|
БОНЬГЬЪЧвдUbuntu ЯЕЭГзїЮЊАВзАНВНтЛЗОГЃЌЮЊСЫМѕЩйВЛБивЊЕФТщЗГЃЌЧыФњ АВзАUbuntu ВЂФме§ГЃЦєЖЏНјШыЯЕЭГЁЃЭЌЪБвВБиаывЊ АВзАJavaЁЃ
вЛЁЂЬэМг Hadoop ЯЕЭГгУЛЇзщКЭгУЛЇ
ЪЙгУвдЯТУќСюдкжеЖЫжажДаавдЯТУќСюРДЯШДДНЈвЛИігУЛЇзщЃК
yiibai@ubuntu:~$ sudo addgroup hadoop_
|
ВйзїНсЙћШчЯТЃК

ЪЙгУвдЯТУќСюРДЬэМггУЛЇЃК
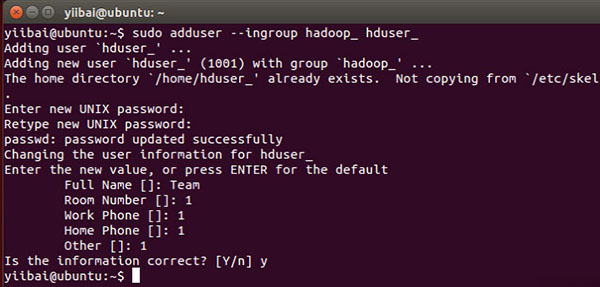
yiibai@ubuntu:~$ sudo adduser --ingroup hadoop_ hduser_
|
ЪфШыФњЕФУмТыЃЌаеУћКЭЦфЫћЯъЯИаХЯЂЁЃ
ЖўЁЂХфжУSSH
ЮЊСЫдкМЏШКЙмРэНкЕуЃЌHadoopашвЊSSHЗУЮЪ
ЪзЯШЃЌЧаЛЛгУЛЇЃЌЪфШывдЯТУќСюЃК
yiibai@ubuntu:~$ su hduser_
|
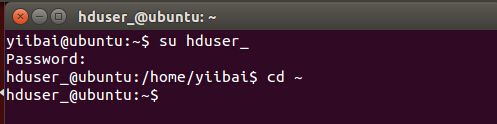
вдЯТетИіУќСюНЋДДНЈвЛИіаТЕФУмдПЁЃ
hduser_@ubuntu:~$ ssh-keygen -t rsa -P ""
|
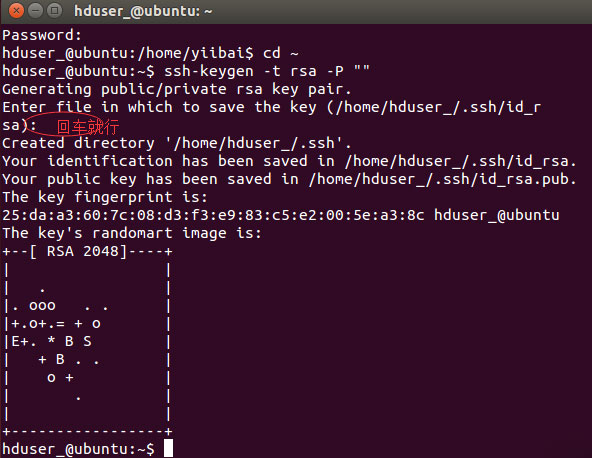
ЪЙгУДЫУмдПЦєгУSSHЗУЮЪБОЕиМЦЫуЛњЁЃ
hduser_@ubuntu:~$ cat /home/hduser_/.ssd/id_rsa.pub >> /home/hduser_/.ssh/authorized_keys
|

ЯждкЃЌВтЪдSSHЩшжУЭЈЙ§“hduser”гУЛЇСЌНгЕНlocahostЁЃ
hduser_@ubuntu:~$ ssh localhost
|
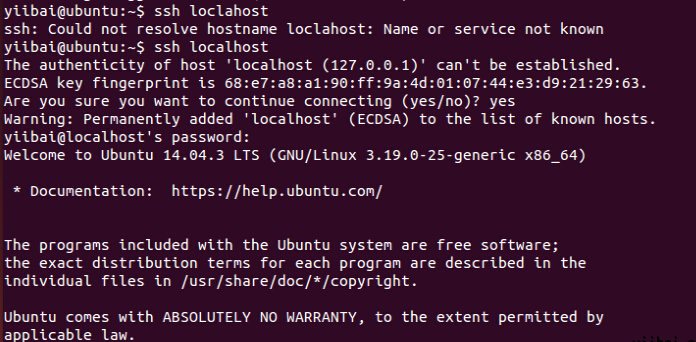
зЂвтЃК
ЧызЂвтЃЌжДаа 'ssh localhost' УќСюКѓШчЙћПДЕНЯТУцЕФДэЮѓЯьгІ, ПЩФм SSH дкДЫЯЕЭГВЛПЩгУЁЃ

