本章节我们将一起探索两个至关重要的核心概念: 损失函数 和 梯度 ,它们是机器学习算法能够 学习 和 改进 的基石。
想象一下,你在学习投篮,每次投球后,你都会观察球是进了、偏左了还是偏右了。这个观察结果与完美进球之间的差距,就是你的 损失 。而为了下次投得更准,你会根据这次偏差的方向和大小来调整你的姿势和力度,这个 调整的方向和大小 就类似于 梯度 。
在机器学习中,模型就是那个 学习者 ,损失函数衡量它的 错误程度 ,而梯度则告诉它 如何改进 。理解它们,你就掌握了机器学习如何工作的核心逻辑。
一、 损失函数:模型的成绩单
1.1 什么是损失函数?
损失函数 ,有时也叫 代价函数 或 目标函数 ,是一个用来 量化模型预测值与真实值之间差异 的函数。
1.2 常见损失函数举例
不同的任务需要使用不同的 评分标准 ,以下是两个最基础的损失函数:
均方误差 - 适用于回归问题(预测连续值,如房价、温度)
均方误差计算的是所有样本的 预测值与真实值之差的平方的平均值 。
公式 : MSE = (1/n) * Σ(真实值ᵢ - 预测值ᵢ)²
特点 :由于使用了平方,它对较大的误差惩罚更重(误差为 2 时,平方后贡献为 4;误差为 10 时,平方后贡献高达 100)。
代码示例 :
实例
交叉熵损失 - 适用于分类问题(预测类别,如图片是猫还是狗)
交叉熵衡量的是 模型预测的概率分布 与 真实的概率分布 之间的差异。在二分类中,真实分布通常是 [1, 0] (是类别 A)或 [0, 1] (是类别 B)。
二分类公式(对数损失) : Log Loss = - (1/n) * Σ [真实值ᵢ * log(预测概率ᵢ) + (1 - 真实值ᵢ) * log(1 - 预测概率ᵢ)]
直观理解 :当真实标签为 1 时,我们希望模型预测的概率也接近 1。如果此时模型预测了一个很低的概率(比如 0.1),那么 log(0.1) 会是一个很大的负数,再乘以前面的负号,就会导致损失值变得很大,表示惩罚很重。
二、 梯度:指引优化方向的"指南针"
现在我们知道了如何给模型打分(损失函数),接下来最关键的问题是: 模型如何根据这个分数来改进自己? 答案就是通过 梯度 。
2.1 什么是梯度?
在机器学习中,模型通常由许多 参数 (或叫 权重 )构成。我们可以把 损失函数 L 看作是所有这些参数的函数: L(w1, w2, ..., wn) 。
2.2 为什么梯度能指引优化?
我们的目标是 最小化损失函数 。既然梯度指向了损失上升最快的方向,那么它的反方向 -∇L 自然就是损失 下降最快 的方向。
优化过程(梯度下降)可以形象地理解为 :
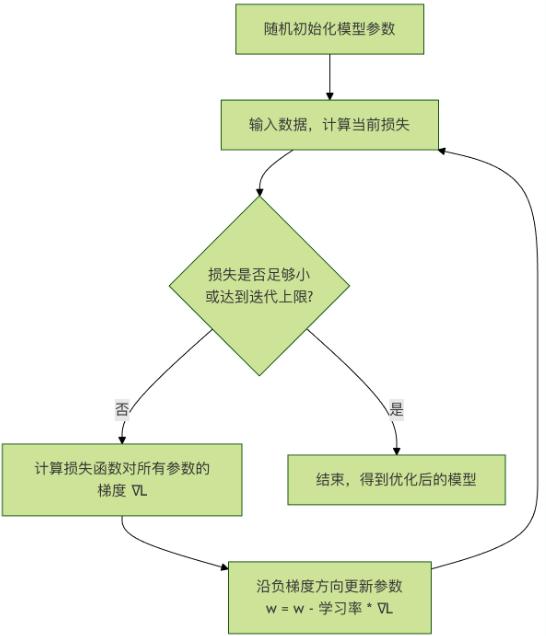
你站在一座山谷(损失曲面)的某个山坡上,蒙着眼睛想要走到谷底(损失最小点)。你每走一步前,都用脚感受一下四周哪个方向最陡峭(计算梯度),然后朝着最陡峭的 下坡方向 (负梯度方向)迈出一步(更新参数)。重复这个过程,你最终就能到达谷底。
这个过程可以用下面的流程图概括:
2.3 梯度下降的简单示例
让我们用一个最简单的例子——只有一个参数 w 的线性模型,来演示梯度下降。
假设我们的损失函数是 L(w) = w² 。显然,当 w = 0 时,损失最小。
运行这段代码,你会看到 :
三、 核心要点与联系总结
它们之间的关系链是 : 模型做出预测 → 损失函数计算误差 → 计算误差相对于各参数的梯度 → 沿负梯度方向更新参数 → 模型改进 → 重复...