| JMeter函数是一些能够转化在测试树中取样器或者其他配置元件的域的特殊值。一个函数的调用就像这样:${_functionName(var1,var2,var3)},-functionName匹配函数名,圆括号内设置函数的参数,例如${_time(YMD)}实际参数因函数而不同。不需要参数的函数使圆括号内为空,例如${_theadNum}.
Jmeter函数有两种函数:自定义静态值(或者变量)和内置函数。
自定义静态值允许当一个测试树编译并且提交运行时自定义变量被它们的静态值代替。这个替代在测试运行开始时发生一次。这可以用来替换所有的HTTP请求中的DOMAIN域。
内置函数允许写进任何非控制器测试组件的任何域,这包括取样器,定时器,监听器,修改器,断言,前置处理器,后置处理器和配置元件。
注意:如果使用和内置函数同样的名字定义一个自定义变量,你的自定义静态变量会覆盖内置函数,但不建议名字相同。
函数列表:
regexFunction -正则表达式函数
counter
threadNum -得到线程数
intSum -添加变量
StringFromFile -从文件读取一行
machineName -得到本地计算机名
JavaScript(Apache Rhino)
random number
CSVRead -从CSV文件读取一个属性
P -读取一个属性
setProperty -设置一个属性
log -记录一个日志
logn -记录一个日志
BeanShell -运行BeanShell
split -分隔一个字符串变量
XPATH -使用一个xpath表达式
time -返回一些格式的当前时间
jexl -执行一个jexl表达式
以下讲解一些内置函数的用法:
一、_csvRead 函数
_cvsRead函数是从外部读取参数,csvRead函数可以从一个文件中读取多个参数。
步骤:
1、先新建一个文件,例如c.txt,里面的数据存放为
web@qq.com,111111
col@qq.com,111111
mon@qq.com,111111
为使用的用户名和密码,也可以加其他参数,用逗号隔开,每一列表示一种参数,每一行则表示一组参数
2、在jmeter中的【选项】中选择【函数助手对话框】,将会弹出如下对话框:
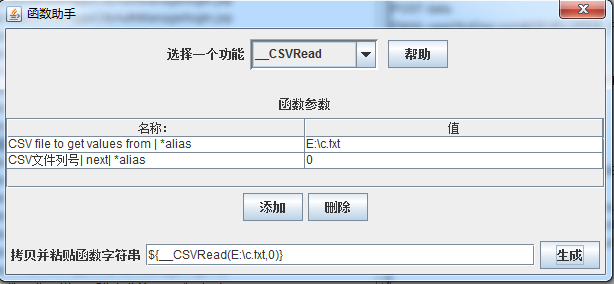
其中:
CSV file to get values from | *alias:要读取的文件路径,为绝对路径
CSV文件列号| next| *alias:从第几列开始读取,注意第一列是0
