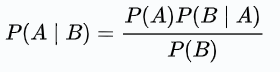想象一下,你正在网上书店浏览,系统根据你之前购买过《三体》和《流浪地球》,向你推荐了《球状闪电》。这个 猜你喜欢 的功能背后,很可能就用到了我们今天要讲的 朴素贝叶斯(Naive Bayes) 算法。
朴素贝叶斯是一种基于 贝叶斯定理 的简单而高效的 概率分类算法 。
朴素贝叶斯的核心思想是:通过已知的某些特征(比如你买过的书),来计算某个事件(比如你会喜欢另一本书)发生的概率,并选择概率最高的类别作为预测结果。
它的 朴素(Naive) 之处在于一个关键假设: 所有特征之间是相互独立的 。也就是说,在判断你是否喜欢《球状闪电》时,算法认为购买过《三体》和购买过《流浪地球》这两个特征对你的决策影响是互不相关的。虽然在现实中,特征之间常有联系,但这个简化的假设让计算变得非常高效,且在许多实际场景中(尤其是文本分类)效果出奇地好。
核心原理:贝叶斯定理
要理解朴素贝叶斯,必须先了解它的基石—— 贝叶斯定理 。它描述了在已知一些条件的情况下,如何更新某个事件发生的概率。
1. 贝叶斯公式
公式看起来可能有点抽象,但我们用一个例子来理解它:
P(A|B) = [P(B|A) * P(A)] / P(B)
场景 :判断一封邮件是否是垃圾邮件(Spam)。
贝叶斯定理的精髓 :它利用了我们已经知道的信息(垃圾邮件的普遍规律 P(A) 和垃圾邮件用词习惯 P(B|A) ),结合新观察到的证据(这封邮件里有"免费"),来修正我们对这个具体事件的判断(这封邮件是垃圾邮件的可能性 P(A|B) )。
2. "朴素"在哪里?
真正的贝叶斯分类器在计算 P(B|A) 时,需要考虑所有特征(B1, B2, B3...)的联合概率 P(B1, B2, B3... | A) ,这非常复杂。
朴素贝叶斯做出了一个强大的简化假设: 所有特征都相互条件独立 。这意味着:
P(B1, B2, B3... | A) ≈ P(B1|A) * P(B2|A) * P(B3|A) * ...
这个假设将复杂的联合概率计算,简化成了多个简单概率的乘法,极大地降低了计算成本。
三、 工作流程与分类器类型
朴素贝叶斯分类器的工作流程可以概括为以下几步:
根据特征数据的不同类型,朴素贝叶斯主要有以下几种变体:
四、 动手实践:用 Python 实现垃圾邮件分类
让我们用一个简化的例子,亲手实现一个基于多项式朴素贝叶斯的垃圾邮件分类器。
1. 场景与数据准备
我们有一些已经标记好的邮件文本( spam 或 ham 正常邮件)。
实例
2. 代码实现步骤
3. 代码解析
数据分离 :将训练数据中的文本和标签分别存入两个列表,这是 sklearn 库要求的格式。
构建模型管道 :
模型训练 : model.fit(texts, labels) 是核心训练过程。算法在这里计算了:
预测与输出 :对于新邮件,模型先将其转换为特征向量,然后根据贝叶斯公式计算它属于每个类别的概率,最后输出概率更高的类别。
输出:
属于'ham'的概率: 0.5000 属于'spam'的概率: 0.5000 ---------------------------------------- 邮件内容: "明天上午十点电话会议讨论预算" 预测类别: ham 属于'ham'的概率: 0.5000 属于'spam'的概率: 0.5000
五、 优缺点与注意事项
优点
缺点与注意事项
六、 练习与挑战
为了巩固你对朴素贝叶斯的理解,请尝试以下练习:
朴素贝叶斯作为入门机器学习的一个绝佳起点,它用简洁的数学公式展现了概率论的魅力,并以其实用性在文本分类、推荐系统、情感分析等领域牢牢占据一席之地。理解它,你就掌握了打开许多智能应用黑箱的第一把钥匙。