|
Hadoop ИНДјСЫвЛИіУћЮЊ HDFS(HadoopЗжВМЪНЮФМўЯЕЭГ)ЕФЗжВМЪНЮФМўЯЕЭГЃЌЛљгк Hadoop ЕФгІгУГЬађЪЙгУ HDFS ЁЃHDFS ЪЧзЈЮЊДцДЂГЌДѓЪ§ОнЮФМўЃЌдЫаадкМЏШКЕФЩЬЦЗгВМўЩЯЁЃЫќЪЧШнДэЕФЃЌПЩЩьЫѕЕФЃЌВЂЧвЗЧГЃвзгкРЉеЙЁЃ
ФужЊЕРТ№? ЕБЪ§ОнГЌЙ§вЛИіЕЅИіЮяРэЛњЦїЩЯДцДЂЕФШнСПЃЌГ§вдПчЖРСЂЛњЦїЪ§ЁЃЙмРэПчдНЛњЦїЕФЭјТчДцДЂЬиЖЈВйзїБЛГЦЮЊЗжВМЪНЮФМўЯЕЭГЁЃ
HDFSМЏШКжївЊгЩ NameNode ЙмРэЮФМўЯЕЭГ Metadata КЭ DataNodes ДцДЂЕФЪЕМЪЪ§ОнЁЃ
NameNode: NameNodeПЩвдБЛШЯЮЊЪЧЯЕЭГЕФжїеОЁЃЫќЮЌЛЄЫљгаЯЕЭГжаДцдкЕФЮФМўКЭФПТМЕФЮФМўЯЕЭГЪїКЭдЊЪ§Он ЁЃ СНИіЮФМўЃК“УќУћПеМфгГЯё“КЭ”БрМШежО“ЪЧгУРДДцДЂдЊЪ§ОнаХЯЂЁЃNamenode гаЫљгаАќКЌЪ§ОнПщЮЊвЛИіИјЖЈЕФЮФМўжаЕФЪ§ОнНкЕуЕФжЊЪЖЃЌЕЋЪЧВЛДцДЂПщЕФЮЛжУГжајЁЃДгЪ§ОнНкЕудкЯЕЭГУПДЮЦєЖЏЪБаХЯЂжиЙЙвЛДЮЁЃ
DataNode : DataNodesзїЮЊДгЛњЃЌУПЬЈЛњЦїЮЛгквЛИіМЏШКжаЃЌВЂЬсЙЉЪЕМЪЕФДцДЂ. ЫќИКд№ЮЊПЭЛЇЖСаДЧыЧѓЗўЮёЁЃ
HDFSжаЕФЖС/аДВйзїдЫаадкПщМЖЁЃHDFSЪ§ОнЮФМўБЛЗжГЩПщДѓаЁЕФПщЃЌетЪЧзїЮЊЖРСЂЕФЕЅдЊДцДЂЁЃФЌШЯПщДѓаЁЮЊ64 MBЁЃ
HDFSВйзїЩЯЪЧЪ§ОнИДжЦЕФИХФюЃЌЦфжадкЪ§ОнПщЕФЖрИіИББОБЛДДНЈЃЌЗжВМдкећИіНкЕуЕФШКМЏвдЪЙдкНкЕуЙЪеЯЕФЧщПіЯТЪ§ОнЕФИпПЩгУадЁЃ
зЂЃК дкHDFSЕФЮФМўЃЌБШЕЅИіПщаЁЃЌВЛеМгУПщЕФШЋВПДцДЂЁЃ
дкHDFSЖСВйзї
Ъ§ОнЖСШЁЧыЧѓНЋгЩ HDFSЃЌNameNodeКЭDataNodeРДЗўЮёЁЃШУЮвУЧАбЖСШЁЦїНа “ПЭЛЇ”ЁЃЯТЭМУшЛцСЫЮФМўЕФЖСШЁВйзїдк Hadoop жаЁЃ
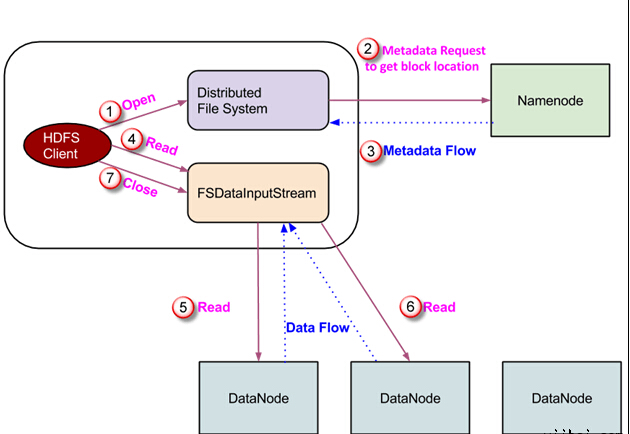
ПЭЛЇЖЫЦєЖЏЭЈЙ§ЕїгУЮФМўЯЕЭГЖдЯѓЕФ open() ЗНЗЈЖСШЁЧыЧѓ; ЫќЪЧ DistributedFileSystem РраЭЕФЖдЯѓЁЃ
ДЫЖдЯѓЪЙгУ RPC СЌНгЕН namenode ВЂЛёШЁЕФдЊЪ§ОнаХЯЂЃЌШчИУЮФМўЕФПщЕФЮЛжУЁЃ ЧызЂвтЃЌетаЉЕижЗЪЧЮФМўЕФЧАМИИіПщЁЃ