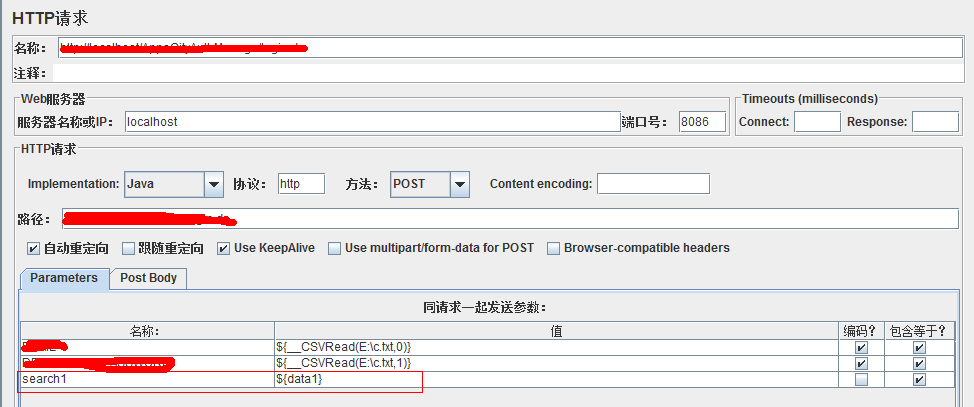
如上图所示,我们读取的是c.txt里面的第一列用户名(如果要读取第二列的密码,只需将0改成1即可,往后类推),点击【生成】按钮即可生成函数,我们使用时即拷贝生成的函数字符串:${__CSVRead(E:\c.txt,0)}
3、使用如下图所示:
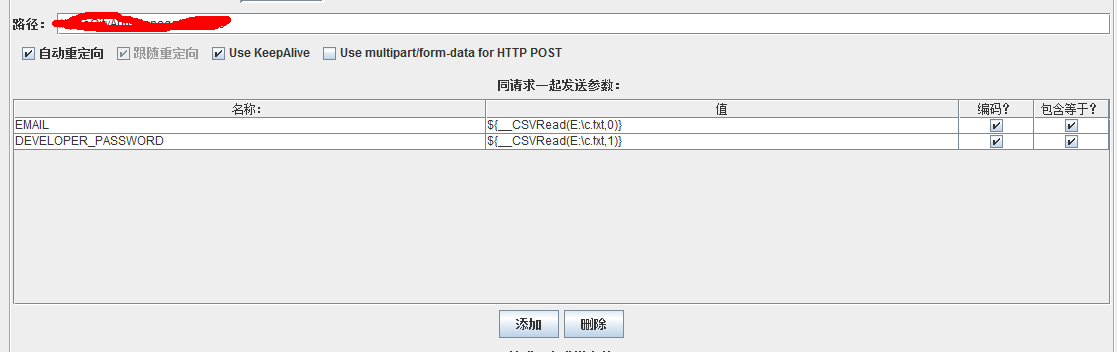
其中的值即为我们的生成的函数(${__CSVRead(E:\c.txt,0)}),jmeter执行时,如果是多线程,则从c.txt中第一行开始读取,如果设置的线程数大于c.txt中的行数,将会循环读取数据,通常该行数可用于参数化
二、_Random 函数
_Random函数是从某数据段随机读取数据替换参数,当需要添加多条数据记录且某些字段需要唯一性时使用,使用该函数随机生成的数据是数字。
步骤:
1、在jmeter中的【选项】中选择【函数助手对话框】,将会弹出如下对话框:选择_Random
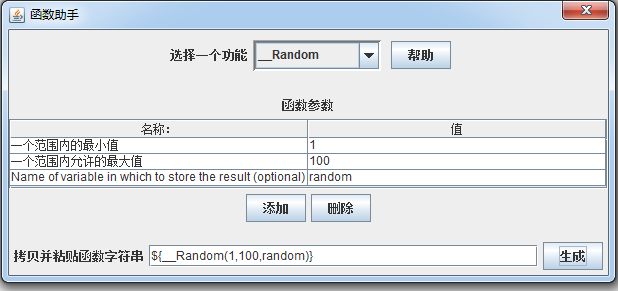
如上图:
一个范围内的最小值:即我们所要取的随机数的最小值,上述设置为1,生成的随机数将不会小于1
一个范围内允许的最大值:即我们所要取的随机数的最大值,上述设置为100,生成的随机数将不能超过100
Name of variable in which to store the result(optional)为函数名称名称:这里我们设置为random,即用于存储在测试计划中其他的方式使用的值
点击【生成】按钮即可得到我们所需要的函数:${__Random(1,100,random)},然后将函数复制到需要用到随机数的地方,我们就可以使用啦。
注意:当我们设置的线程数超过随机数范围时,随机数将会重复生成
2、使用如下图所示:

将生成的函数填充进值框中即可
三、_ StringFromFile 函数
_StringFromFile函数是从一个文件中读取一个字符串,用来实现参数化,如果读取或者打开这个文件发生错误时,将会返回“**ERR**
”字符串
步骤:
1、在jmeter中的【选项】中选择【函数助手对话框】,将会弹出如下对话框:选择_StringFromFile
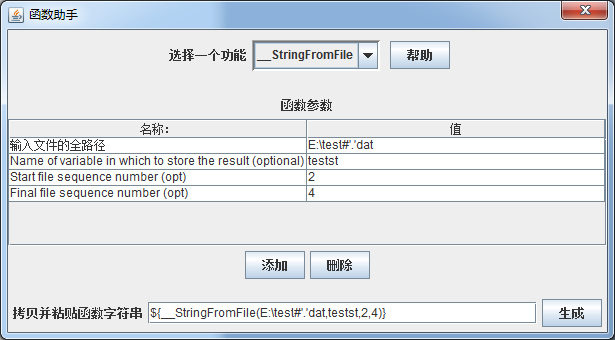
输入文件的全路径:输入读取文件的绝对路径
Name of variable in which to store the result:函数名称(只是用来存储变量的名称,不可以${名称}使用)
