|
БОНЬГЬжаЃЌЮвУЧНЋЬжТл Pig & Hive
PigМђНщ
дкMap ReduceПђМмЃЌашвЊЕФГЬађНЋЦфзЊЛЏЮЊвЛЯЕСа Map КЭ ReduceНзЖЮЁЃ ЕЋЪЧЃЌетВЛЪЧвЛжжБрГЬФЃаЭЃЌЫќБЛЪ§ОнЗжЮіЫљЪьЯЄЁЃвђДЫЃЌЮЊСЫУжВЙетвЛВюОрЃЌвЛИіГщЯѓИХФюНа Pig НЈСЂдк Hadoop жЎЩЯЁЃ
PigЪЧвЛжжИпМЖБрГЬгябдЃЌЗжЮіДѓЪ§ОнМЏЗЧГЃгагУЁЃ Pig ЪЧбХЛЂХЌСІПЊЗЂЕФНсЙћ
Pig ЪЙШЫУЧФмЙЛИќзЈзЂгкЗжЮіДѓСПЪ§ОнМЏКЭЛЈИќЩйЕФЪБМфРДаДmap-reduceГЬађЁЃ
РрЫЦжэГдЖЋЮїЃЌPig БрГЬгябдЕФФПЕФЪЧПЩвддкШЮКЮРраЭЕФЪ§ОнЙЄзїЁЃ
Pig гЩСНВПЗжзщГЩЃК
Pig LatinЃЌетЪЧвЛжжгябд
дЫааЛЗОГЃЌгУгкдЫааPigLatinГЬађ
Pig Latin ГЬађгЩвЛЯЕСаВйзїЛђБфЛЛгІгУЕНЪфШыЪ§ОнЃЌвдВњЩњЪфГіЁЃетаЉВйзїУшЪіБЛЗвыГЩПЩжДааЕНЪ§ОнСїЃЌгЩ Pig ЛЗОГжДааЁЃЯТУцЃЌетаЉзЊЛЛЕФНсЙћЪЧвЛЯЕСаЕФ MapReduce зївЕЃЌГЬађдБЪЧВЛжЊЕРЕФЁЃЫљвдЃЌдкФГжжГЬЖШЩЯЃЌPig дЪаэГЬађдБЙизЂЪ§ОнЃЌЖјВЛЪЧжДааЙ§ГЬЁЃ
Pig Latin ЪЧвЛжжЯрЖдгВЭІЕФгябдЃЌЫќВЩгУЪьЯЄЕФЙиМќзжРДДІРэЪ§ОнЃЌР§ШчЃЌJoin, Group КЭ FilterЁЃ
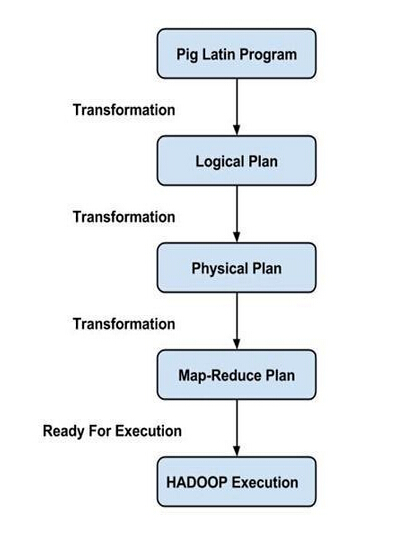
жДааФЃЪНЃК
Pig гаСНжжжДааФЃЪНЃК
БОЛњФЃЪНЃКдкДЫФЃЪНЯТЃЌPig дЫаадкЕЅИіJVMЃЌВЂЪЙгУБОЕиЮФМўЯЕЭГЁЃетжжФЃЪНжЛЪЪКЯЪЙгУ Pig аЁЪ§ОнМЏКЯЗжЮіЁЃ
Map ReduceФЃЪНЃКдкДЫФЃЪНЯТЃЌаДдк Pig Latin ЕФВщбЏБЛЗвыГЩMapReduce зївЕЃЌВЂ Hadoop МЏШКЩЯдЫаа(МЏШКПЩФмЪЧЮБЛђЭъШЋЗжВМЪНЕФ)ЁЃ MapReduce ФЃЪНЭъШЋЗжВМЪНМЏШКЖдДѓаЭЪ§ОнМЏдЫаа Pig КмгагУЕФЁЃ