РДНтОіЩЯУцетИіЮЪЬтЃЌАВзА SSH ЗўЮё -
ЧхГ§ SSH ЪЙгУвдЯТУќСюЃК
hduser_@ubuntu:~$ sudo apt-get purge openssh-server
|
дкАВзАПЊЪМЧАЧхГ§ SSH ЗўЮёЃЌетЪЧвЛИіКмКУЕФзіЗЈ(НЈвщ)ЃЌШчЙћгіЕН“
is not in the sudoers file ...“ЬсЪОЃЌЧыЪЙгУгаsudo ЕФгУЛЇРДжДааЃЌ
етРяЪЙгУЕФгУЛЇЪЧЃКyiibai
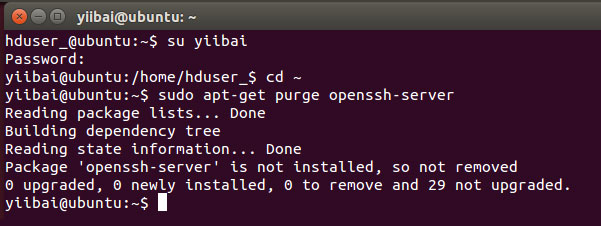
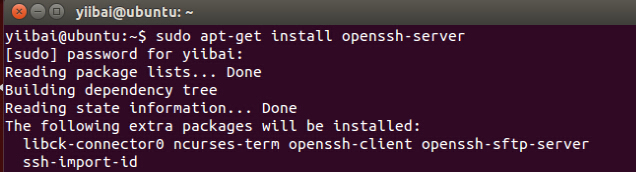
ЪЙгУвдЯТУќСюРДАВзАSSHЃЌЪЙгУвдЯТУќСюЃК
yiibai@ubuntu:~$ sudo apt-get install openssh-server
|
Ш§ЁЂЯТдиHadoop
дкфЏРРЦїжаДђПЊЭјжЗЃКhttp://hadoop.apache.org/releases.html
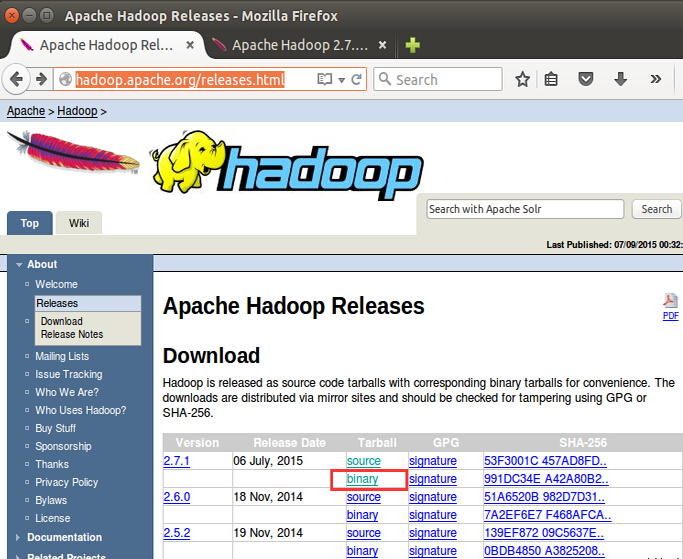
бЁдёвЛИізюаТ 2.7.1 ЕФЮШЖЈАцБО(stable)ЕФЖўНјжЦАќЯТдиЃЌШчЯТЃК
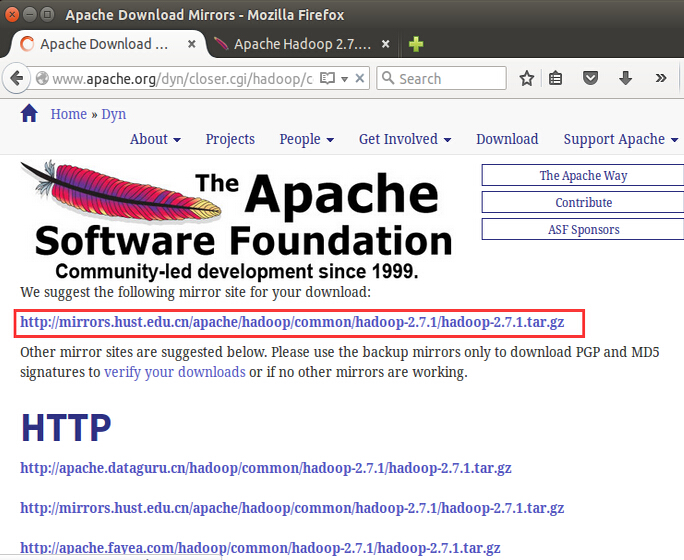
ЯТдиЭъГЩКѓЃЌФЌШЯНЋЮФМўЗХдк /home/yiibai/DownloadsЃЌШчЯТЭМЫљЪОЃК
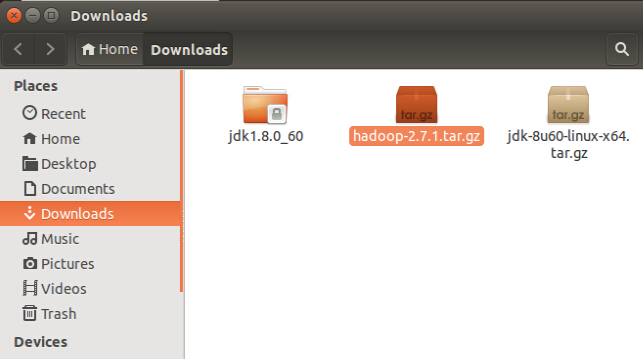
ЯждкНјШыЕНЕНАќКЌtarЮФМўЕФФПТМЃЌзМБИНтбЙ tar.gz ЮФМўЃК
yiibai@ubuntu:~$ cd /home/yiibai/Downloads
|
ЪЙгУвдЯТУќСюНтбЙЮФМўАќЃК
yiibai@ubuntu:~$ sudo tar xzf hadoop-2.7.1.tar.gz
|
ЯждкжиУќУћ hadoop-2.2.0 ЮЊ hadoop
