| ��˵LoadRunner�е�һЩ���ܣ����磺�����������㡢���ϵ㡢������JmeterҲ������Щ���ܣ�ֻ�ǹ��ܿ�������һЩ���������������һ�¡�
JMeter�Ĺ������������֣����ô��������������ʽ��ȡ����XPath Extractor��
һ���������ʽ��ȡ��
1�������������ʽ
����Ҫ������ݵ���һ���������һ�����һ�����ô������C>�������ʽ��ȡ��
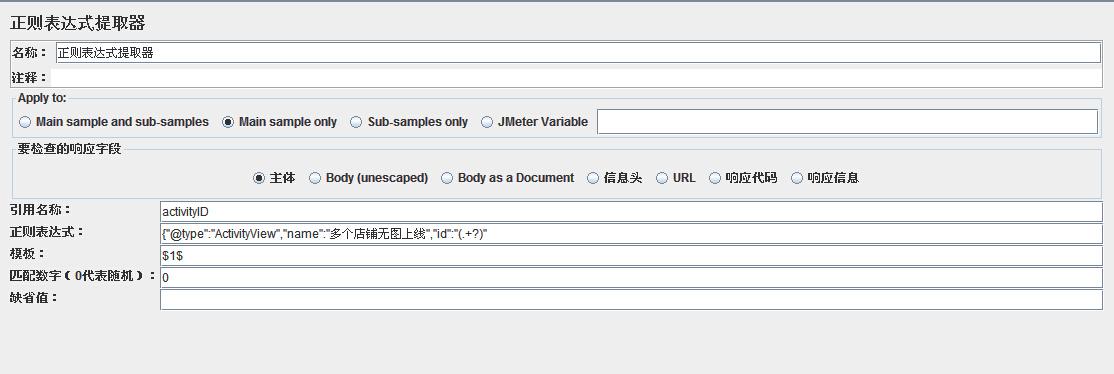
���ͣ�
��1���������ƣ���һ������Ҫ���õIJ������ƣ�����дactivityID�������${activityID}��������
��2���������ʽ��
()�������IJ��־���Ҫ��ȡ�ġ�
��������.ƥ���κ��ַ�����
��������+��һ�λ��Ρ�
��������?����Ҫ̫̰�������ҵ���һ��ƥ�����ֹͣ��
ע��(.+?)[.\n]+����ƥ�任�з����ڵ������ַ���
��3��ģ�壺��$$����������������������ʽ���ж���������ʽ����������������Ķ��������������$2$$3$�ȵȣ���ʾ�������ĵڼ���ֵ��title���磺$1$��ʾ�������ĵ�1��ֵ
��4��ƥ�����֣�0�������ȡֵ��1����ȫ��ȡֵ��ͨ���������0�������LR�У�ȡ����ֵ��һ�����飬���ô���һ�£�LR11�汾��һ������ĺ����Ϳ��Բ���д��εĴ������������顣
��5��ȱʡֵ���������û��ȡ�õ�ֵ����Ĭ�ϸ�һ��ֵ����ȡ��
2�������������ʽ�ľ���˵��
��1����ȡ�����ַ�����
���������Ա����ƥ��Webҳ������²��֣�name = ��file�� value = ��readme.txt��>����ȡreadme.txt��
һ������Ҫ����������ʽ��name = ��file�� value = ��(.+?)��>��
()����װ�˴����ص�ƥ���ַ�����
.��ƥ���κ��ַ�����
+��һ�λ��Ρ�
?����Ҫ̫̰�������ҵ���һ��ƥ�����ֹͣ��
��2����ȡ����ַ�����
���������Ա����ƥ��Webҳ������²��֣�name = ��file�� value = ��readme.txt��>����ȡfile��readme.txt��
һ������Ҫ����������ʽ��name = ��(.+?)�� value = ��(.+?)����
