|
ЮЪЬтГТЪіЃК
евГіЯњЭљИїИіЙњМвЩЬЦЗЪ§СПЁЃ
ЪфШы: ЮвУЧЕФюБЪфШыЪ§ОнМЏКЯЪЧвЛИі CSV ЮФМў, Sales2014.csv
ЧАЬсЬѕМўЃК
1.БОНЬГЬЪЧдкLinuxЩЯПЊЗЂ - UbuntuВйзїЯЕЭГ
2.вбОАВзАСЫHadoop(БОНЬГЬЪЙгУАцБО2.7.1)
3.ЯЕЭГЩЯвбАВзАСЫJava(БОНЬГЬЪЙгУ JDK1.8.0)ЁЃ
дкЪЕМЪВйзїЙ§ГЬжаЃЌЪЙгУЕФгУЛЇЪЧ'hduser_“(ДЫгУЛЇЪЙгУ Hadoop)ЁЃ
yiibai@ubuntu:~$ su hduser_
|
ВНжш:
1.ДДНЈвЛИіаТЕФФПТМУћГЦЪЧЃКMapReduceTutorial
hduser_@ubuntu:~$ sudo mkdir MapReduceTuorial
|
ЪкгшШЈЯо
hduser_@ubuntu:~$ sudo chmod -R 777 MapReduceTutorial
|
ЯТдиЯрЙиЮФМўЃКЯТди Java ГЬађЮФМўЃЌПНБДвдЯТЮФМўЃКSalesMapper.java, SalesCountryReducer.java КЭ SalesCountryDriver.java ЕН MapReduceTutorial ФПТМжаЃЌ
МьВщЫљгаетаЉЮФМўЕФЮФМўШЈЯоЪЧЗёе§ШЗЃК
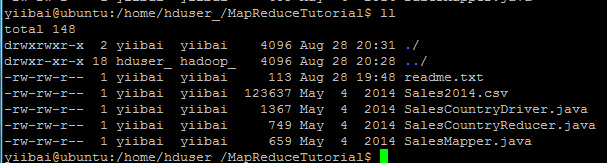
ШчЙћ“ЖСШЁ”ШЈЯоШБЩйПЩжиаТдйЪкгшШЈЯоЃЌжДаавдЯТУќСюЃК
yiibai@ubuntu:/home/hduser_/MapReduceTutorial$ sudo chmod +r *
|
2.ЕМГіРрТЗОЖ
hduser_@ubuntu:~/MapReduceTutorial$ export CLASSPATH="$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.1.jar:
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.1.jar:
$HADOOP_HOME/share/hadoop/common/hadoop-common-2.7.1.jar:
~/MapReduceTutorial/SalesCountry/*:$HADOOP_HOME/lib/*"
hduser_@ubuntu:~/MapReduceTutorial$
|
3. БрвыJavaЮФМў(етаЉЮФМўДцдкгкФПТМЃКFinal-MapReduceHandsOn). ЫќЕФРрЮФМўНЋБЛЗХдкАќФПТМЃК
hduser_@ubuntu:~/MapReduceTutorial$ javac -d .
SalesMapper.java SalesCountryReducer.java SalesCountryDriver.java
|
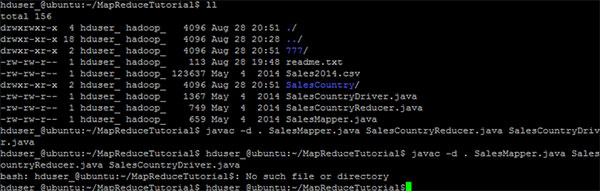
АВШЋЕиКіТдДЫОЏИцЃК
ДЫБрвыНЋДДНЈвЛИіУћГЦгыJavaдДЮФМў(дкЮвУЧЕФР§згМДЃЌSalesCountry)жИЖЈАќУћГЦЕФФПТМЃЌВЂАбЫљгаБрвыЕФРрЮФМўдкРяУцЃЌвђДЫетИіФПТМвЊдкБрвыЮФМўЧАДДНЈЁЃ
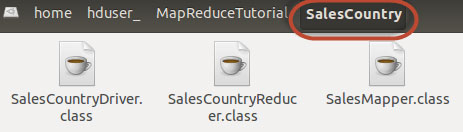
НгЯТРДЃК
ДДНЈвЛИіаТЕФЮФМўЃКManifest.txt
hduser_@ubuntu:~/MapReduceTutorial$ vi Manifest.txt
ЬэМгвдЯТФкШнЕНЮФМўжаЃК
Main-Class: SalesCountry.SalesCountryDriver
|
SalesCountry.SalesCountryDriver ЪЧжїРрЕФУћГЦЁЃЧызЂвтЃЌБиаыМќШыЛиГЕМќЃЌдкИУааЕФФЉЮВЁЃ
ЯТвЛВНЃКДДНЈвЛИі jar ЮФМў
hduser_@ubuntu:~/MapReduceTutorial$ $JAVA_HOME/bin/jar cfm ProductSalePerCountry.jar Manifest.txt SalesCountry/*.class
МьВщЫљДДНЈЕФ jar ЮФМўЃЌНсЙћШчЯТЃК

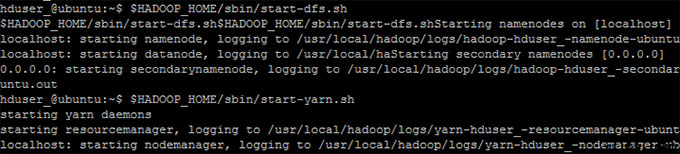
6. ЦєЖЏ Hadoop
hduser_@ubuntu:~$ $HADOOP_HOME/sbin/start-dfs.sh
hduser_@ubuntu:~$ $HADOOP_HOME/sbin/start-yarn.sh
|
7. ПНБДЮФМў Sales2014.csv ЕН ~/inputMapReduce
hduser_@ubuntu:~$ mkdir inputMapReduce
hduser_@ubuntu:~$ cp MapReduceTutorial/Sales2014.csv ./inputMapReduce/Sales2014.csv
|
ЯждкЪЙгУвдЯТУќСюРДПНБД ~/inputMapReduce ЕН HDFS.
