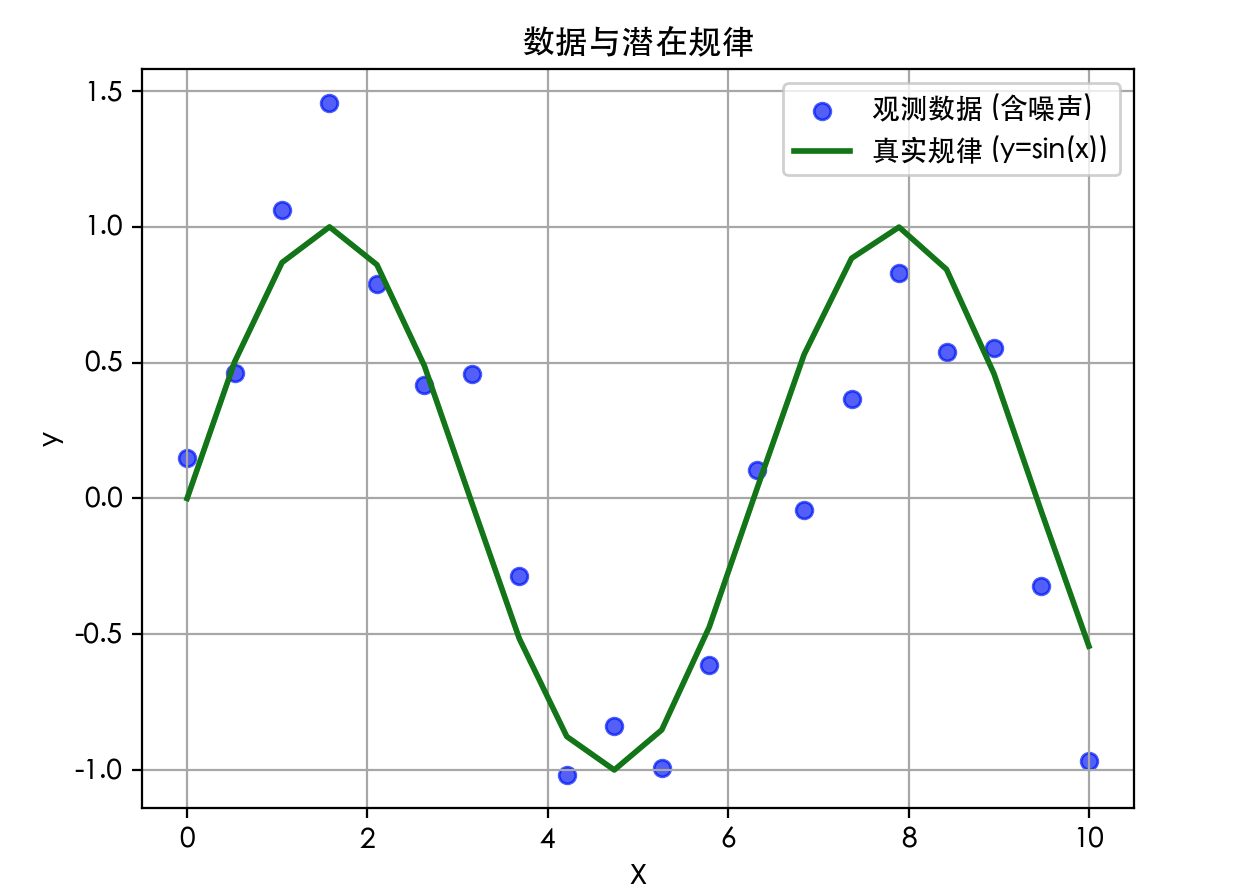
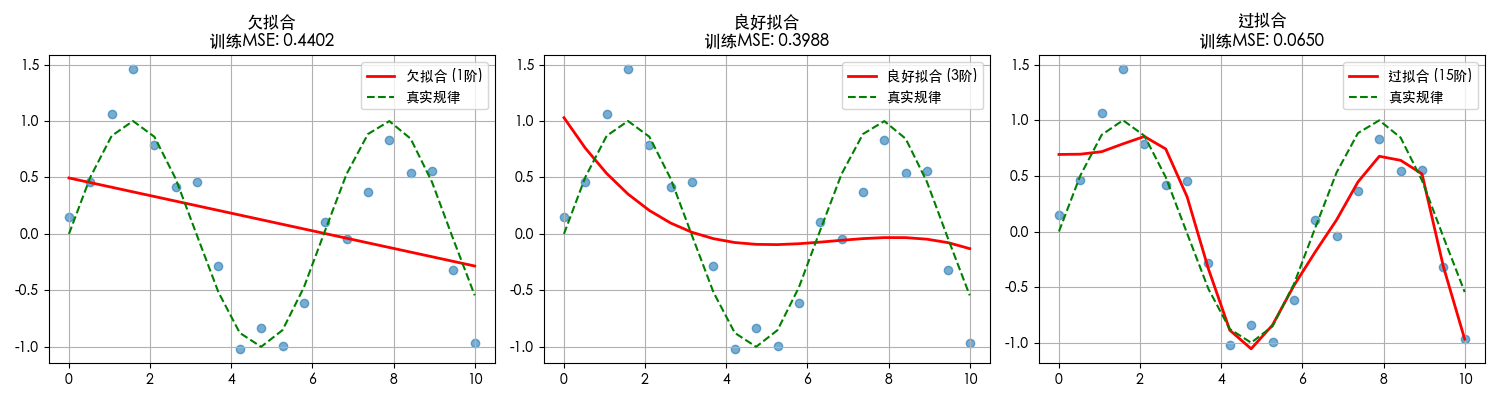