yiibai@ubuntu:~$ sudo mv hadoop-2.7.1 /usr/local/hadoop
|
ИќИФЮФМўгУЛЇЪєадЃЌжДаавдЯТУќСюЃК
yiibai@ubuntu:~$ cd /usr/local yiibai@ubuntu:~$ sudo chown -R hduser_:hadoop_ hadoop
|
ЕНетРяЃЌhadoopЮФМўЕФЯрЙиЙЄзївбОзМБИКУЃЌНгЯТРДЮвУЧЛЙвЊзівЛаЉЙиМќЕФЩшжУЁЃ
ЫФЁЂаоИФ ~/.bashrc ЮФМў
ЬэМгвдЯТетаЉааЕН ~/.bashrc ЮФМўЕФФЉЮВЃЌФкШнШчЯТЫљЪОЃК

дкжеЖЫЯТжДаавдЯТУќСюЃЌДђПЊБрМЦїВЂНЋЩЯУцЕФФкШнМгШыЕНЮФМўЕФЕзВПЃЌШчЯТЭМЫљЪОЃК
yiibai@ubuntu:~$ vi ~/.bashrc
|
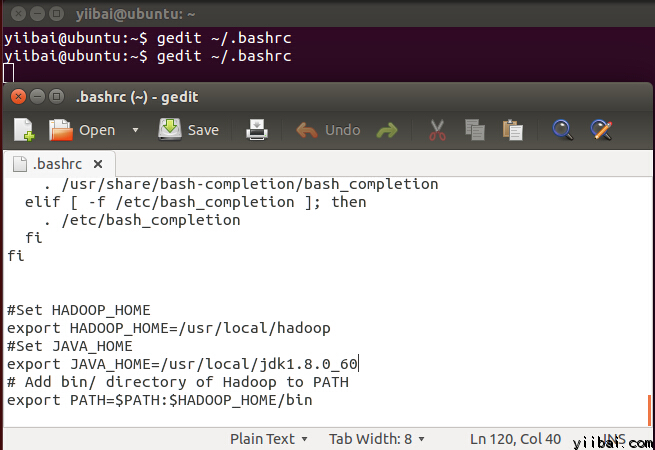
ЯждкЃЌЪЙгУЯТУцЕФУќСюЛЗОГХфжУ
yiibai@ubuntu:~$ . ~/.bashrc
|
ЮхЁЂХфжУЙиСЊHDFS
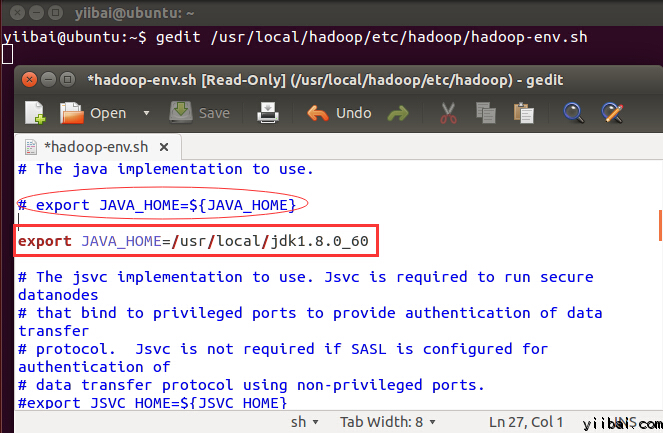
ЩшжУ JAVA_HOME дкЮФМў /usr/local/hadoop/etc/hadoop/hadoop-env.sh жаЃЌЪЙгУвдЯТааДњЬцЃЌМДаДЩЯЭъећЕФ Java АВзАТЗОЖЁЃШчЯТЫљЪОЃК
дк $HADOOP_HOME/etc/hadoop/core-site.xml ЮФМўжаЛЙгаСНИіВЮЪ§ашвЊЩшжУЃК
1. 'hadoop.tmp.dir' - гУгкжИЖЈФПТМШУ Hadoop РДДцДЂЦфЪ§ОнЮФМўЁЃ
2. 'fs.default.name' - жИЖЈФЌШЯЕФЮФМўЯЕЭГ
ЮЊСЫЩшжУСНИіВЮЪ§ЃЌДђПЊЮФМў core-site.xml
yiibai@ubuntu:~$ sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
|
ПНБДвдЯТЫљгаааЕФФкШнЗХШыЕНБъЧЉ <configuration></configuration> жаМфЁЃ