Start file sequence number:初始序列号
Final file sequence number:结束序列号
上图所示表示:如果目录下面有test2.dat、test3.dat、test4.dat,则按顺序读取这三个文件中的每行值,其中初始序列号表示文件后面的开始序号,如果有test1.dat文件将不会被读取,结束序列号类推(至于为什么会有这个看起来似乎是多余的功能,而不是直接全部写到一个文件里,猜想有可能是在数据过多的时候,避免一个文件太大或者是他们的习惯?)。
另外使用的时候,我循环了10次,但是这三个文件我只设置了9行值,结果点击运行,显示只执行了9次,而不会循环从第一个文件中读取。
当然,如果你就只是想读取一个文件,直接在【输入文件的全路径】后面输入文件的路径即可,其余三个值不用填写,点击生成即可一样调用
如果希望让文件执行多次,可以按如下配置:
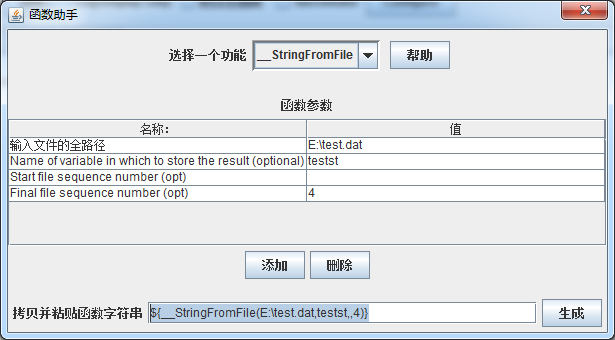
表示test.dat文件将会被读取4次
当线程组大于(文件行数*4)时,将只会执行(文件行数*4)次,而不会循环读取执行所有的设定线程组数,没有指定读取次数,则默认会循环读取数据
2、引用函数:
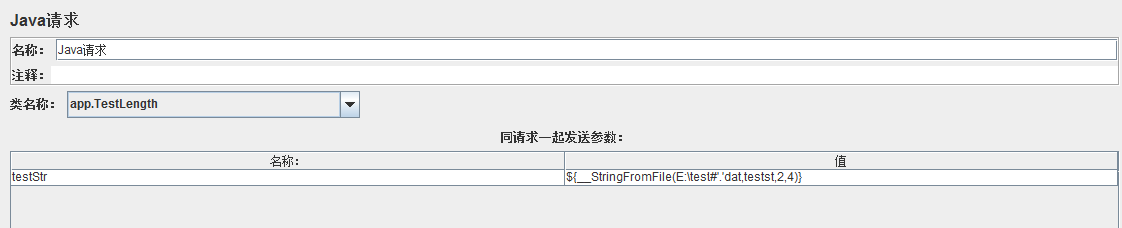
四、_Counter 函数
每次调用计数器函数都会产生一个新值,从1开始每次加1。计数器既可以被配置成针对每个虚拟用户是独立的,也可以被配置成所有虚拟用户公用的。如果每个虚拟用户的计数器是独立增长的,那么通常被用于记录测试计划运行了多少遍。全局计数器通常被用于记录发送了多少次请求。
计数器使用一个整数值来记录,允许的最大值为2,147,483,647。
功能:这个函数是一个计数器,用于统计函数的使用次数,它从1开始,每调用这个函数一次它就会自动加1,它有两个参数,第一个参数是布尔型的,只能设置成“TRUE”或者“FALSE”,如果是TRUE,那么每个用户有自己的计数器,可以用于统计每个线程歌执行了多少次。如果是FALSE,那就使用全局计数器,可以统计出这次测试共运行了多少次。第二个参数是“函数名称”
格式:${__counter(FALSE,test)}
使用:我们将“_counter”函数生成的参数复制到某个参数下面,如果为TRUE格式,则每个线程各自统计,最大数为循环数,如果为FALSE,则所有线程一起统计,最大数为线程数乘以循环数
参数:
第一个参数:True,如果测试人员希望每个虚拟用户的计数器保持独立,与其他用户的计数器相区别。False,全局计数器
