|
етРягаСНИіЪ§ОнМЏКЯдкСНИіВЛЭЌЕФЮФМўжаЃЌШчЯТЫљЪОЃК
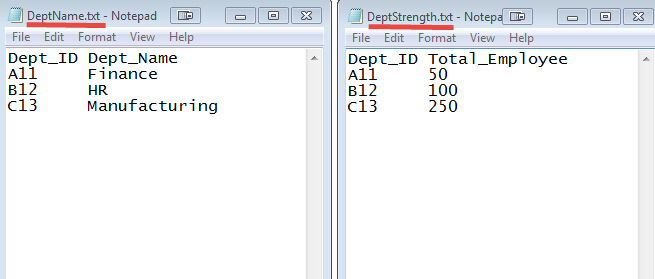
DEPT_ID МќдкетСНИіЮФМўжаГЃМћЕФЁЃ
ФПБъЪЧЪЙгУ MapReduce МгШыРДзщКЯетаЉЮФМўЁЃ
ЪфШы: ЮвУЧЕФЪфШыЪ§ОнМЏЪЧСНИіtxtЮФМўЃКDeptName.txt КЭ DepStrength.txt
ЯТдиЪфШыЮФМў
ЧАЬсЬѕМўЃК
БОНЬГЬЪЧдк Linux ЩЯПЊЗЂ - UbuntuВйзїЯЕЭГ
вбОАВзАЕФHadoop(БОНЬГЬЪЙгУ2.7.1АцБО)
JavaЕФПЊЗЂдЫааЛЗОГвбОдкЯЕЭГЩЯАВзА(БОНЬГЬЪЙгУЕФАцБОЪЧЃК1.8.0)
дкЮвУЧПЊЪМЪЕМЪВйзїжЎЧАЃЌЪЙгУЕФгУЛЇ 'hduser_'(ЪЙгУ Hadoop ЕФгУЛЇ)ЁЃ
yiibai@ubuntu:~$ su hduser_
|
ВНжш
Step 1) ИДжЦ zip ЮФМўЕНФњбЁдёЕФЮЛжУ
hduser_@ubuntu:/home/yiibai$ cp
/home/yiibai/Downloads/MapReduceJoin.tar.gz
/home/hduser_/ hduser_@ubuntu:/home/yiibai$ ls
/home/hduser_/
|
ВйзїЙ§ГЬМАНсЙћШчЯТЃК

Step 2) НтбЙЫѕZIPЮФМўЃЌЪЙгУвдЯТУќСюЃК
hduser_@ubuntu:~$ sudo tar -xvf MapReduceJoin.tar.gz
|
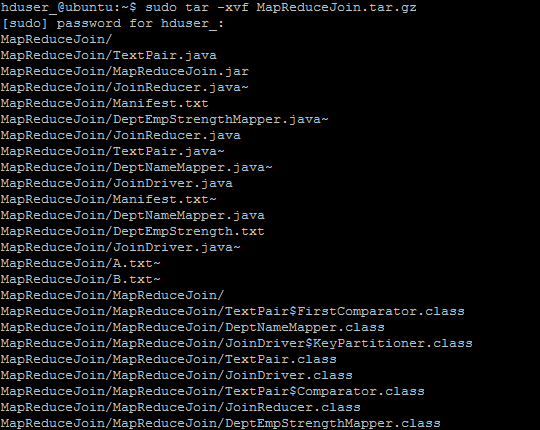
Step 3) НјШыФПТМ MapReduceJoin/
hduser_@ubuntu:~$ cd MapReduceJoin/
|
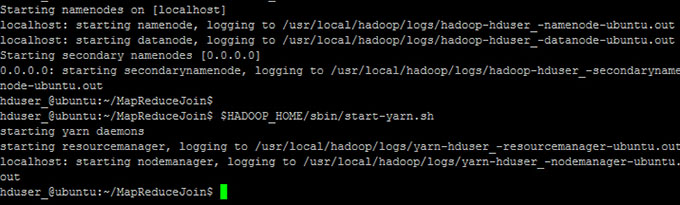
Step 4) ЦєЖЏ Hadoop
hduser_@ubuntu:~/MapReduceJoin$
$HADOOP_HOME/sbin/start-dfs.sh hduser_@ubuntu:~/MapReduceJoin
$ $HADOOP_HOME/sbin/start-yarn.sh
|
Step 5) DeptStrength.txt КЭ DeptName.txt гУгкДЫЯюФПЕФЪфШыЮФМў
етаЉЮФМўашвЊЪЙгУвдЯТУќСю - ИДжЦЕН HDFS ЕФИљФПТМЯТЃЌЪЙгУвдЯТУќСюЃК
