|
дкЮвУЧСЫНтFlumeКЭSqoopжЎЧАЃЌШУЮвУЧбаОПЪ§ОнМгдиЕНHadoopЕФЮЪЬтЃК
ЪЙгУHadoopЗжЮіДІРэЪ§ОнЃЌашвЊзАдиДѓСПДгВЛЭЌРДдДЕФЪ§ОнЕНHadoopМЏШКЁЃ
ДгВЛЭЌРДдДДѓШнСПЕФЪ§ОнМгдиЕНHadoopЃЌШЛКѓетИіЙ§ГЬДІРэЫќЃЌетОпгавЛЖЈЕФЬєеНЁЃ
ЮЌЛЄКЭШЗБЃЪ§ОнЕФвЛжТадЃЌВЂШЗБЃзЪдДЕФгааЇРћгУЃЌбЁдёе§ШЗЕФЗНЗЈНјааЪ§ОнМгдиЧАгавЛаЉвђЫиЪЧвЊПМТЧЕФЁЃ
жївЊЮЪЬтЃК
1. ЪЙгУНХБОМгдиЪ§Он
ДЋЭГЕФЪЙгУНХБОМгдиЪ§ОнЕФЗНЗЈЃЌВЛЪЪКЯгкДѓШнСПЪ§ОнМгдиЕН Hadoop;етжжЗНЗЈаЇТЪЕЭЧвЗЧГЃКФЪБЁЃ
2. ЭЈЙ§ Map-Reduce гІгУГЬађжБНгЗУЮЪЭтВПЪ§Он
ЬсЙЉСЫжБНгЗУЮЪзЄСєдкЭтВПЯЕЭГжаЕФЪ§Он(ВЛМгдиЕНHadopp)ЕНmap reduceЃЌетаЉгІгУГЬађИДдгадЁЃЫљвдЃЌетжжЗНЗЈЪЧВЛПЩааЕФЁЃ
3.Г§СЫОпгаХгДѓЕФЪ§ОнЕФЙЄзїФмСІЃЌHadoopПЩвддкМИжжВЛЭЌаЮЪНЕФЪ§ОнЩЯЙЄзїЁЃетбљЃЌзАдиДЫРрвьЙЙЪ§ОнЕНHadoopЃЌВЛЭЌЕФЙЄОпвбОБЛПЊЗЂЁЃSqoopКЭFlume ОЭЪЧетбљЕФЪ§ОнМгдиЙЄОпЁЃ
SQOOPНщЩм
Apache Sqoop(SQLЕНHadoop)БЛЩшМЦЮЊжЇГжХњСПДгНсЙЙЛЏЪ§ОнДцДЂЕМШыЪ§ОнЕНHDFSЃЌШчЙиЯЕЪ§ОнПтЃЌЦѓвЕМЖЪ§ОнВжПтКЭNoSQLЯЕЭГЁЃSqoopЪЧЛљгквЛИіСЌНгЦїЬхЯЕНсЙЙЃЌЫќжЇГжВхМўРДЬсЙЉСЌНгЕНаТЕФЭтВПЯЕЭГЁЃ
вЛИіSqoop ЪЙгУЕФР§згЪЧЃЌвЛИіЦѓвЕдЫаадквЙМфЪЙгУ Sqoop ЕМШыЕБЬьЕФЩњВњИККЩНЛвзЕФRDBMS Ъ§ОнЕН Hive Ъ§ОнВжПтзїНјвЛВНЗжЮіЁЃ
Sqoop СЌНгЦї