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -copyFromLocal ~/inputMapReduce /
|
ЮвУЧПЩвдЗХаФЕиКіТдДЫОЏИцЁЃбщжЄЮФМўЪЧЗёеце§ИДжЦУЛгаЃП
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -ls /inputMapReduce
|
8. дЫааMapReduce зївЕ
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hadoop jar ProductSalePerCountry.jar
/inputMapReduce /mapreduce_output_sales
|
етНЋдк HDFS ЩЯДДНЈвЛИіЪфГіФПТМЃЌУћЮЊmapreduce_output_salesЁЃДЫФПТМЕФЮФМўФкШнНЋАќКЌУПИіЙњМвЕФВњЦЗЯњЪлЁЃ
9. НсЙћПЩвдЭЈЙ§УќСюНчУцжаПЩвдПДЕН
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -cat /mapreduce_output_sales/part-00000
|
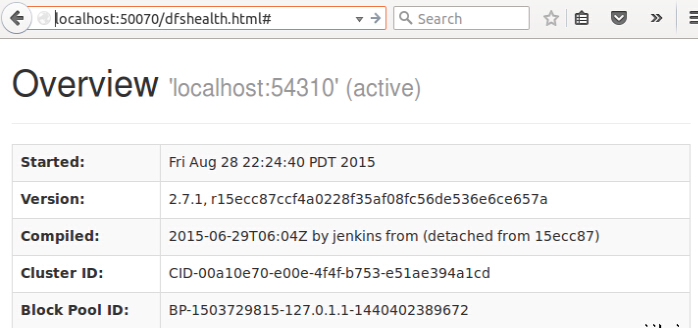
НсЙћвВПЩвдЭЈЙ§ Web НчУцПДЕНЃЌДђПЊ Web фЏРРЦїЃЌЪфШыЭјжЗЃКhttp://localhost:50070/dfshealth.jsp ЃЌНсЙћШчЯТЃК
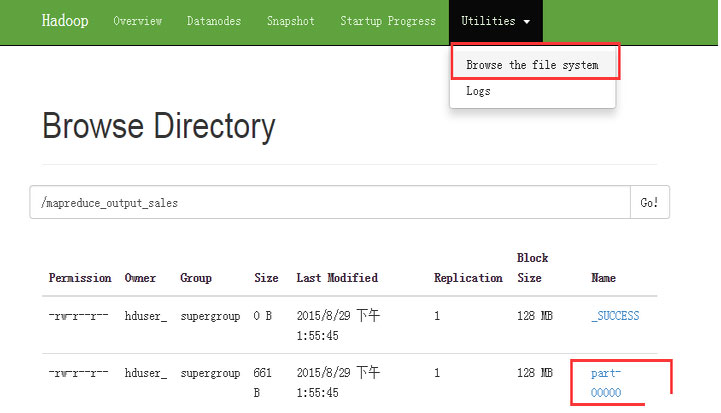
ЯждкбЁдё 'Browse the filesystem' ВЂЕМКНЕН /mapreduce_output_sales ШчЯТЃК
ДђПЊ part-r-00000 ЃЌШчЯТЭМЫљЪОЃК
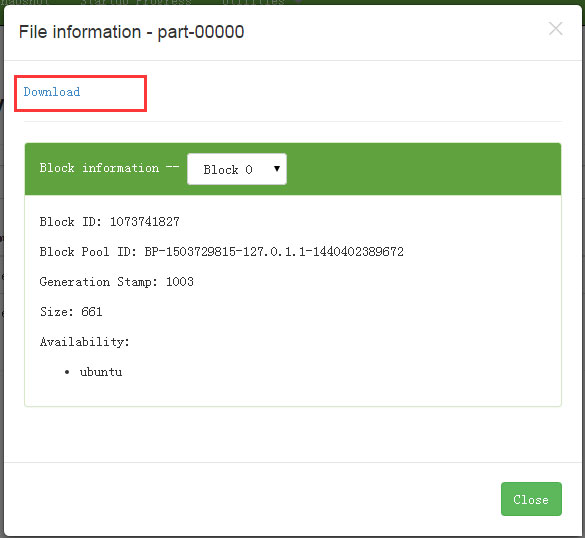
ЯТдиКѓЃЌВщПДНсЙћФкШнЁЃ
|









