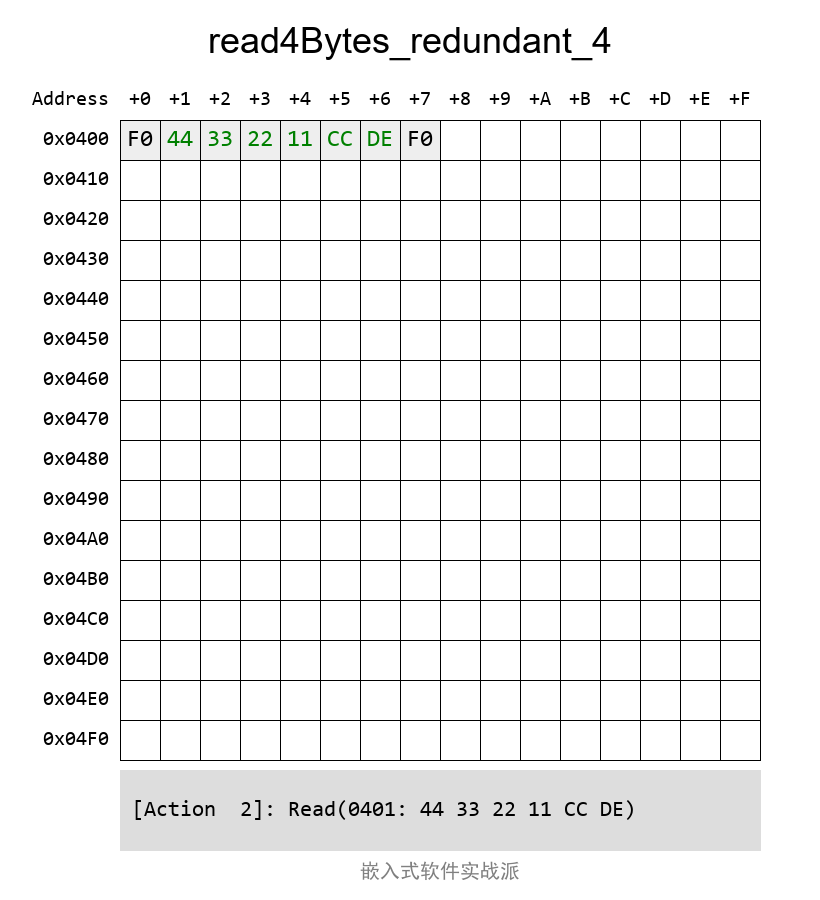
зңҹе®һзҡ„иҜ»еҸ–иҝҮзЁӢд№ҹеҫҲз®ҖеҚ•пјҡ
дҪҶжҳҜпјҢеҰӮжһңд»Һ第дёҖдёӘBlockиҜ»еҸ–зҡ„ж•°жҚ®жҳҜй”ҷиҜҜзҡ„пјҲдҫӢеҰӮCRCж ЎйӘҢдёҚжӯЈзЎ®пјүпјҢйӮЈд№ҲпјҢе®ғе°ұдјҡд»ҺеӨҮд»ҪBlockеҺ»иҜ»еҸ–ж•°жҚ®гҖӮд»ҘдёӢпјҢжҲ‘ж•…ж„Ҹе°