ЯьгІИУдЊЪ§ОнЧыЧѓЃЌОпгаИУПщИББОЕФ DataNodes ЕижЗБЛЗЕЛиЁЃ
вЛЕЉНгЪеЕН DataNodes ЕФЕижЗЃЌFSDataInputStream РраЭЕФвЛИіЖдЯѓБЛЗЕЛиЕНПЭЛЇЖЫЁЃ FSDataInputStream АќКЌ DFSInputStream еташвЊДІРэНЛЛЅ DataNode КЭ NameNodeЁЃдкЩЯЭМЫљЪОЕФВНжш4ЃЌПЭЛЇЖЫЕїгУ read() ЗНЗЈЃЌетНЋЕМжТ DFSInputStream НЈСЂгыЕквЛИі DataNode ЮФМўЕФЕквЛИіПщСЌНгЁЃ
вдЪ§ОнСїЕФаЮЪНЖСШЁЪ§ОнЃЌЦфжаПЭЛЇЖЫЖрДЮЕїгУ “read() ” ЗНЗЈЁЃ read() ВйзїетИіЙ§ГЬвЛжБГжајЃЌжБЕНЫќЕНДяПщНсЪјЮЛжУЁЃ
вЛЕЉЕНФЃПщЕФНсЮВЃЌDFSInputStream ЙиБеСЌНгЃЌвЦЖЏЖЈЮЛЕНЯТвЛИі DataNode ЕФЯТвЛИіПщ
вЛЕЉПЭЛЇЖЫвбЖСШЁЭъГЩКѓЃЌЫќЛсЕїгУ close()ЗНЗЈЁЃ
HDFSаДВйзї
дкБОНкжаЃЌЮвУЧНЋСЫНтШчКЮЭЈЙ§ЕФЮФМўНЋЪ§ОнаДШыЕН HDFSЁЃ
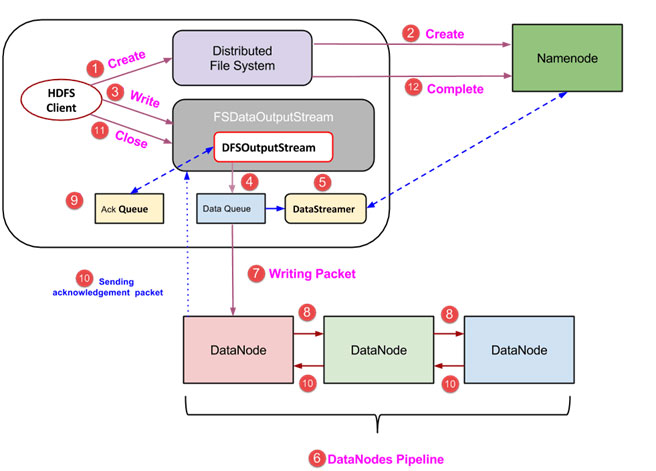
ПЭЛЇЖЫЭЈЙ§ЕїгУ DistributedFileSystemЖдЯѓЕФ create() ЗНЗЈДДНЈвЛИіаТЕФЮФМўЃЌВЂПЊЪМаДВйзї - дкЩЯУцЕФЭМжаЕФВНжш1
DistributedFileSystemЖдЯѓЪЙгУ RPC ЕїгУСЌНгЕН NameNodeЃЌВЂЦєЖЏаТЕФЮФМўДДНЈЁЃЕЋЪЧЃЌДЫЮФМўДДНЈВйзїВЛгыЮФМўШЮКЮПщЯрЙиСЊЁЃNameNode ЕФд№ШЮЪЧбщжЄЮФМў(Цфе§БЛДДНЈЕФ)ВЛДцдкЃЌВЂЧвПЭЛЇЖЫОпгае§ШЗШЈЯоРДДДНЈаТЮФМўЁЃШчЙћЮФМўвбОДцдкЃЌЛђепПЭЛЇЖЫВЛОпгазуЙЛЕФШЈЯоРДДДНЈвЛИіаТЕФЮФМўЃЌдђХзГі IOException ЕНПЭЛЇЖЫЁЃЗёдђВйзїГЩЙІЃЌВЂЧвИУЮФМўаТЕФМЧТМЪЧгЩ NameNode ДДНЈЁЃ
вЛЕЉ NameNode ДДНЈвЛЬѕаТЕФМЧТМЃЌЗЕЛиFSDataOutputStream РраЭЕФвЛИіЖдЯѓЕНПЭЛЇЖЫЁЃПЭЛЇЖЫЪЙгУЫќРДаДШыЪ§ОнЕН HDFSЁЃЪ§ОнаДШыЗНЗЈБЛЕїгУ(ЭМжаЕФВНжш3)ЁЃ