hduser_@ubuntu:~/MapReduceJoin$
$HADOOP_HOME/bin/hdfs dfs
-copyFromLocal DeptStrength.txt
DeptName.txt /
|
Step 6) ЪЙгУвдЯТУќСю - дЫааГЬађ
hduser_@ubuntu:~/MapReduceJoin$
$HADOOP_HOME/bin/hadoop jar MapReduceJoin.jar /DeptStrength.txt
/DeptName.txt /output_mapreducejoin
|
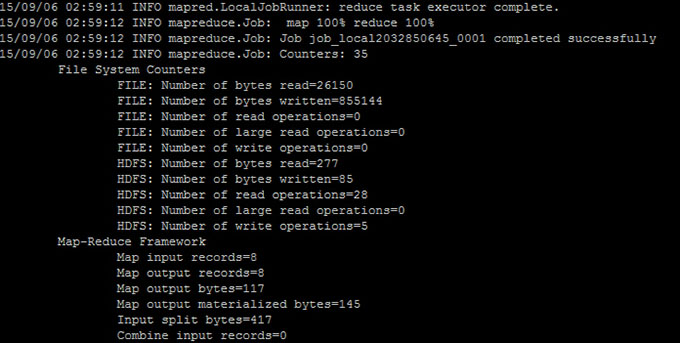
Step 7)
дкжДааУќСюКѓ, ЪфГіЮФМў (named 'part-00000') НЋЛсДцДЂдк HDFSФПТМ /output_mapreducejoin
НсЙћПЩвдЪЙгУУќСюааНчУцПЩвдПДЕНЃК
hduser_@ubuntu:~/MapReduceJoin$
;$HADOOP_HOME/bin/hdfs dfs -cat /output_mapreducejoin/part-00000
|

НсЙћвВПЩвдЭЈЙ§ Web НчУцВщПД(етРяЮвЕФащФтЛњЕФIPЪЧ 192.168.1.109)ЃЌШчЯТЭМЫљЪОЃК
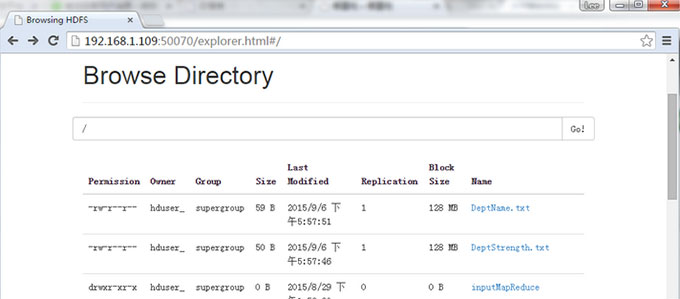
ЯждкЃЌбЁдё “Browse the filesystem”ЃЌВЂфЏРРЕН /output_mapreducejoin
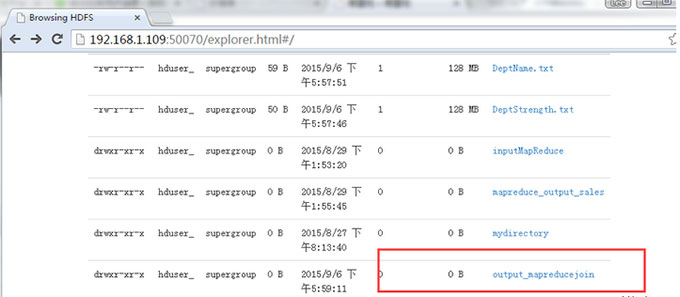
ДђПЊ part-r-00000
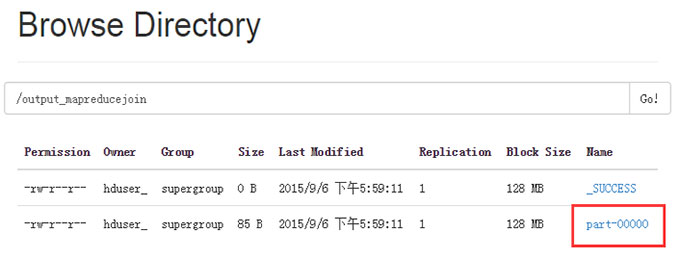
НсЙћШчЯТЫљЪОЃЌЕуЛї Download СДНгЯТдиЃК
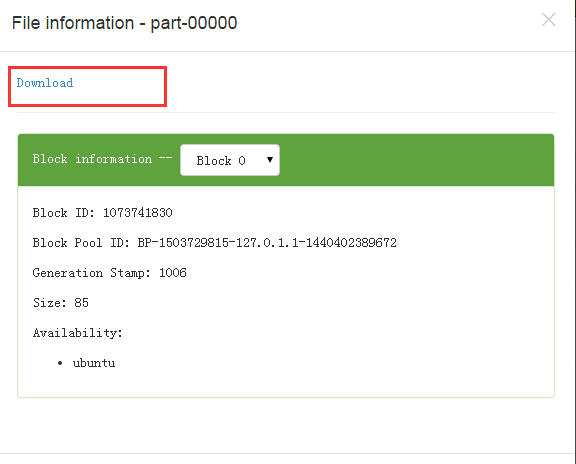
ДђПЊЯТдиКѓЕФ ЮФМўЃЌНсЙћШчЯТЫљЪОЃК
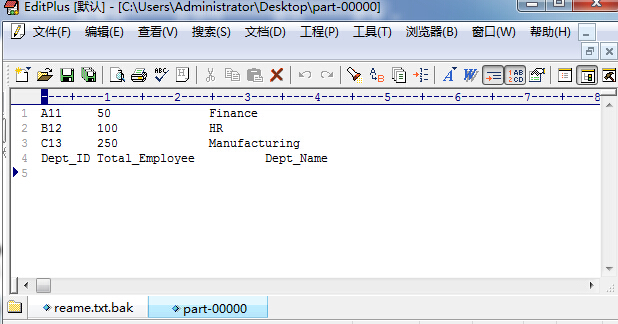
зЂЃКЧызЂвтЃЌЯТвЛДЮдЫааДЫГЬађжЎЧАЃЌашвЊЩОГ§ЪфГіФПТМ /output_mapreducejoin
$HADOOP_HOME/bin/hdfs dfs -rm -r /output_mapreducejoin
СэвЛжжЗНЗЈЪЧЪЙгУВЛЭЌЕФУћГЦзїЮЊЪфГіФПТМЁЃ
|