ҶCRCйғЁеҲҶж”№жҲҗеҲ«зҡ„й”ҷиҜҜеҖјпјҢе…¶иҜ»еҮәжқҘеҗҺдјҡж ЎйӘҢCRCпјҢеҸ‘зҺ°й”ҷзҡ„пјҢеҶҚе°қиҜ•иҜ»еҸ–еӨҮд»ҪеҢәеҹҹзҡ„ж•°жҚ®пјҡ
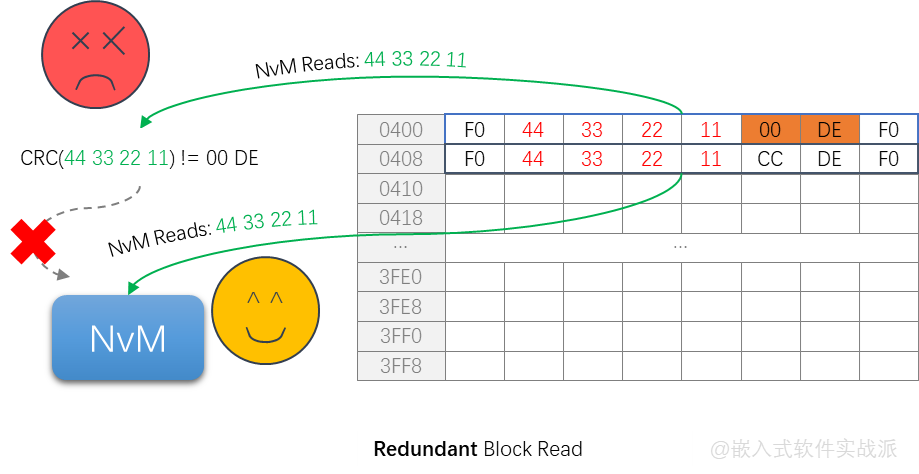
йӮЈд№Ҳе®ғзҡ„иҜ»еҸ–иҝҮзЁӢжҳҜжҖҺж ·зҡ„е‘ўпјҹзңӢеҠЁеӣҫпјҡ