FSDataOutputStreamАќКЌDFSOutputStreamЖдЯѓЃЌЫќЪЙгУ DataNodes КЭ NameNode ЭЈаХКѓВщевЁЃЕБПЭЛЇЛњМЬајаДШыЪ§ОнЃЌDFSOutputStream МЬајДДНЈетИіЪ§ОнАќЁЃетаЉЪ§ОнАќСЌНгХХЖгЕНвЛИіЖгСаБЛГЦЮЊ DataQueue
ЛЙгавЛИіУћЮЊ DataStreamer зщМўЃЌгУгкЯћКФDataQueueЁЃDataStreamer вВвЊЧѓ NameNode ЗжХфаТЕФПщЃЌМ№бЁ DataNodes гУгкИДжЦЁЃ
ЯждкЃЌИДжЦЙ§ГЬЪМгкЪЙгУ DataNodes ДДНЈвЛИіЙмЕРЁЃ дкЮвУЧЕФР§згжаЃЌбЁдёСЫИДжЦЫЎЦН3ЃЌвђДЫга 3 Иі DataNodes ЙмЕРЁЃ
ЫљЪі DataStreamer зЂШыАќЗжГЩЕНЕквЛИі DataNode ЕФЙмЕРжаЁЃ
дкУПИі DataNode ЕФЙмЕРжаДцДЂЪ§ОнАќНгЪеВЂЭЌбљзЊЗЂдкЕкЖўИі DataNode ЕФЙмЕРжаЁЃ
СэвЛИіЖгСаЃЌ“Ack Queue”ЪЧгЩ DFSOutputStream БЃГжДцДЂЃЌЫќУЧЪЧ DataNodes ЕШД§ШЗШЯЕФЪ§ОнАќЁЃ
вЛЕЉШЗШЯдкЖгСажаЕФЗжзщДгЫљга DataNodes вбНгЪедкЙмЕРЃЌЫќДг 'Ack Queue' ЩОГ§ЁЃдкШЮКЮ DataNode ЗЂЩњЙЪеЯЪБЃЌДгЖгСажаЕФАќжиаТгУгкВйзїЁЃ
дкПЭЛЇЖЫЕФЪ§ОнаДШыЭъГЩКѓЃЌЫќЛсЕїгУclose()ЗНЗЈ(Ек9ВНЭМжа)ЃЌЕїгУclose()НсЙћНјШыЕНЧхРэЛКДцЪЃгрЪ§ОнАќЕНЙмЕРжЎКѓЕШД§ШЗШЯЁЃ
вЛЕЉЪеЕНзюжеШЗШЯЃЌNameNode СЌНгИцЫпЫќИУЮФМўЕФаДВйзїЭъГЩЁЃ
ЪЙгУJAVA APIЗУЮЪHDFS
дкБОНкжаЃЌЮвУЧРДСЫНт Java НгПкВЂгУЫќУЧРДЗУЮЪHadoopЕФЮФМўЯЕЭГЁЃ
ЮЊСЫЪЙгУБрГЬЗНЪНгы Hadoop ЮФМўЯЕЭГНјааНЛЛЅЃЌHadoop ЬсЙЉЖржж Java РрЁЃorg.apache.hadoop.fsАќжаАќКЌВйзн Hadoop ЮФМўЯЕЭГжаЕФЮФМўРрЙЄОпЁЃетаЉВйзїАќРЈЃЌДђПЊЃЌЖСШЁЃЌаДШыЃЌКЭЙиБеЁЃЪЕМЪЩЯЃЌЖдгк Hadoop ЮФМў API ЪЧЭЈгУЕФЃЌПЩвдРЉеЙЕН HDFS ЕФЦфЫћЮФМўЯЕЭГНЛЛЅЁЃ
БрГЬДг HDFS ЖСШЁЮФМў
java.net.URL ЖдЯѓЪЧгУгкЖСШЁЮФМўЕФФкШнЁЃЪзЯШЃЌЮвУЧашвЊШУ Java ЪЖБ№ Hadoop ЕФ HDFS URLМмЙЙЁЃетЪЧЭЈЙ§ЕїгУ URL ЖдЯѓЕФ setURLStreamHandlerFactoryЗНЗЈКЭ FsUrlStreamHandlerFactory ЕФвЛИіЪЕР§ч§ДЋЕнИјЫќЁЃДЫЗНЗЈжЛашвЊжДаавЛДЮдкУПИіJVMЃЌвђДЫЃЌЫќБЛЗтБедквЛИіОВЬЌПщжаЁЃ