�������ƣ�MYREF
ģ�壺$1$$2$
���±�����ֵ���ᱻ�趨��
MYREF_g0:name = ��file��value = ��readme.txt��
MYREF_g1:file
MYREF_g2:readme.txt
����${MYREF_g1}
3��ʹ�øù���������
����ͼ��
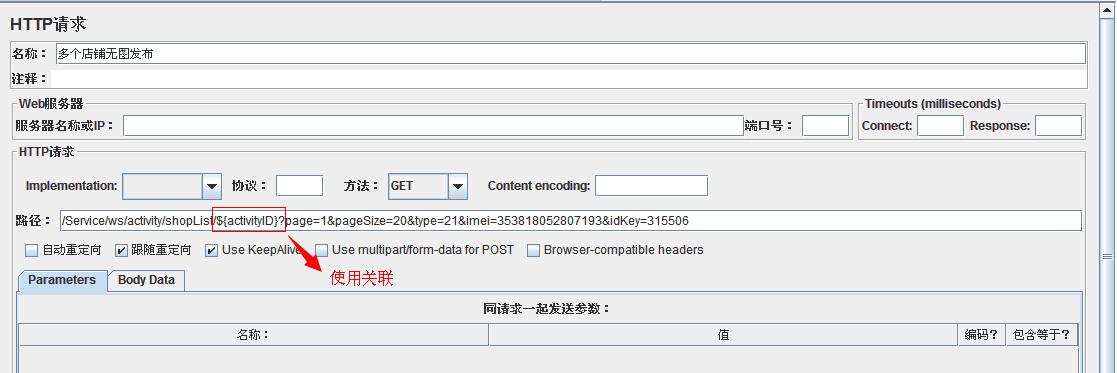
����XPath Extractor
XPath Extractor����һ���ɱ�������ȡҳ��������ݵ�Post Processor��XPath
Extractor��ʹ�÷�ʽ��Regular Expression Extractor���ƣ�ֻ������Ҫ�ڸ�Extractor��ָ���IJ����������ʽ�����Ǹ�����XPath·����
��xpath��ǰһ��������ȡ��������ʽ�Ƚ��ʺ��ڷ���ΪxmlƬ�ε����������Ҫ������ݵ��������һ�����һ�����ô������C>xPath
Extractor���������Ƽ���һ������Ҫ���õIJ������ƣ�����дbody�������${body}��������
Xpathһ�����ڷ���xml�õöࡣ
XPath Extractor�����ý��棺
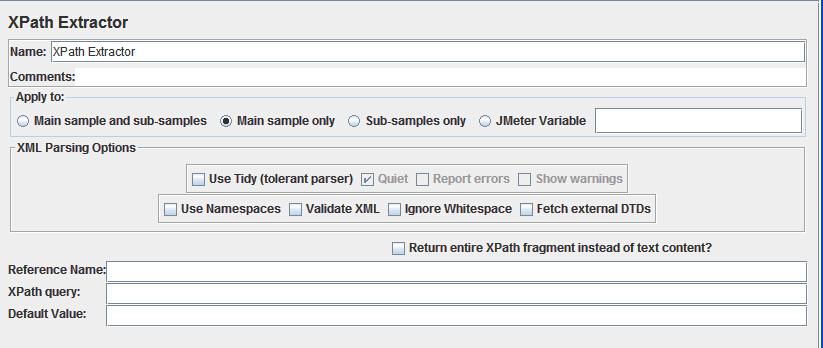
l Use Tidy?������Ҫ������ҳ����HTML��ʽʱ������ѡ�и�ѡ�����Ҫ������ҳ����XML��XHTML��ʽ�����磬RSS���أ�ʱ��ȡ��ѡ�и�ѡ�
l Reference Name�������ȡ����ֵ�IJ�����
l XPath Query��������ȡֵ��XPath����ʽ��
l Default Value��������Ĭ��ֵ��
����С�������ַ�ʽ
�������ʽ��ȡ����XPath Extractor������������ȡ����ҳ���е��ض��ı��������䱣���ڲ����У������ַ�ʽ������ȱ�㡣
�������ʽ��ȡ���������ڶ�ҳ���κ��ı�����ȡ����ȡ�������Ǹ����������ʽ��ҳ�������н����ı�ƥ��;
��XPath Extractor�������ȡ����ҳ������Ԫ�ص��������ԡ�
��Ƚ϶��ԣ�
�����Ҫ��ȡ���ı���ҳ����ijԪ�ص�����ֵ������ʹ��XPath Extractor;
�������Ҫ��ȡ���ı���ҳ���ϵ�λ�ò��̶������߲���Ԫ�ص����ԣ�����ʹ���������ʽ��ȡ���� |