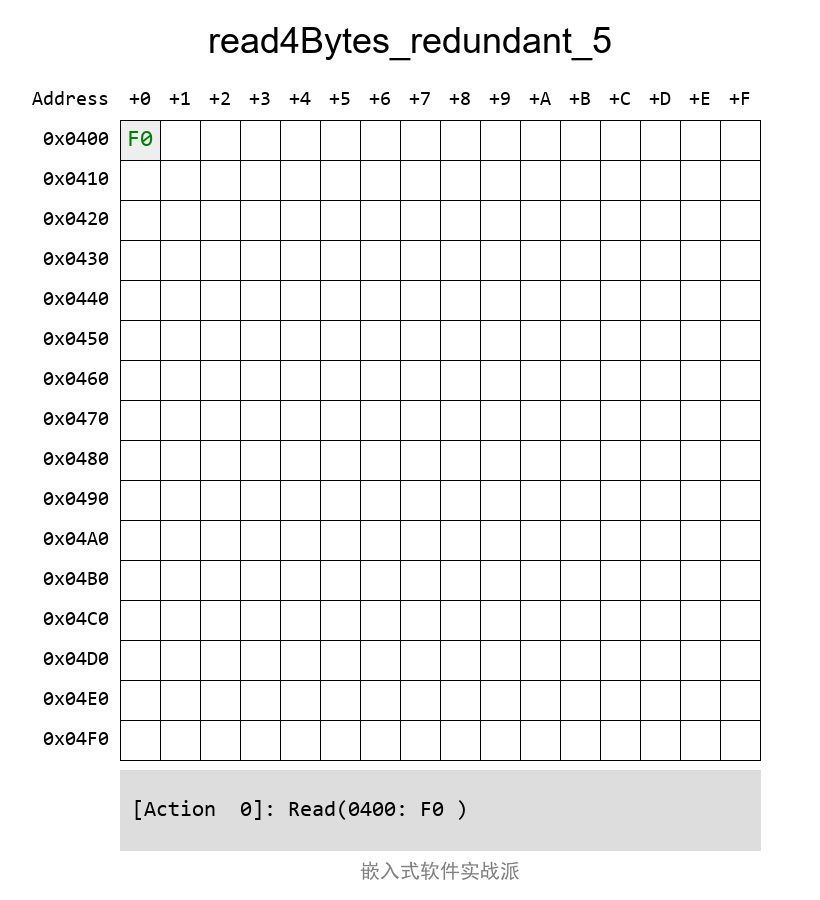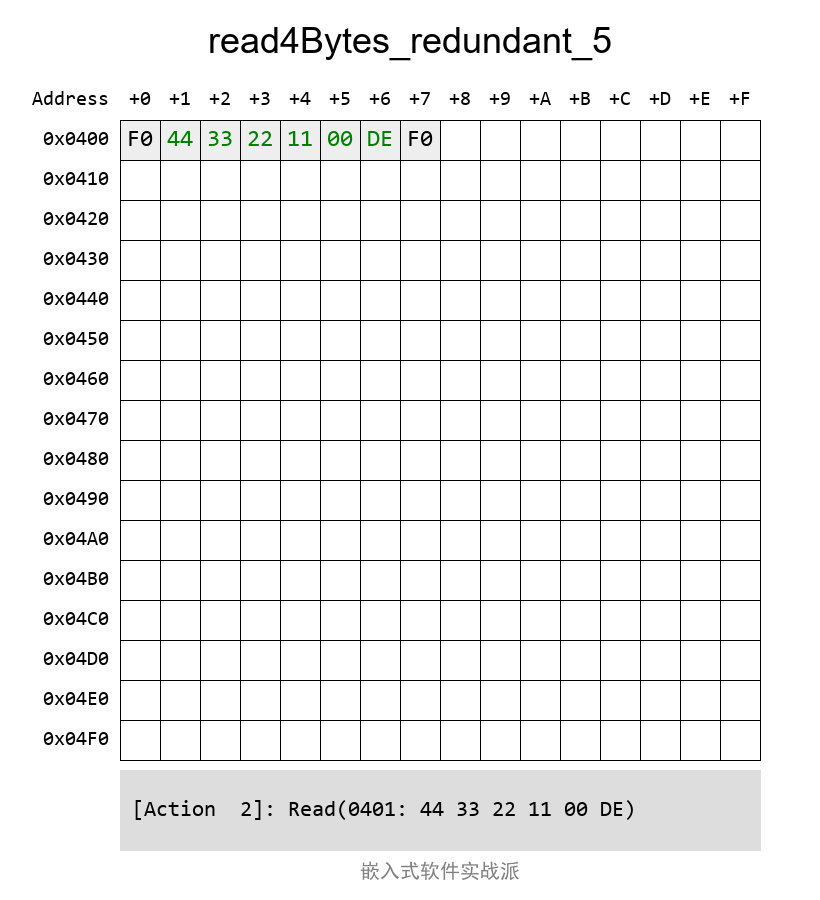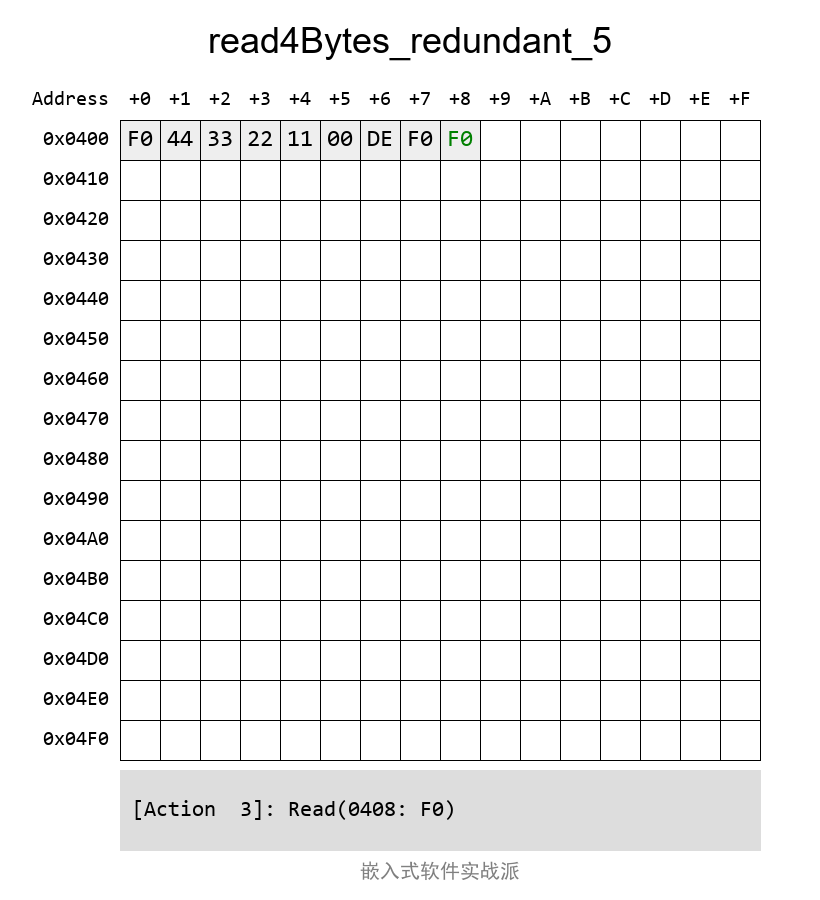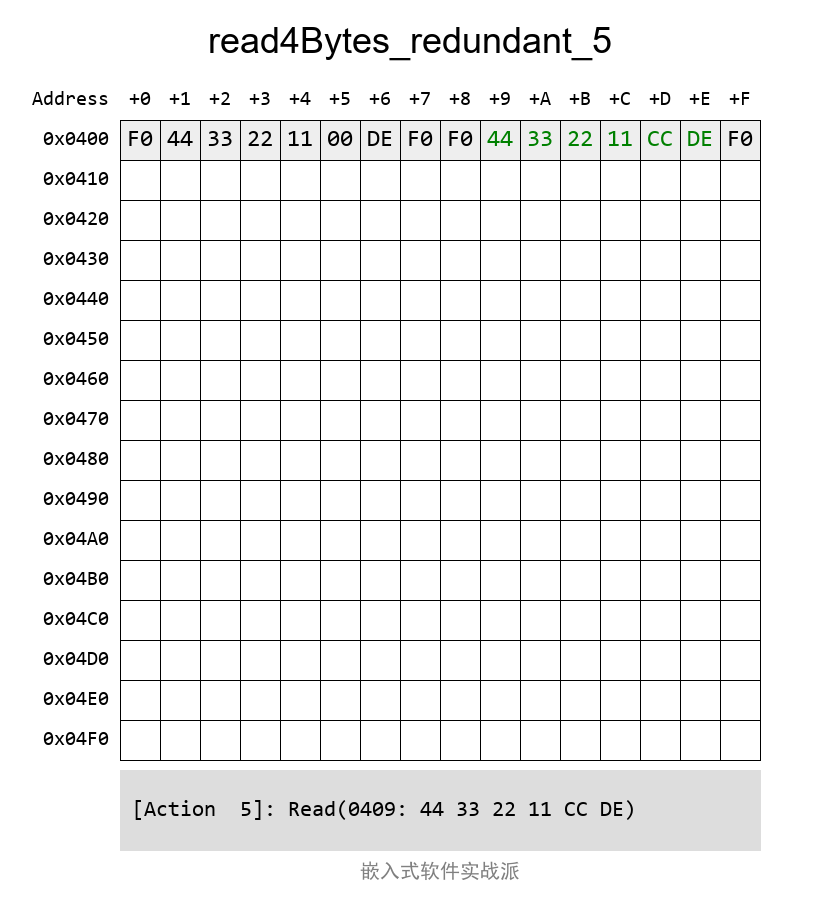
иҝҷж ·зңӢжқҘпјҢиҝҷдёӘйқһеёёйҖӮеҗҲз”ЁдәҺеӯҳеӮЁйқһеёёйҮҚиҰҒзҡ„ж•°жҚ®пјҢдҫӢеҰӮз”ЁдәҺеҠҹиғҪе®үе…ЁеңәеҗҲгҖӮ