HIVE НщЩм
дкФГжжГЬЖШЩЯЪ§ОнМЏЪеМЏЕФДѓаЁВЂдкаавЕгУгкЩЬвЕжЧФмЗжЮіе§дкдіГЄЃЌЫќЪЙДЋЭГЕФЪ§ОнВжПтНтОіЗНАИИќМгАКЙѓЁЃHADOOPгыMapReduceПђМмЃЌБЛгУгкДѓаЭЪ§ОнМЏЗжЮіЕФЬцДњНтОіЗНАИЁЃЫфШЛЃЌHadoop ЕиХгДѓЕФЪ§ОнМЏЩЯЙЄзїжЄУїЪЧЗЧГЃгагУЕФЃЌMapReduceПђМмЪЧЗЧГЃЕЭМЖБ№ВЂЧвЫќашвЊГЬађдББраДздЖЈвхГЬађЃЌетЕМжТФбвдЮЌЛЄКЭжигУЁЃ Hive ОЭЪЧЮЊГЬађдБЩшМЦЕФЁЃ
Hive бнБфЮЊЛљгкHadoopЕФMap-Reduce ПђМмжЎЩЯЕФЪ§ОнВжПтНтОіЗНАИЁЃ
Hive ЬсЙЉСЫРрЫЦгкSQLЕФЩљУїадгябдЃЌНазїЃКHiveQL, гУгкБэДяЕФВщбЏЁЃЪЙгУ Hive-SQLЃЌгУЛЇФмЙЛЗЧГЃШнвзЕиНјааЪ§ОнЗжЮіЁЃ
Hive в§ЧцБрвыетаЉВщбЏЕН map-reduceзївЕжаВЂдк Hadoop ЩЯжДааЁЃДЫЭтЃЌздЖЈвх map-reduce НХБОЃЌвВПЩвдВхШыВщбЏЁЃHiveдЫааДцДЂдкБэжаЃЌЫќгЩЛљБОЪ§ОнРраЭЃЌШчЪ§зщКЭгГЩфМЏКЯЕФЪ§ОнРраЭЕФЪ§ОнЁЃ
ХфжУЕЅдЊДјгавЛИіУќСюааshellНгПкЃЌПЩгУгкДДНЈБэВЂжДааВщбЏЁЃ
Hive ВщбЏгябдЪЧРрЫЦгкSQLЃЌЫќжЇГжзгВщбЏЁЃЭЈЙ§HiveВщбЏгябдЃЌПЩвдЪЙгУ MapReduce ПчHive БэСЌНгЁЃЫќгаРрЫЦКЏЪ§МђЕЅЕФSQLжЇГж- CONCAT, SUBSTR, ROUND ЕШЕШ, ОлКЯКЏЪ§ - SUM, COUNT, MAX etcЁЃЫќЛЙжЇГжGROUP BYКЭSORT BYзгОфЁЃ СэЭтЃЌвВПЩвддкХфжУЕЅдЊВщбЏгябдБраДгУЛЇЖЈвхЕФЙІФмЁЃ
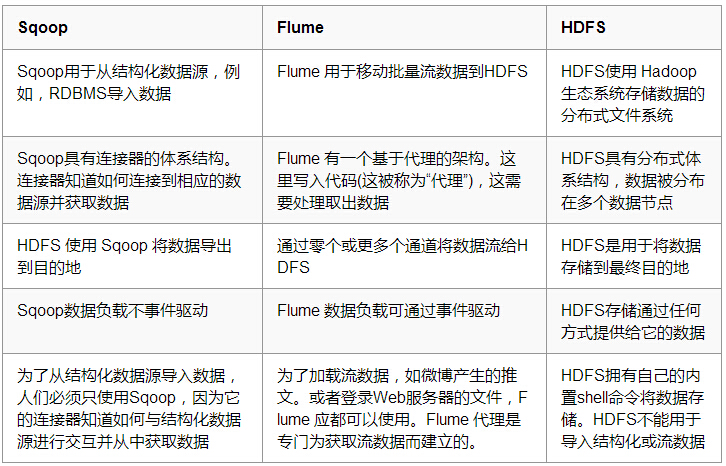
MapReduceЃЌPig КЭ Hive ЕФБШНЯ
|