ЯжгаЪ§ОнПтЙмРэЯЕЭГЕФЩшМЦГфЗжПМТЧСЫSQLБъзМЁЃЕЋЪЧЃЌУПИіВЛЭЌЕФ DBMS ЗНбдЛЏЕНФГжжГЬЖШЁЃвђДЫЃЌетжжВювьДјРДЕФЬєеНЃЌЕБЩцМАЕНећИіЯЕЭГЕФЪ§ОнДЋЪфЁЃSqoopСЌНгЦїОЭЪЧгУРДНтОіетаЉЬєеНЕФзщМўЁЃ
SqoopКЭЭтВПДцДЂЯЕЭГжЎМфЕФЪ§ОнДЋЪфдк Sqoop СЌНгЦїЕФАяжњЯТЪЙЕУгаПЩФмЁЃ
Sqoop СЌНгЦїгыИїжжСїааЕФЙиЯЕаЭЪ§ОнПтЃЌАќРЈЃКMySQL, PostgreSQL, Oracle, SQL Server КЭ DB2 ЙЄзїЁЃУПИіетаЉСЌНгЦїжЊЕРШчКЮгыЫќЕФЯрЙиСЊЕФЪ§ОнПтЙмРэЯЕЭГНјааНЛЛЅЁЃ ЛЙгагУгкСЌНгЕНжЇГжJava JDBCавщЕФШЮКЮЪ§ОнПтЕФЭЈгУJDBCСЌНгЦїЁЃ ДЫЭтЃЌSqoopЬсЙЉгХЛЏMySQLКЭPostgreSQLСЌНгЦїЪЙгУЪ§ОнПтЬиЖЈЕФAPIЃЌвдгааЇЕижДааХњСПДЋЪфЁЃ
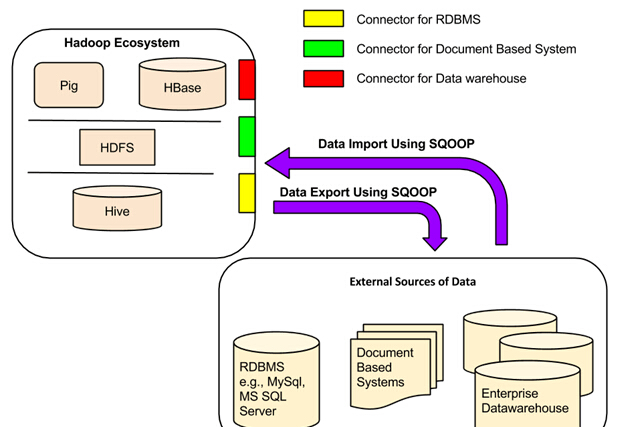
Г§СЫетвЛЕуЃЌSqoopОпгаИїжжЕкШ§ЗНСЌНгЦїгУгкЪ§ОнДцДЂЃЌ
ДгЦѓвЕЪ§ОнВжПт(АќРЈNetezzaЙЋЫОЃЌTeradataКЭМзЙЧЮФ)ЕН NoSQLДцДЂ(ШчCouchbase)ЁЃЕЋЪЧЃЌетаЉСЌНгЦїУЛгаХфБИSqoopЪј; етаЉашвЊЕЅЖРЯТдиВЂКмШнвзЕиАВзАЬэМгЕНЯжгаЕФSqoopЁЃ
FLUME НщЩм
Apache Flume гУгквЦЖЏДѓЙцФЃХњСПСїЪ§ОнЕН HDFS ЯЕЭГЁЃДгWebЗўЮёЦїЪеМЏЕБЧАШежОЮФМўЪ§ОнЕНHDFSОлМЏгУгкЗжЮіЃЌвЛИіГЃМћЕФгУР§ЪЧFlumeЁЃ
Flume жЇГжЖржжРДдДЃЌШчЃК
“tail”(ДгБОЕиЮФМўЃЌИУЮФМўЕФЙмЕРЪ§ОнКЭЭЈЙ§FlumeаДШы HDFSЃЌРрЫЦгкUnixУќСю“tail”)
ЯЕЭГШежО
Apache log4j (дЪаэJavaгІгУГЬађЭЈЙ§FlumeЪТМўаДШыЕНHDFSЮФМў)ЁЃ
дк Flume ЕФЪ§ОнСї
FlumeДњРэЪЧJVMНјГЬЃЌРяУцга3ИізщГЩВПЗж - Flume Source, Flume Channel КЭ Flume Sink -ЭЈЙ§ИУЪТМўДЋВЅЗЂЦ№дкЭтВПдДжЎКѓЁЃ