3.DataSet
DataSetж•°жҚ®жҳҜдёҖз»„ж•°жҚ®пјҢиҝҷз»„ж•°жҚ®йҮҢйқўжңүеҫҲеӨҡд»Ҫзӣёдә’зӢ¬з«Ӣзҡ„ж•°жҚ®гҖӮе®ғ并дёҚеғҸRedundantйӮЈж ·пјҢиҝҷдәӣж•°жҚ®еҚідҪҝдјҡжңүдәӣзӣёдјјжҖ§пјҢдҪҶйғҪжҳҜдёҚдёҖж ·зҡ„пјҢж”№еҠЁе…¶дёӯдёҖд»ҪдёҚдјҡеҪұе“Қе…¶д»–зҡ„гҖӮ
DataSetзҡ„иҜ»еҶҷе…¶е®һи·ҹNativeзҡ„еҹәжң¬дёҖж ·пјҢеҸӘжҳҜеңЁж“ҚдҪңд№ӢеүҚйңҖиҰҒи°ғз”Ё NvM_SetDataIndex еҮҪж•°жқҘжҢҮе®ҡиҰҒж“ҚдҪңе“ӘдёҖдёӘDataSetж•°жҚ®еқ—гҖӮе®ғзҡ„еҸӮж•°е®ҡд№үжҳҜиҝҷж ·зҡ„пјҡ
Std_ReturnType NvM_SetDataIndex(NvM_BlockIdType BlockId, uint8 DataIndex)
