|
MapReduce ЪЧЪЪКЯКЃСПЪ§ОнДІРэЕФБрГЬФЃаЭЁЃHadoopЪЧФмЙЛдЫаадкЪЙгУИїжжгябдБраДЕФMapReduceГЬађЃК Java, Ruby, Python, and C++. MapReduceГЬађЪЧЦНааадЕФЃЌвђДЫПЩЪЙгУЖрЬЈЛњЦїМЏШКжДааДѓЙцФЃЕФЪ§ОнЗжЮіЗЧГЃгагУЕФЁЃ
MapReduceГЬађЕФЙЄзїЗжСНИіНзЖЮНјааЃК
1.MapНзЖЮ
2.Reduce НзЖЮ
ЪфШыЕНУПвЛИіНзЖЮОљЪЧМќ - жЕЖдЁЃДЫЭтЃЌУПвЛИіГЬађдБашвЊжИЖЈСНИіКЏЪ§ЃКmapКЏЪ§КЭreduceКЏЪ§
ећИіЙ§ГЬвЊОРњШ§ИіНзЖЮжДааЃЌМД
MapReduceШчКЮЙЄзї
ШУЮвУЧгУвЛИіР§згРДРэНтетвЛЕу –
МйЩшгавдЯТЕФЪфШыЪ§ОнЕН MapReduce ГЬађЃЌЭГМЦвдЯТЪ§ОнжаЕФЕЅДЪЪ§СПЃК
Welcome to Hadoop Class
Hadoop is good
Hadoop is bad

MapReduce ШЮЮёЕФзюжеЪфГіЪЧЃК
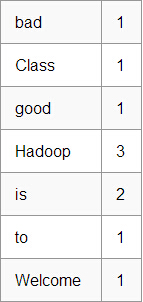
етаЉЪ§ОнОЙ§вдЯТМИИіНзЖЮ
ЪфШыВ№ЗжЃК
ЪфШыЕНMapReduceЙЄзїБЛЛЎЗжГЩЙЬЖЈДѓаЁЕФПщНазі input splits ЃЌЪфШыелЗжЪЧгЩЕЅИігГЩфЯћЗбЪфШыПщЁЃ
гГЩф - Mapping
етЪЧдк map-reduce ГЬађжДааЕФЕквЛИіНзЖЮЁЃдкетИіНзЖЮжаЕФУПИіЗжИюЕФЪ§ОнБЛДЋЕнИјгГЩфКЏЪ§РДВњЩњЪфГіжЕЁЃдкЮвУЧЕФР§згжаЃЌгГЩфНзЖЮЕФШЮЮёЪЧМЦЫуЪфШыЗжИюГіЯжУПИіЕЅДЪЕФЪ§СП(ИќЖрЯъЯИаХЯЂгаЙиЪфШыЗжИюдкЯТУцИјГі)ВЂБржЦвдФГвЛаЮЪНСаБэ<ЕЅДЪЃЌГіЯжЦЕТЪ>
жиХХ
етИіНзЖЮЯћКФгГЩфНзЖЮЕФЪфГіЁЃЫќЕФШЮЮёЪЧКЯВЂгГЩфНзЖЮЪфГіЕФЯрЙиМЧТМЁЃдкЮвУЧЕФР§згЃЌЭЌбљЕФДЪЛувдМАЫќУЧИїздГіЯжЦЕТЪЁЃ
Reducing
дкетвЛНзЖЮЃЌДгжиХХНзЖЮЪфГіжЕЛузмЁЃетИіНзЖЮНсКЯРДзджиХХНзЖЮжЕЃЌВЂЗЕЛивЛИіЪфГіжЕЁЃзмжЎЃЌетвЛНзЖЮЛузмСЫЭъећЕФЪ§ОнМЏЁЃ
дкЮвУЧЕФР§згжаЃЌетИіНзЖЮЛузмРДзджиХХНзЖЮЕФжЕЃЌМЦЫуУПИіЕЅДЪГіЯжДЮЪ§ЕФзмКЭЁЃ
ЯъЯИЕФећИіЙ§ГЬ
1.гГЩфЕФШЮЮёЪЧЮЊУПИіЗжИюДДНЈдкЗжИюУПЬѕМЧТМжДаагГЩфЕФКЏЪ§ЁЃ
2.гаЖрИіЗжИюЪЧКУДІЕФЃЌ вђЮЊДІРэвЛИіЗжИюЪЙгУЕФЪБМфЯрБШећИіЪфШыЕФДІРэЕФЪБМфвЊЩйЃЌ ЕБЗжИюБШНЯаЁЪБЃЌДІРэИКдиЦНКтЪЧБШНЯКУЕФЃЌвђЮЊЮвУЧе§дкВЂааЕиДІРэЗжИюЁЃ
ШЛЖјЃЌвВВЛЯЃЭћЗжИюЕФЙцФЃЬЋаЁЁЃЕБЗжИюЬЋаЁЃЌЙмРэЗжИюКЭгГЩфДДНЈШЮЮёЕФГЌИККЩПЊЪМж№ВНПижЦзмЕФзївЕжДааЪБМфЁЃ
