在开始构建一个复杂的机器学习模型之前,我们首先要做的不是选择算法,而是 理解数据 。
如果把机器学习比作烹饪,那么数据就是食材。
一个优秀的厨师必须了解食材的特性——是新鲜还是变质,是偏甜还是偏酸,是适合炖煮还是快炒。
数据可视化,就是我们观察和品尝数据这道食材的 放大镜 和 味蕾 。
数据可视化通过图表、图形等视觉元素,将枯燥的数字转化为直观的图像,帮助我们:
本文将使用 Python 中最流行的数据科学库 pandas 和可视化库 matplotlib 、 seaborn ,带你掌握数据可视化的核心技能。
准备工作:环境与数据
在开始画图之前,我们需要准备好"画布"和"颜料"。
安装必要的库
如果你使用的是 Anaconda,这些库通常已预装。否则,可以通过以下命令安装:
导入库与加载数据
我们将使用一个经典的公开数据集:泰坦尼克号乘客数据集。它包含了乘客的生存情况、舱位、年龄、性别等信息。
实例
运行上面的代码,你会看到数据有 891 行(乘客)和 15 列(特征)。 df.head() 可以让你对数据长什么样有一个初步的印象。
单变量分析:了解单个特征的分布
单变量分析关注 一个 特征(变量)的分布情况。这是最基础的分析。
1. 数值型特征:直方图与箱线图
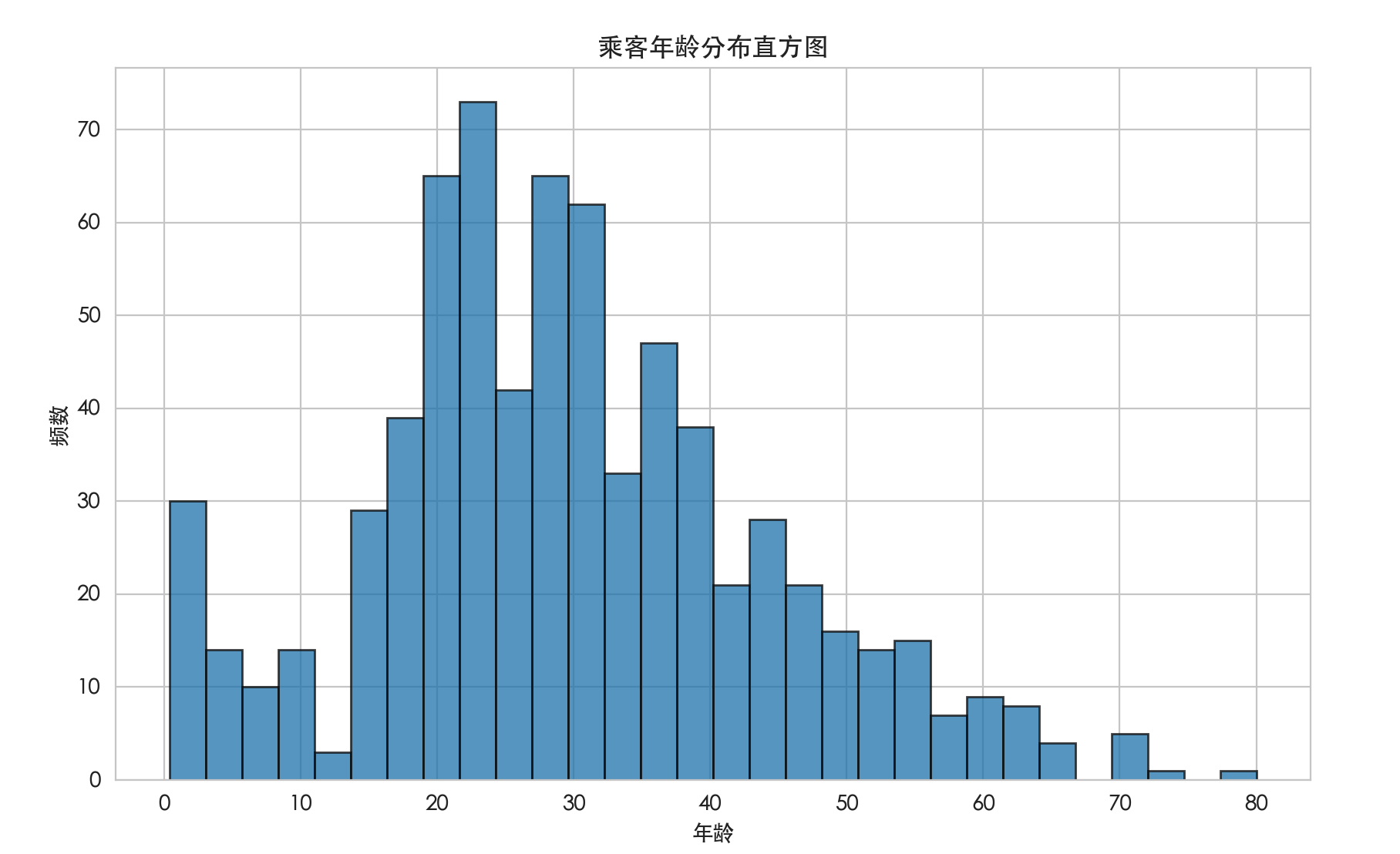
对于像 age (年龄)、 fare (票价)这样的连续数值型特征,我们常用 直方图 和 箱线图 。
直方图 展示了数据在不同区间("桶")内的频率分布。
解读 :这张图可以告诉我们乘客的年龄主要集中在哪个区间(例如 20-30 岁),分布是否对称,是否有异常值等。
箱线图 可以清晰地显示数据的 中位数、四分位数和异常值 。
解读 :箱体中间的线是中位数。箱体上下边界是上四分位数(Q3)和下四分位数(Q1)。上下"胡须"通常延伸到 1.5 倍四分位距以内的最远数据点,之外的点被视为 异常值 (图中上方的圆圈)。这张图立刻告诉我们,票价存在很多极高的异常值。
2. 类别型特征:柱状图