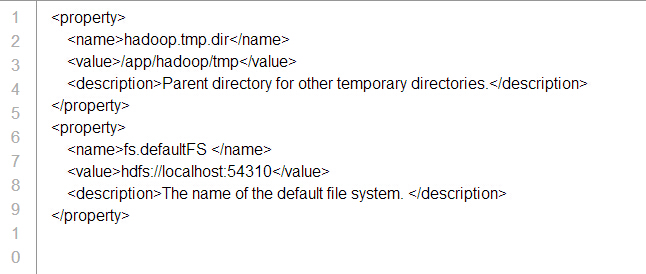
НсЙћШчЯТЭМЫљЪОЃК

НјШыЕНФПТМЃК/usr/local/hadoop/etc/hadoopЃЌЪЙгУШчЯТЕФУќСюЃК
yiibai@ubuntu:~$ cd /usr/local/hadoop/etc/hadoop yiibai@ubuntu:/usr/local/hadoop/etc/hadoop$
|
ЯждкДДНЈвЛИіФПТМЃЌШчЩЯУцХфжУ core-site.xml жаЪЙгУЕФФПТМЃК/app/hadoop/tmp
yiibai@ubuntu:/usr/local/hadoop/etc/hadoop$ sudo mkdir -p /app/hadoop/tmp
|
ЪкгшШЈЯоФПТМ /app/hadoop/tmpЃЌжДааШчЯТЕФУќСюЃК
yiibai@ubuntu:~$ sudo chown -R hduser_:hadoop_ /app/hadoop/tmp yiibai@ubuntu:~$ sudo chmod 750 /app/hadoop/tmp
|
СљЁЂMap Reduce ХфжУ
дкЩшжУетИіХфжУжЎЧАЃЌ ЮвУЧашвЊЩшжУ HADOOP_HOME ЕФТЗОЖЃЌжДаавдЯТУќСюЃК
yiibai@ubuntu:~$ sudo gedit /etc/profile.d/hadoop.sh
|
ШЛКѓЪфШывдЯТвЛааЃЌ
export HADOOP_HOME=/usr/local/hadoop
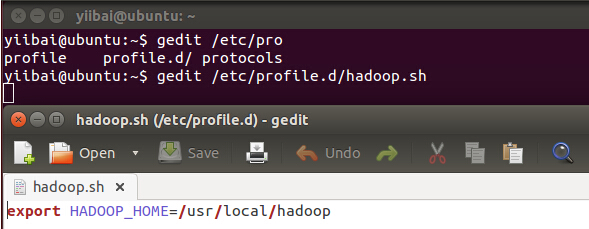
дйжДаавдЯТУќСюЃК
yiibai@ubuntu:~$ sudo chmod +x /etc/profile.d/hadoop.sh
|
ЭЫГіУќСюаажеЖЫдйДЮНјШыЃЌВЂЪфШывдЯТУќСюЃКecho $HADOOP_HOME вдбщжЄ hadoop ЕФТЗОЖЃК
yiibai@ubuntu:~$ echo $HADOOP_HOME /usr/local/hadoop
|