еҰӮжһңдёҚи°ғз”ЁиҝҷдёӘ NvM_SetDataIndex еҮҪж•°пјҢй»ҳи®Өжғ…еҶөдёӢпјҢжҳҜж“ҚдҪңжңҖеүҚзҡ„йӮЈдёӘж•°жҚ®еқ—пјҢи·ҹNativeзҡ„иЎЁзҺ°дёҖиҮҙпјҡ
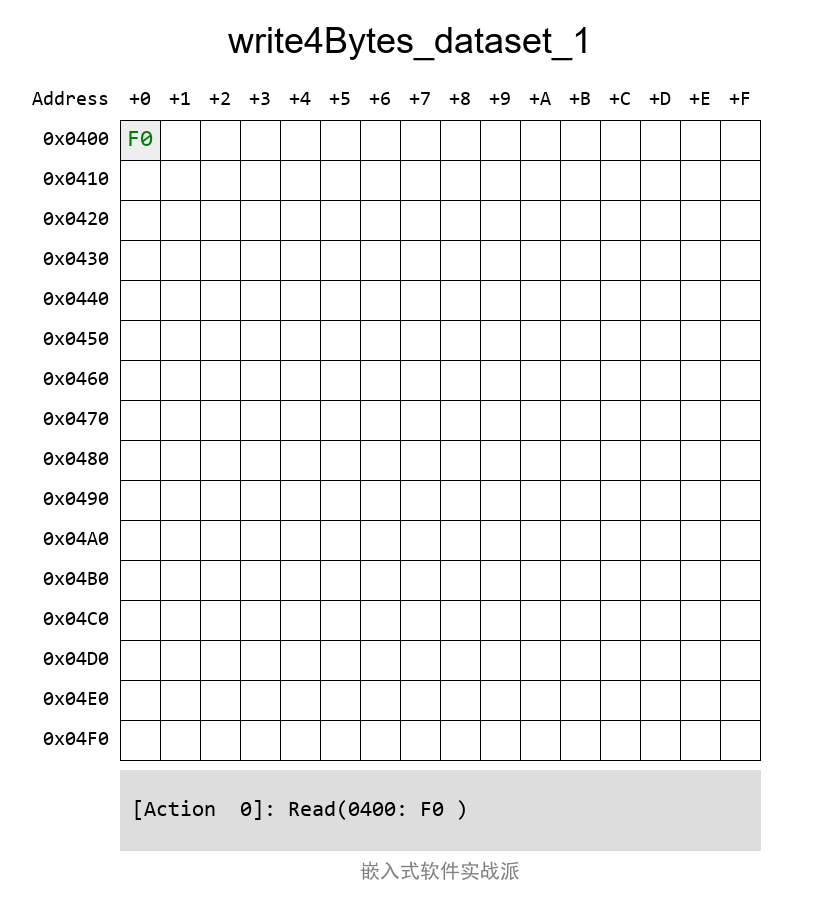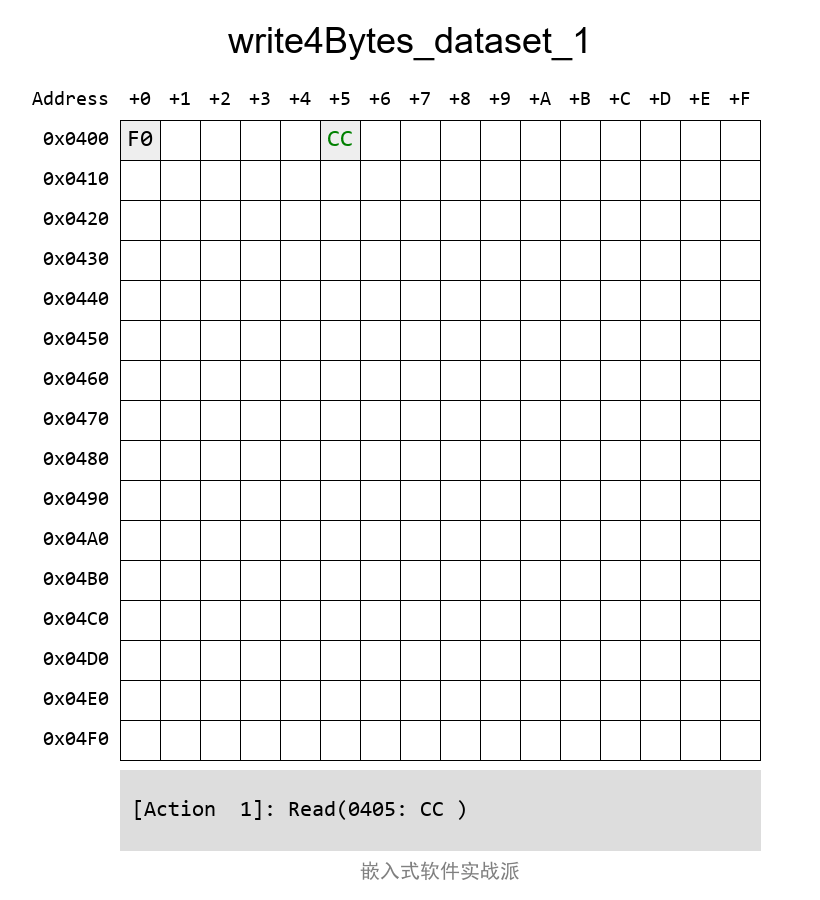