3.ЖдгкДѓЖрЪ§зївЕЃЌзюКУЪЧЗжИюГЩДѓаЁЕШгквЛИіHDFSПщЕФДѓаЁ(етЪЧ64 MBЃЌФЌШЯЧщПіЯТ)ЁЃ
4.mapШЮЮёжДааНсЙћЕНЪфГіаДШыЕНБОЕиДХХЬЕФИїИіНкЕуЩЯЃЌЖјВЛЪЧHDFSЁЃ
5.жЎЫљвдбЁдёБОЕиДХХЬЖјВЛЪЧHDFSЪЧвђЮЊЃЌБмУтИДжЦЦфжаЗЂЩњ HDFS ДцДЂВйзїЁЃ
6.гГЩфЪфГіЪЧгЩМѕЩйШЮЮёДІРэвдВњЩњзюжеЕФЪфГіжаМфЪфГіЁЃ
7.вЛЕЉШЮЮёЭъГЩЃЌгГЩфЪфГіПЩвдШгЕєСЫЁЃЫљвдЃЌИДжЦВЂНЋЦфДцДЂдкHDFSБфЕУДѓВФаЁгУЁЃ
8.дкНкЕуЙЪеЯЕФгГЩфЪфГіжЎЧАЃЌгЩ reduce ШЮЮёЯћКФЃЌHadoop жиаТдЫааСэвЛИіНкЕудкгГЩфЩЯЕФШЮЮёЃЌВЂжиаТДДНЈЕФгГЩфЪфГіЁЃ
9.МѕЩйШЮЮёВЛЛсдкЪ§ОнОжВПадЕФИХФюЩЯЙЄзїЁЃУПИіmapШЮЮёЕФЪфГіБЛЙЉИјЕН reduce ШЮЮёЁЃгГЩфЪфГіБЛДЋЪфжСМЦЫуЛњЃЌЦфжа reduce ШЮЮёе§дкдЫааЁЃ
10.дкДЫЛњЦїЪфГіКЯВЂЃЌШЛКѓДЋЕнЕНгУЛЇЖЈвхЕФ reduce КЏЪ§ЁЃ
11.ВЛЯёЕНгГЩфЪфГіЃЌreduceЪфГіДцДЂдкHDFS(ЕквЛИіИББОБЛДцДЂдкБОЕиНкЕуЩЯЃЌЦфЫћИББОБЛДцДЂгкЦЋРыЛњМмЕФНкЕу)ЁЃвђДЫЃЌаДШы reduce ЪфГі
MapReduceШчКЮзщжЏЙЄзїЃП
Hadoop ЛЎЗжЙЄзїЮЊШЮЮёЁЃгаСНжжРраЭЕФШЮЮёЃК
1.Map ШЮЮё (ЗжИюМАгГЩф)
2.Reduce ШЮЮё (жиХХЃЌЛЙд)
ШчЩЯЫљЪі
ЭъећЕФжДааСїГЬ(жДаа Map КЭ Reduce ШЮЮё)ЪЧгЩСНжжРраЭЕФЪЕЬхЕФПижЦЃЌГЦЮЊ
Jobtracker : ОЭЯёвЛИіжї(ИКд№ЬсНЛЕФзївЕЭъШЋжДаа)
ЖрШЮЮёИњзйЦї : ГфЕБНЧЩЋОЭЯёДгЛњЃЌЫќУЧУПИіжДааЙЄзї
ЖдгкУПвЛЯюЙЄзїЬсНЛжДаадкЯЕЭГжаЃЌгавЛИі JobTracker зЄСєдк Namenode КЭ Datanode зЄСєЖрИі TaskTrackerЁЃ
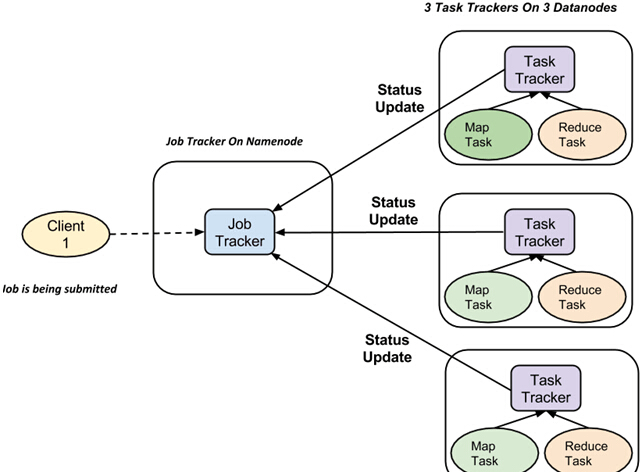
зївЕБЛЗжГЩЖрИіШЮЮёЃЌШЛКѓдЫааЕНМЏШКжаЕФЖрИіЪ§ОнНкЕуЁЃ
JobTrackerЕФд№ШЮЪЧаЕїЛюЖЏЕїЖШШЮЮёРДдкВЛЭЌЕФЪ§ОнНкЕуЩЯдЫааЁЃ
ЕЅИіШЮЮёЕФжДааЃЌШЛКѓгЩ TaskTracker ДІРэЃЌЫќЮЛгкжДааЙЄзїЕФвЛВПЗжЃЌдкУПИіЪ§ОнНкЕуЩЯЁЃ
TaskTracker ЕФд№ШЮЪЧЗЂЫЭНјЖШБЈИцЕНJobTrackerЁЃ
ДЫЭтЃЌTaskTracker жмЦкадЕиЗЂЫЭ“аФЬј”аХКХаХЯЂИј JobTracker вдБуЭЈжЊЯЕЭГЫќЕФЕБЧАзДЬЌЁЃ
етбљ JobTracker ОЭПЩвдИњзйУПЯюЙЄзїЕФзмЬхНјЖШЁЃдкШЮЮёЪЇАмЕФЧщПіЯТЃЌJobTracker ПЩвддкВЛЭЌЕФ TaskTracker жиаТЕїЖШЫќЁЃ
|