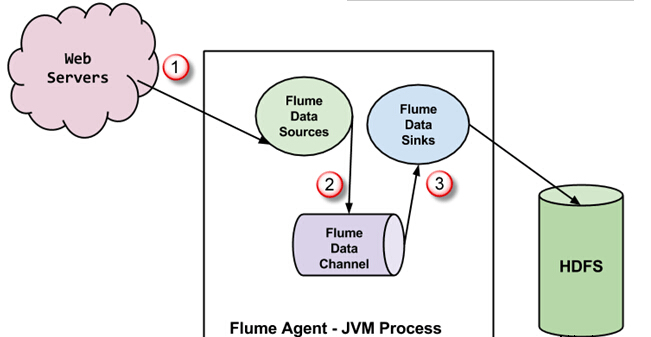
дкЩЯУцЕФЭМжаЃЌгЩЭтВПдД(WebЗўЮёЦї)ЩњГЩЕФЪТМўЪЧгЩFlumeЪ§ОндДЯћКФЁЃ ЭтВПдДНЋЪТМўвдФПБъдДЪЖБ№ЕФИёЪНЗЂЫЭИј Flume дДЁЃ
Flume дДНгЪеЕНвЛИіЪТМўЃЌВЂНЋЦфДцДЂЕНвЛИіЛђЖрИіаХЕРЁЃаХЕРГфЕБДцДЂЪТМўЃЌжБЕНЫќгЩ flumeЯћКФЁЃДЫаХЕРПЩФмЪЙгУБОЕиЮФМўЯЕЭГвдБуДцДЂетаЉЪТМўЁЃ
Flume НЋЩОГ§аХЕРЃЌВЂДцДЂЪТМўЕНШчHDFSЭтВПДцДЂПтЁЃПЩФмЛсгаЖрИі flume ДњРэЃЌдкетжжЧщПіЯТЃЌflumeНЋЪТМўзЊЗЂЕНЯТвЛИіflumeДњРэЁЃ
FLUME вЛаЉживЊЬиад
Flume ЛљгкСїУНЬхЪ§ОнСїСщЛюЕФЩшМЦЁЃетЪЧШнДэКЭЧПДѓЕФЖрЙЪеЯЧаЛЛКЭЛжИДЛњжЦЁЃ Flume гаВЛЭЌГЬЖШЕФПЩППадЃЌЬсЙЉАќРЈ“ОЁСІДЋЪф'КЭ'ЖЫжСЖЫЪфЫЭ'ЁЃОЁСІЖјЮЊЕФДЋЪфВЛЛсШнШЬШЮКЮ Flume НкЕуЙЪеЯЃЌЖј“жеЖЫЕНжеЖЫЕФДЋЕн”ФЃЪНЃЌБЃжЄДЋЕндкЖрИіНкЕуГіЯжЙЪеЯЕФЧщПіЁЃ
Flume ГадидДКЭНгЪежЎМфЕФЪ§ОнЁЃетжжЪ§ОнЪеМЏПЩвдБЛдЄЖЈЛђЪЧЪТМўЧ§ЖЏЁЃFlumeгаЫќздМКЕФВщбЏДІРэв§ЧцЃЌетЪЙЕУдкзЊЛЏУПХњаТЪ§ОнвЦЖЏжЎЧАЫќФмЙЛЕНдЄЖЈНгЪеЦїЁЃ
ПЩФм Flume АќРЈHDFSКЭHBaseЁЃFlume вВПЩвдгУРДЪфЫЭЪТМўЪ§ОнЃЌАќРЈЕЋВЛЯогкЭјТчЕФвЕЮёЪ§ОнЃЌвВПЩвдЪЧЭЈЙ§ЩчНЛУНЬхЭјеОКЭЕчзггЪМўЯћЯЂЫљВњЩњЕФЪ§ОнЁЃ
зд2012Фъ7дТFlume ЗЂВМСЫаТАцБО Flume NG(аТвЛДњ)ЃЌвђЮЊЫќКЭдРДЕФАцБОгаУїЯдЕФВЛЭЌЃЌвђЮЊБЛГЦЮЊ Flume OG (дДњ)ЁЃ
|