ЪОР§ДњТы

етЖЮДњТыгУгкДђПЊКЭЖСШЁЮФМўЕФФкШнЁЃHDFSЮФМўЕФТЗОЖзїЮЊУќСюааВЮЪ§ДЋЕнИјИУГЬађЁЃ
ЪЙгУУќСюааНчУцЗУЮЪHDFS
етЪЧгы HDFS НЛЛЅЕФзюМђЕЅЕФЗНЗЈжЎвЛЁЃ УќСюааНгПкжЇГжЖдЮФМўЯЕЭГВйзїЃЌР§ШчЃКШчЖСШЁЮФМўЃЌДДНЈФПТМЃЌвЦЖЏЮФМўЃЌЩОГ§Ъ§ОнЃЌВЂСаГіФПТМЁЃ
ПЩвджДаа '$HADOOP_HOME/bin/hdfs dfs -help' РДЛёЕУУПвЛИіУќСюЕФЯъЯИАяжњЁЃетРя, 'dfs' HDFSЪЧвЛИіshellУќСюЃЌЫќжЇГжЖрИізгУќСюЁЃЪзЯШвЊЦєЖЏ Haddop ЗўЮё(ЪЙгУ hduser_гУЛЇ)ЃЌжДааУќСюШчЯТЃК
hduser_@ubuntu:~$ su hduser_ hduser_@ubuntu:~$ $HADOOP_HOME/sbin/start-dfs.sh
hduser_@ubuntu:~$ $HADOOP_HOME/sbin/start-yarn.sh
|
вЛаЉЙуЗКЪЙгУЕФУќСюЕФСаБэШчЯТ
1. ДгБОЕиЮФМўЯЕЭГИДжЦЮФМўЕН HDFS
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -copyFromLocal temp.txt /
|
ДЫУќСюНЋЮФМўДгБОЕиЮФМўЯЕЭГПНБД temp.txt ЮФМўЕН HDFSЁЃ
2. ЮвУЧПЩвдЭЈЙ§вдЯТУќСюСаГівЛИіФПТМЯТДцдкЕФЮФМў -ls
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -ls /
|

ЮвУЧПЩвдПДЕНвЛИіЮФМў 'temp.txt“(жЎЧАИДжЦ)БЛСадк”/“ФПТМЁЃ
3. вдЯТУќСюНЋЮФМўДг HDFS ПНБДЕНБОЕиЮФМўЯЕЭГ
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -copyToLocal /temp.txt
|
ЮвУЧПЩвдПДЕН temp.txt вбОИДжЦЕНБОЕиЮФМўЯЕЭГЁЃ
4. вдЯТУќСюгУРДДДНЈаТЕФФПТМ
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -mkdir /mydirectory
|
НгЯТРДМьВщЪЧЗёвбОНЈСЂСЫФПТМЁЃЯждкЃЌгІИУжЊЕРдѕУДзіСЫАЩЃП
|