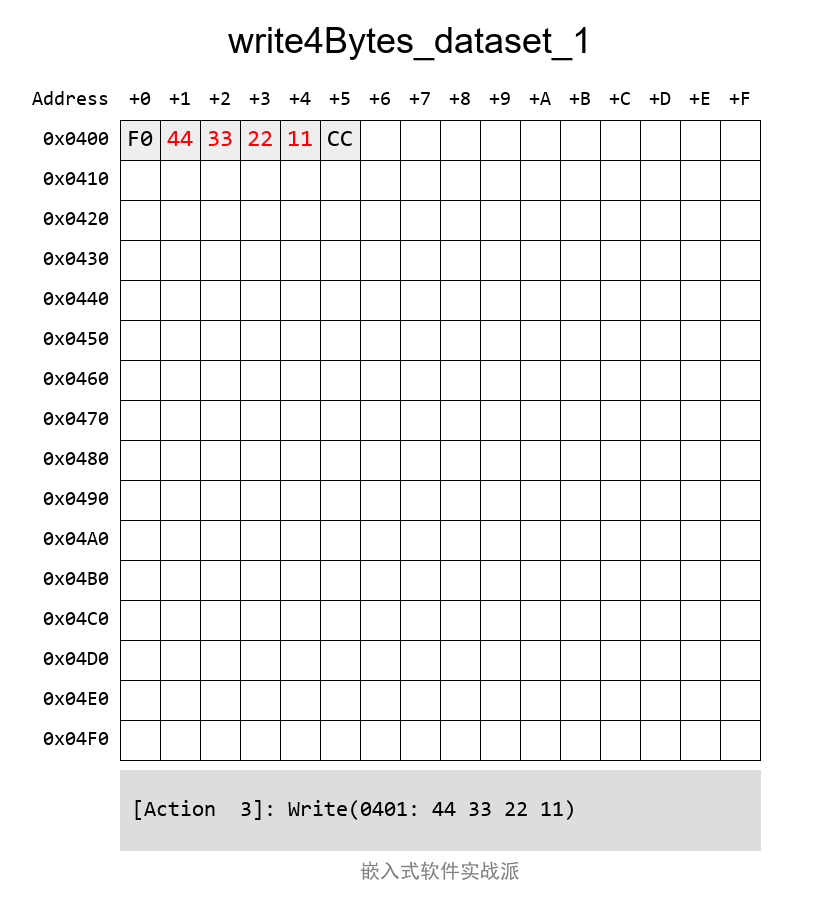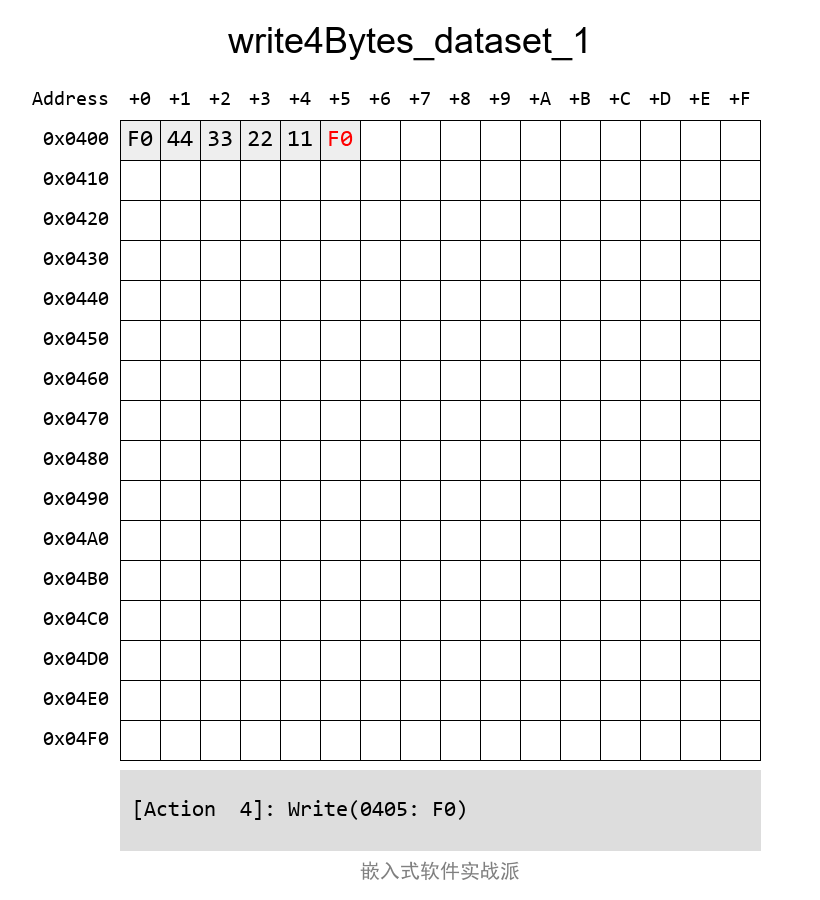
еҰӮжһңж“ҚдҪң第дәҢеқ—е°ұжҳҜиҝҷж ·пјҲиө·е§Ӣең°еқҖжҳҜ第дёҖеқ—зҡ„еҗҺйқўпјҢзҙ§жҢЁзқҖзҡ„пјүпјҡ

д»ҘдёҠе°ұжҳҜNvM Blockзҡ„NativeгҖҒRedundantе’ҢDataSetзҡ„еҢәеҲ«дәҶгҖӮ
|








