学习机器学习就像学习一门新语言,需要先掌握基本词汇。这些术语构成了机器学习的"语言系统",理解它们是深入学习的第一步。
想象一下你在教一个机器人认识水果:
数据(Data)
什么是数据?
数据 是机器学习的"原材料",就像厨师做菜需要的食材一样。没有数据,机器学习就无法进行。
数据的类型
1. 结构化数据
特点 :有明确的格式和组织方式,像表格一样整齐
# 结构化数据示例:学生信息表
实例
输出 :
姓名 年龄 成绩 班级 0 张三 18 85 一班 1 李四 19 92 二班 2 王五 20 78 一班
2. 非结构化数据
特点 :没有固定格式,需要特殊处理
例子 :
# 非结构化数据示例:文本和图像 text_data = "这个产品质量很好,我很满意!" # image_data = 一张产品的照片 # audio_data = 顾客的语音评价
数据质量的重要性
垃圾进,垃圾出 (Garbage In, Garbage Out)是机器学习的重要原则。数据质量直接决定模型效果。
特征(Feature)
什么是特征?
特征 是数据的"可观察属性",就像描述一个人的特征:身高、体重、发色、性格等。在机器学习中,特征是用来做预测的依据。
特征选择的重要性 :
特征的类型
1. 数值特征
特点 :可以用数字表示,可以进行数学运算
# 数值特征示例 numerical_features = { '年龄': [25, 30, 35, 40], '收入': [5000, 8000, 12000, 15000], '身高': [165, 170, 175, 180] }
2. 类别特征
特点 :表示不同的类别,不能进行数学运算
# 类别特征示例 categorical_features = { '性别': ['男', '女', '男', '女'], '学历': ['本科', '硕士', '博士', '本科'], '城市': ['北京', '上海', '广州', '深圳'] }
3. 文本特征
特点 :需要特殊处理才能被模型使用
# 文本特征示例 text_features = { '评论': [ '这个产品很好用,推荐购买!', '质量一般,不太满意。', '性价比高,值得入手。' ] }
特征工程示例
标签(Label)
什么是标签?
标签 是我们想要预测的"答案",就像考试题的正确答案一样。在监督学习中,每个数据样本都有一个对应的标签。
标签的作用 :
标签的类型
1. 分类标签
特点 :离散的类别值
# 分类标签示例 classification_labels = { '邮件类型': ['垃圾邮件', '正常邮件', '垃圾邮件', '正常邮件'], '情感倾向': ['正面', '负面', '中性', '正面'], '疾病诊断': ['患病', '健康', '健康', '患病'] }
2. 回归标签
特点 :连续的数值
# 回归标签示例 regression_labels = { '房价': [250000, 320000, 180000, 450000], '温度': [25.5, 28.3, 22.1, 30.0], '股票价格': [100.5, 105.2, 98.7, 110.3] }
标签质量的重要性
# 标签质量问题示例 import numpy as np # 模拟图像分类任务中的标签问题 image_data = ['cat1.jpg', 'dog1.jpg', 'cat2.jpg', 'dog2.jpg'] problematic_labels = ['猫', '犬', '猫咪', '狗'] # 标签不一致 # 标签标准化 label_mapping = { '猫': 'cat', '猫咪': 'cat', '犬': 'dog', '狗': 'dog' } standardized_labels = [label_mapping[label] for label in problematic_labels] print("原始标签:", problematic_labels) print("标准化标签:", standardized_labels)
模型(Model)
什么是模型?
模型 是机器学习算法从数据中学到的"规律"或"模式",就像学生从课本中学到的知识一样。
模型的本质 :
模型的表示
模型的复杂度
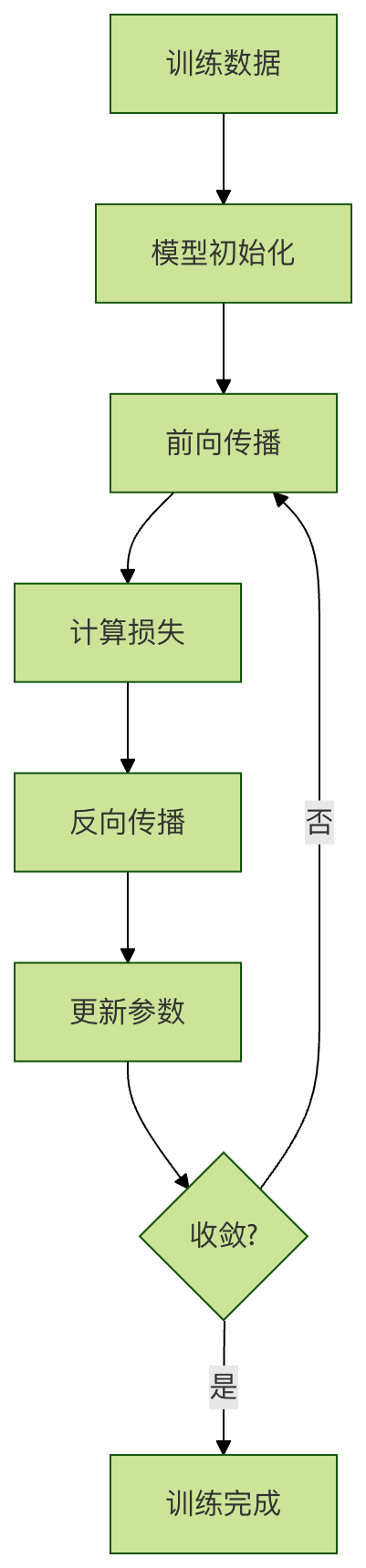
训练(Training)
什么是训练?
训练 是模型学习的过程,就像学生上课学习知识一样。在训练过程中,模型不断调整参数,使预测结果越来越接近真实标签。
训练过程示例
推理(Inference)
什么是推理?
推理 是使用训练好的模型进行预测的过程,就像学生用学到的知识解答考试题一样。
推理过程示例
完整示例:从数据到推理
常见机器学习网络类型