第二个参数:重用计数器函数创建值的引用名。测试人员可以这样引用计数器的值:${test}。这样一来,测试人员就可以创建一个计数器后,在多个地方引用它的值。
以上,摘自网络(不知道怎么用,只好摘抄,记录下来等灵感~~~~(>_<)~~~~
)。
目前,我测试_Counter函数,就是在参数列表加一个参数,值填写为${__counter(FALSE,test)}
如图:
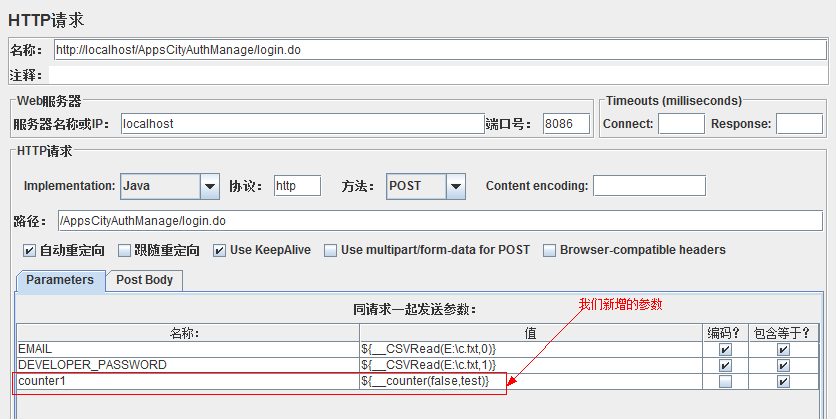
如上,设置为false,那么发送了多少个请求,counter1的最大值就等于最大请求数。
想知道counter1的值,可以通过结果树查看。
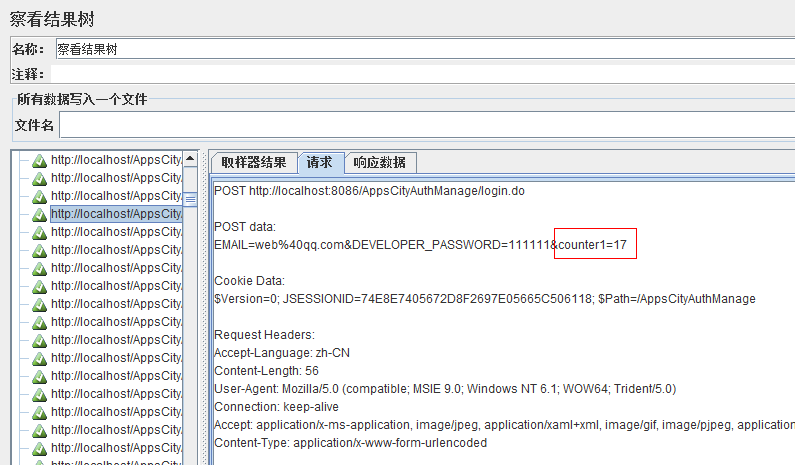
五、_RegexFunction 正则函数
正则表达式函数可以使用正则表达式(用户提供的)来解析前面的服务器响应(或者是某个变量值)。函数会返回一个有模板的字符串,其中携带有可变的值。
_RegexFunction还可以被用来保存值,以便供后续使用。具体的引用名是函数的第6个参数。在函数执行后,测试人员可以使用用户定义值的语法来获取同样的值。
例如,如果测试人员输入“refName”昨晚第6个参数,那么测试人员可以使用:
${refName}来引用第二个参数的结果,即函数运行的结果。
${refName_g0}来引用函数解析后发现的所有匹配结果。
${refName_g1}来引用函数解析后发现的第一个匹配组合。
${refName_g#}来引用函数解析后发现的第N个匹配组合。
${refName_matchNr}来引用函数总共发现的函数匹配组合的数目。
参数:
第一个参数:用于解析服务器响应数据的正则表达式。它会找到所有的匹配项。如果测试人员希望将表达式中的某部分应用在模板字符串中,记得加上圆括号。例如,<a
href=”(.*)”>。这样就会将链接的值存放到第一个匹配组合中(这里只有一个匹配组合)。又如,<input
type=”hidden” name=”(.*)”value=”(.*)”>。在这个例子中,链接的name作为第一个匹配组合,链接的value会作为第二个匹配组合。这些组合可以用在测试人员的模板字符串中
第二个参数:这是一个模板字符串,函数会动态填写字符串的部分内容。要在字符串中引用正则表达式捕获的匹配组合,请使用语法:$[group_number]$。例如$1$或者
$2$。测试人员的模板可以是任何字符串
第三个参数:第3个参数告诉JMeter使用第几次匹配。测试人员的正则表达式可能会找到多个匹配项。对此,测试人员有4种选择:
1、整数,直接告诉JMeter使用第几个匹配项。 “1”对应第一个匹配,“2”对应第二个匹配,以此类推
2、RAND,告诉JMeter随机选择一个匹配项
3、ALL,告诉JMeter使用所有匹配项,为每一个匹配项创建一个模板字符串,并将它们连接在一起
4、浮点值0到1之间,根据公式(找到的总匹配数目*指定浮点值)计算使用第几个匹配项,计算值向最近的整数取整
第四个参数:如果在上一个参数中选择了“ALL”,那么这第4个参数会被插入到重复的模板值之间
第五个参数:如果没有找到匹配项返回的默认值
第六个参数:重用函数解析值的引用名,参见上面内容
第七个参数:输入变量名称。如果指定了这一参数,那么该变量的值就会作为函数的输入,而不再使用前面的采样结果作为搜索对象
以上摘自温素剑的《零成本实现Web性能测试:基于Apache JMeter》。
步骤:
1、在jmeter中的【选项】中选择【函数助手对话框】,将会弹出如下对话框:选择_RegexFunction
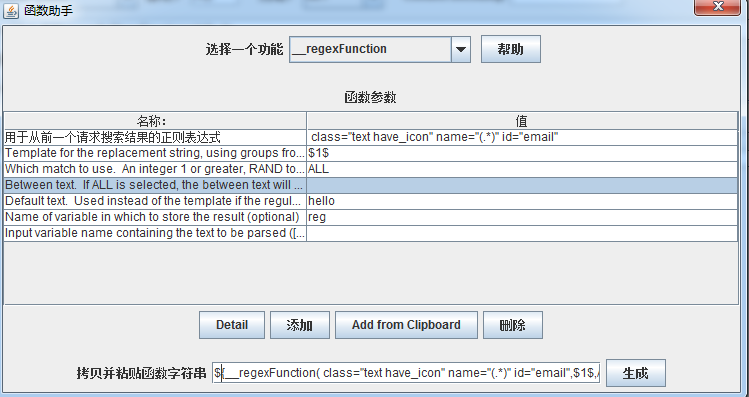
参数的介绍见上文。
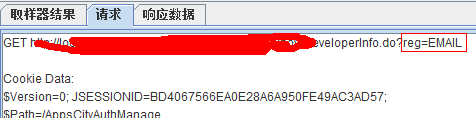
如上,在【 class=”text have_icon” name=”(.*)” id=”email”】里面,得到到第一个匹配的name的值,如果没有找到匹配的,得到的值就为hello

如上,我们应该匹配得到的值为:EMAIL
使用:
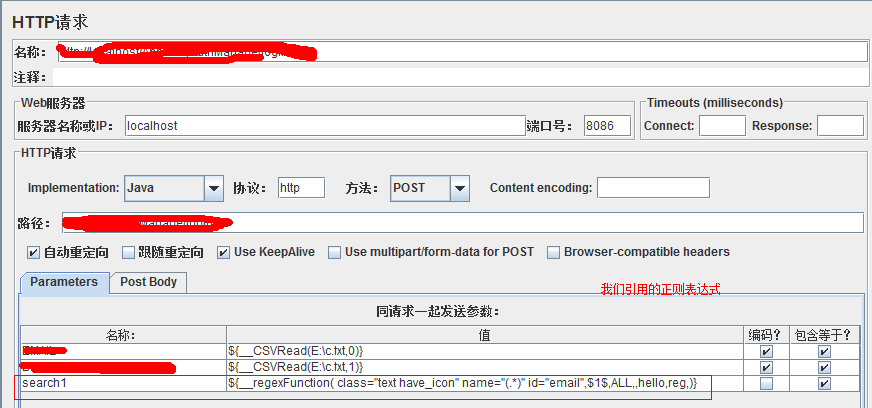
查看是否成功:
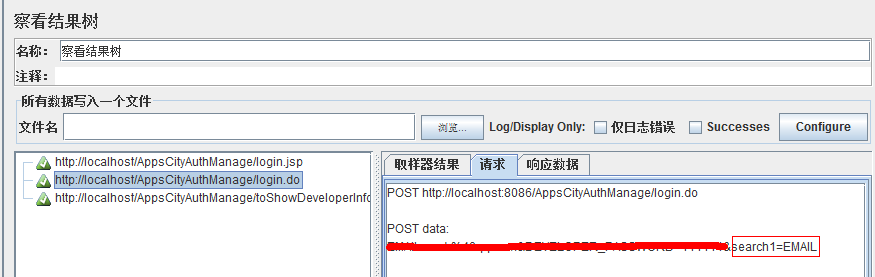
记得上面我们设定的第5个参数吗?如果没有在响应数据里面找到匹配的,返回的值就为我们制定的hello,如下:

如果该正则函数在前面已经使用过,我们在后面就可以用我们指定的第6个参数的值来引用该函数得到函数解析的结果啦:
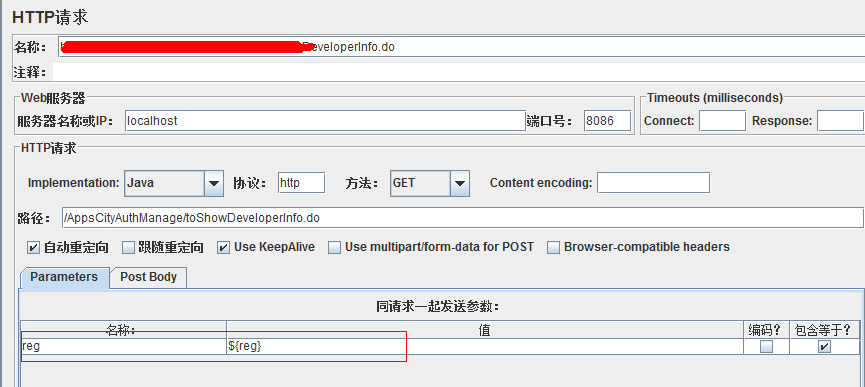
六、_javaScript函数
函数__javaScript可以用来执行JavaScript代码片段(非Java),并返回结果值。JMeter的_javaScript函数会调用标准的JavaScript解释器。JavaScript会作为脚本语言使用,因此测试人员可以做相应的计算。
在脚本中可以访问如下一些变量。
Log:该函数的日志记录器。
Ctx:JmeterContext对象。