对于像 sex (性别)、 embarked (登船港口)、 survived (是否幸存)这样的类别型特征,我们使用 柱状图 来统计每个类别的数量。
双变量分析:探索特征间的关系
双变量分析探索 两个 特征之间的关系。
1. 数值 vs 数值:散点图
散点图是研究两个连续变量相关性的利器。
2. 类别 vs 数值:分组箱线图或小提琴图
我们常常想知道不同类别下,某个数值特征的分布有何不同。例如:"不同舱位的乘客,票价分布有何差异?"
小提琴图 是箱线图的高级版本,它不仅显示了统计量,还通过核密度估计展示了数据的实际分布形状。
3. 类别 vs 类别:堆叠柱状图或热力图
对于两个类别型变量,我们可以用 堆叠柱状图 来观察组合情况。例如:"不同性别的幸存比例如何?"
解读 :从图表和交叉表可以明显看出,女性的幸存比例远高于男性。这是一个非常强的信号,说明 sex 特征对于预测生存至关重要。
多变量分析与高级可视化
有时我们需要同时考虑三个甚至更多变量。 seaborn 库让这变得简单。
1. 带分组的散点图
我们可以在散点图的基础上,用颜色或形状区分第三个(类别型)变量。
2. 相关矩阵热力图
当我们有多个数值特征时,可以一次性计算它们两两之间的相关系数,并用热力图展示。
解读 :颜色越暖(红),表示正相关性越强;越冷(蓝),表示负相关性越强。 annot=True 将具体数值显示在方格内。例如, pclass (舱位)和 fare (票价)呈强负相关(-0.55),即舱位号越小(等级越高),票价越高,这与我们之前的分析一致。
实践练习:动手探索
现在,请你尝试完成以下练习,巩固所学知识:
总结
数据可视化是机器学习工作流中 不可或缺的探索性步骤 。通过本文,你学会了:
核心工具 :使用 matplotlib 进行基础绘图,使用 seaborn 绘制更美观、信息量更丰富的统计图形。
分析思路 :
核心目标 :所有图表都是为了 提出假设 和 发现洞察 ,例如性别可能是一个重要的预测特征、票价数据中有大量异常值需要处理。
记住,在把数据喂给模型之前,请务必花时间好好看看它。一个清晰的可视化发现,往往能比复杂的算法更早地指引你走向正确的方向。