ЯждкИДжЦЮФМўЃЌжДаавдЯТУќСюЃК
yiibai@ubuntu:~$ sudo cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template
$HADOOP_HOME/etc/hadoop/mapred-site.xml
|
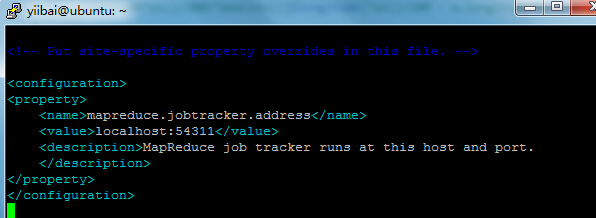
ЪЙгУvi ДђПЊЮФМў mapred-site.xml
yiibai@ubuntu:~$ sudo vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
|
ЬэМгвдЯТЕФЩшжУФкШнЕНБъЧЉ<configuration> КЭ </configuration> жаЃЌШчЯТЭМЫљЪОЃК

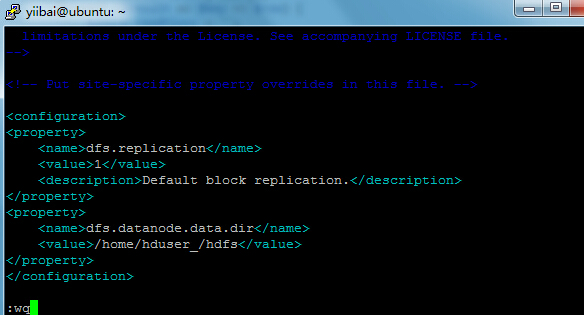
ДђПЊ $HADOOP_HOME/etc/hadoop/hdfs-site.xml ЮФМўШчЯТЃК
yiibai@ubuntu:~$ sudo vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
|
ЬэМгвдЯТЕФЩшжУФкШнЕНБъЧЉ<configuration> КЭ </configuration> жаЃЌШчЯТЭМЫљЪОЃК

ДДНЈвдЩЯХфжУжИЖЈЕФФПТМВЂЪкШЈФПТМИјгУЛЇЃЌЪЙгУвдЯТУќСюЃК
yiibai@ubuntu:~$ sudo mkdir -p /home/hduser_/hdfs
yiibai@ubuntu:~$ sudo chown -R hduser_:hadoop_ /home/hduser_/hdfs
yiibai@ubuntu:~$ sudo chmod 750 /home/hduser_/hdfs
|
ЦпЁЂИёЪНЛЏHDFS
дкЕквЛЪЙгУ Hadoop жЎЧАЃЌашвЊЯШИёЪНЛЏ HDFSЃЌЪЙгУЯТУцЕФУќСю
yiibai@ubuntu:~$ $HADOOP_HOME/bin/hdfs namenode -format
|
жДааНсЙћШчЯТЭМЫљЪОЃК

ЪфШыЃКyЃЌМЬЭљЯТ...