Vars:JmeterVariables对象。
threadName:字符串包含当前线程名称 (在2.3.2 版本中它被误写为”theadName”)。
sampler:当前采样器对象(如果存在)。
sampleResult:前面的采样结果对象(如果存在)。
props:JMeter属性对象。
Rhinoscript允许通过它的包对象来访问静态方法。例如,用户可以使用如下方法访问JMeterContextService静态方法:
Packages.org.apache.jmeter.threads.JMeterContextService.getTotalThreads()
JMeter不是一款浏览器,它不会执行从页面下载的JavaScript。
参数:
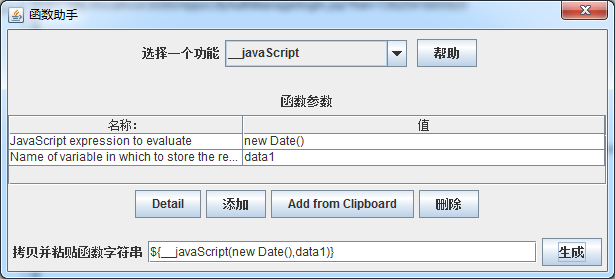
第一个参数:JavaScript代码片段,待执行的JavaScript代码片段。例如:
1、new Date():返回当前日期和时间
2、 Math.floor(Math.random()*(${maxRandom},+1)):在0
和变量maxRandom之间的随机数
3、${minRandom}+Math.floor(Math.random()*(${maxRandom}-${minRandom}+1)):在变量
minRandom和maxRandom之间的随机数”${VAR}”==”abcd”
第二个参数:变量名,重用函数计算值的引用名
请记得为文本字符串添加必要的引号。另外,如果表达式中有逗号,请确保对其转义。例如,${__javaScript(‘${sp}’.slice(7\,99999))},对7之后的逗号进行了转义。
摘自《零成本实现Web性能测试:基于Apache JMeter》 。
步骤:
1、在jmeter中的【选项】中选择【函数助手对话框】,将会弹出如下对话框:选择__javaScript
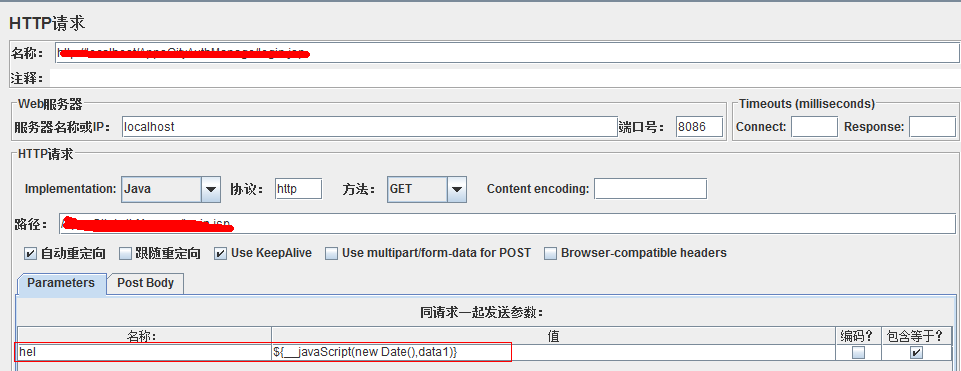
这是得到当前日期,引用:
得到结果日期:
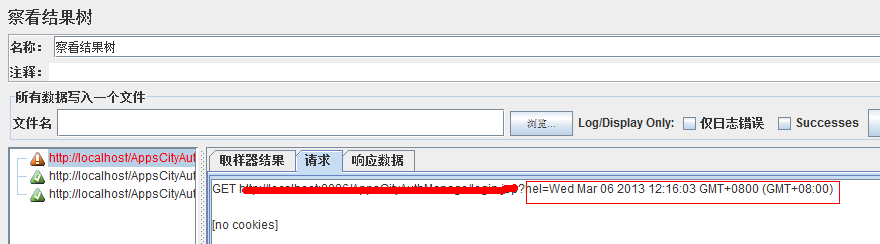
第二个参数是变量名,当该函数被执行一次之后,我们就可以根据变量名引用该函数,得到函数解析的值:
需要注意的是:JMeter不是浏览器,因此不会执行Sampler接收到的页面上的javascript,也不能使用__javascript函数来调用用户自定义的javascript函数。
七、_split函数
