想象一下,你是一位厨师,要做一道美味的菜肴,机器学习模型就像你的"烹饪算法",而原始数据就是你从市场买回来的各种食材:有蔬菜、肉类、调料,但可能有些是带泥的,有些是整块的,有些味道很冲。 特征工程 ,就是将这些原始"食材"进行清洗、切割、腌制、搭配,最终处理成可以直接下锅烹饪的"半成品"的过程,它是连接原始数据与机器学习模型的桥梁,是决定模型性能上限的关键步骤。
简单来说, 特征工程 是利用领域知识,通过一系列技术手段,从原始数据中提取、构造、选择出对机器学习模型更有价值、更易学习的特征(变量)的过程。
一、为什么特征工程如此重要?
在机器学习项目中,数据和特征的质量直接决定了模型性能的上限,而模型和算法只是逼近这个上限。一个优秀的特征工程可以:
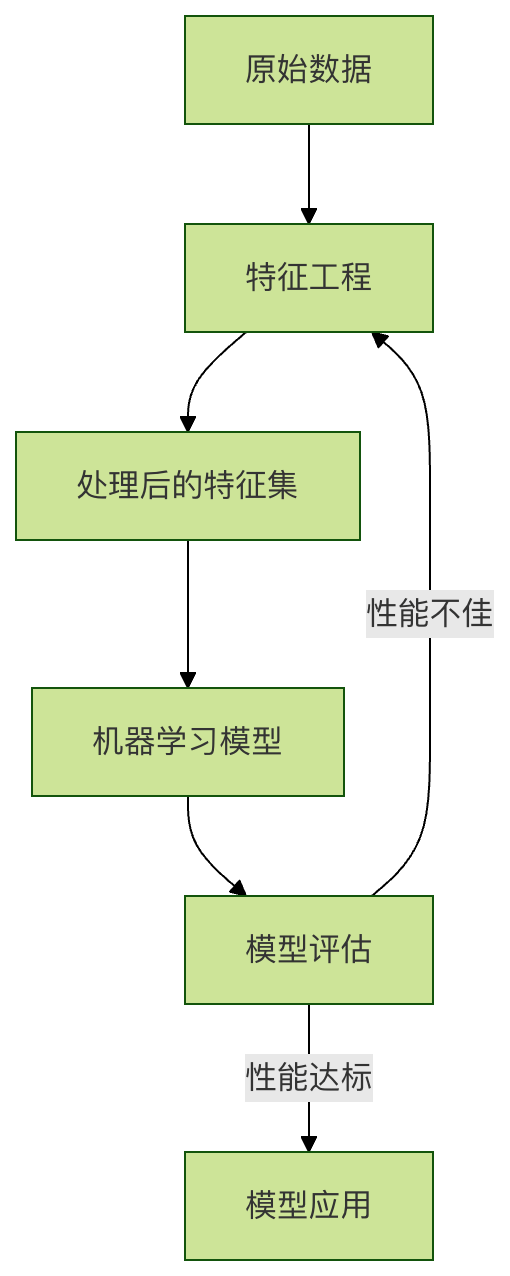
我们可以用以下流程图来直观理解特征工程在整个机器学习流程中的位置:
二、特征工程的核心操作
特征工程主要包含三大类操作: 特征处理 、 特征构造 和 特征选择 。
1. 特征处理
这是最基础的一步,目的是将原始数据"清洗"成干净、规整的格式。
a) 处理缺失值
数据中经常存在缺失值(如 NaN , NULL ),需要合理处理。
代码示例(使用 Python 的 pandas 库):
实例
b) 处理异常值
异常值是与大部分数据明显不同的值,可能会干扰模型。常用检测方法有:
处理方式可以是删除、替换为边界值或视为缺失值处理。
c) 数据标准化/归一化
许多模型(如 SVM、KNN、神经网络)对特征的尺度敏感。我们需要将不同尺度的特征转换到同一尺度。
代码示例(使用 scikit-learn 库):
2. 特征构造
通过组合或转换现有特征,创造出新的、更具预测力的特征。
a) 对数值特征进行变换
b) 对类别特征进行编码
机器学习模型无法直接处理"北京"、"上海"这样的文本。需要将其转换为数字。
代码示例:
3. 特征选择
从所有特征中挑选出最重要的一个子集,以降低维度、减少过拟合风险。
代码示例(基于特征重要性进行选择):
三、实践练习:动手处理一个简单数据集
任务 :对著名的泰坦尼克号乘客数据集进行基础的特征工程,为预测乘客是否生还做准备。
步骤提示 :
通过这个练习,你将亲身体会到,原始数据如何通过一步步的特征工程,变得对机器学习模型更加"友好"。
总结
特征工程是机器学习中一门结合了 艺术 (领域知识、经验、直觉)与 科学 (统计方法、算法)的技艺。它没有一成不变的规则,需要根据具体数据、问题和模型反复尝试和迭代。对于初学者,掌握本文介绍的基础方法并勤加练习,你就已经为构建有效的机器学习模型打下了最坚实的一块基石。记住, 优秀的模型往往源于优秀的特征 。