зЂЃКПЩФмЛсгіЕНвЛаЉЬсЪОДэЮѓЃК“java.io.IOException: Cannot create directory /app/hadoop/tmp/dfs/name/current...”ЃЌЧыжДаавдЯТУќСюРДДДНЈФПТМЃК
yiibai@ubuntu:~$ sudo mkdir -p /app/hadoop/tmp/dfs/name/current
yiibai@ubuntu:~$ sudo chmod -R a+w /app/hadoop/tmp/dfs/name/current/
|
АЫЁЂ ЦєЖЏ Hadoop ЕФЕЅНкЕуМЏШК
ЪЙгУвдЯТУќСюЦєЖЏcHadoop ЕФЕЅНкЕуМЏШК(ЪЙгУ hduser_ гУЛЇРДЦєЖЏ)ЃЌШчЯТЃК
hduser_@ubuntu:~$ $HADOOP_HOME/sbin/start-dfs.sh
|
ЩЯУцЕФУќСюЪфГіНсЙћШчЯТЫљЪОЃК
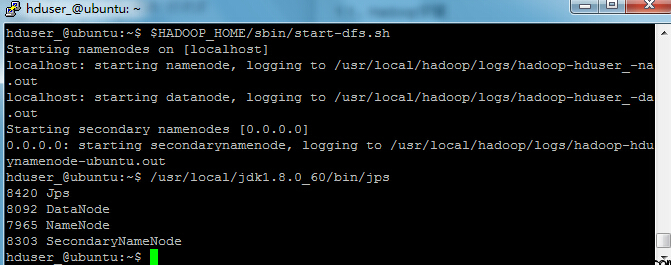
НгЯТРДдйжДааУќСюЃК
hduser_@ubuntu:~$ $HADOOP_HOME/sbin/start-yarn.sh
|
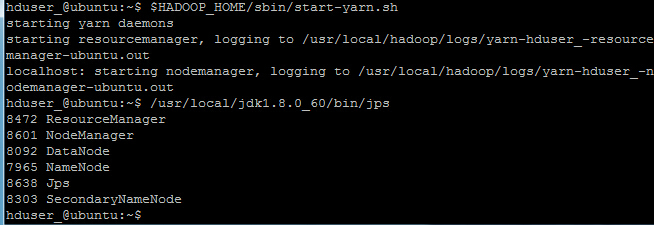
ЯждкЪЙгУ 'jps' ЙЄОп/УќСю, бщжЄЪЧЗёЫљга Hadoop ЯрЙиЕФНјГЬе§дкдЫааЁЃ
hduser_@ubuntu:~$ /usr/local/jdk1.8.0_60/bin/jps
|
ШчЙћ Hadoop ГЩЙІЦєЖЏЃЌФЧУД jps ЪфГігІЯдЪОЃК NameNode, NodeManager, ResourceManager, SecondaryNameNode, DataNode.
ОХЁЂЭЃжЙ/ЙиБе Hadoop
hduser_@ubuntu:~$ $HADOOP_HOME/sbin/stop-dfs.sh
|

hduser_@ubuntu:~$ $HADOOP_HOME/sbin/stop-yarn.sh
|

the end.
|