${__split(…)} 是JMeter中自带的拆分字符串为数组的函数,有3个参数, 第1个参数为被分割的字符串,第2个参数为存放分割后字符串的参数名称,第3个参数为用于分割的分隔符。例如,函数表达式”${__split(a|b|c,VAR,|)}”执行完成后,结果被存放在4个参数中:
${VAR_n}的值为3:总共得到了3个分割后的字符串。
${VAR_1}的值为a:第1个分割得到的字符串。
${VAR_2}的值为a:第2个分割得到的字符串。
${VAR_3}的值为a:第3个分割得到的字符串。
另外有个需要注意的问题是:在${__split(…)} 中,如果拆分字符串中的内容包含有符号”,”,一定得用符号”\”进行转义,否则可能被JMeter误认为是参数分隔符,会导致无法正确生成字符串数组。
八、__threadNum与__machinaName函数
${__threadNum}是一个系统参数,其取值为当前线程的线程号
${__machinaName}是一个系统参数,获取执行当前Test Plan的机器名。
在调试或记录日志时,可以使用这两个函数输出与线程号和机器名称相关的信息。
九、__time函数
time函数可以获取当前时间,该函数的第一个参数为日期格式,第二个参数为存放获得当前时间值的参数名称。如:${__time(yyyy-MM-dd
HH:mm:ss,)}
十、__intSum与__longSum函数
__intSum与__longSum函数分别用来进行整型和长整型数据的加法运算。这两个函数均为可变参数列表的函数,可用来进行任意个整型或长整型数据的加法运算。
十一、__setProperty函数
该函数用于运行时设置JMeter中的任何属性的值。
十二、__eval和__evalVar函数
这两个函数用于计算一个参数表达式的值。例如,给定参数值:Table=mytable Column=username
Username=dennis
SQL=select ${column} from ${table} where userid=’${username}’
则${__eval${SQL}}得到的值为select username from mytable
where uername=’dennis’
_evalVal函数与__eval函数基本一致,唯一不同的是,__evalVar函数可以将计算后的值存放到一个参数中。
十三、__BeanShell函数
该函数允许用户运行一段自定义的BeanShell函数,脚本可以用来设置JMeter的属性和参数值,也可以返回数据。BeanShell是一种非常灵活的脚本方式。 |