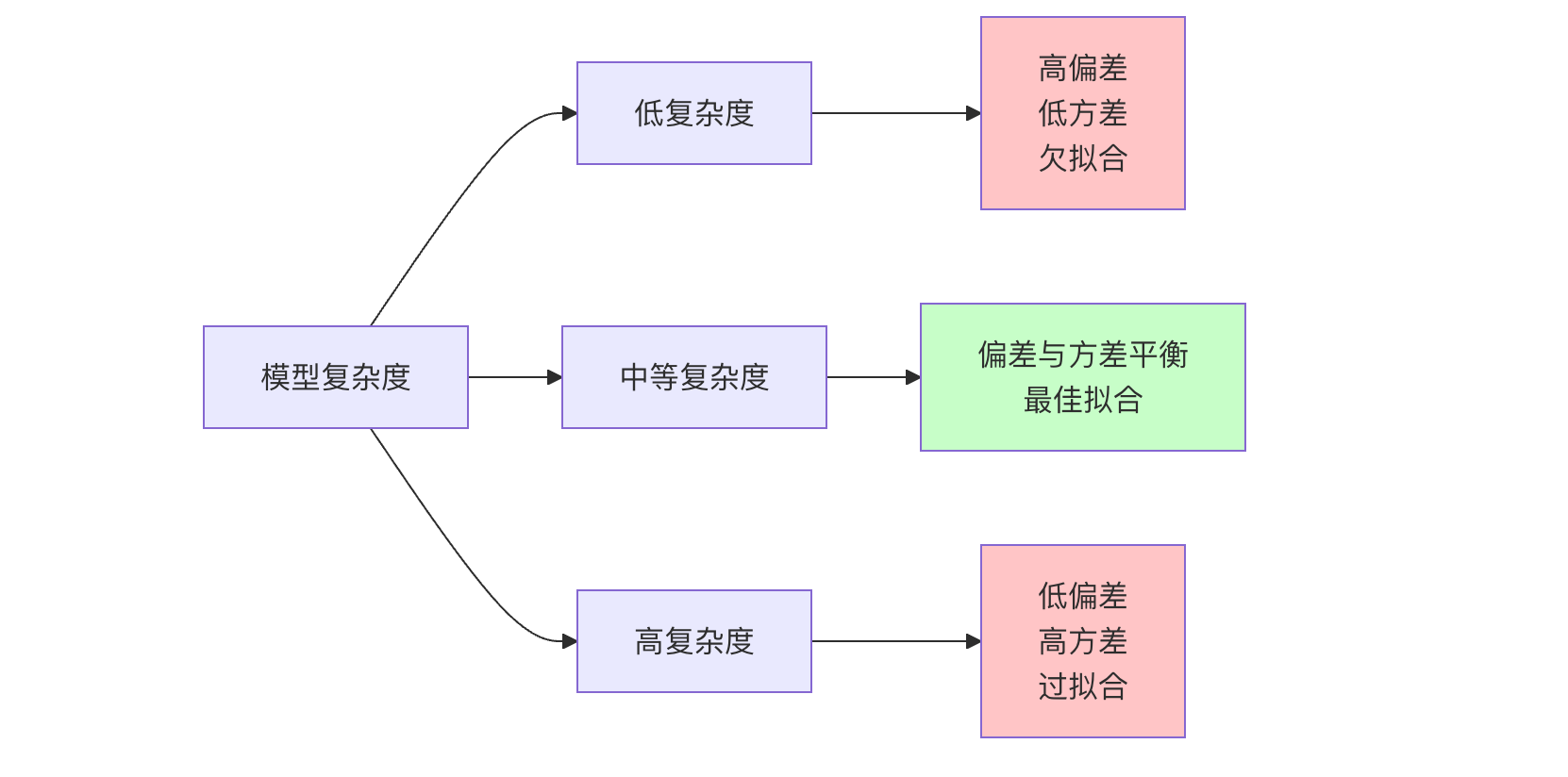
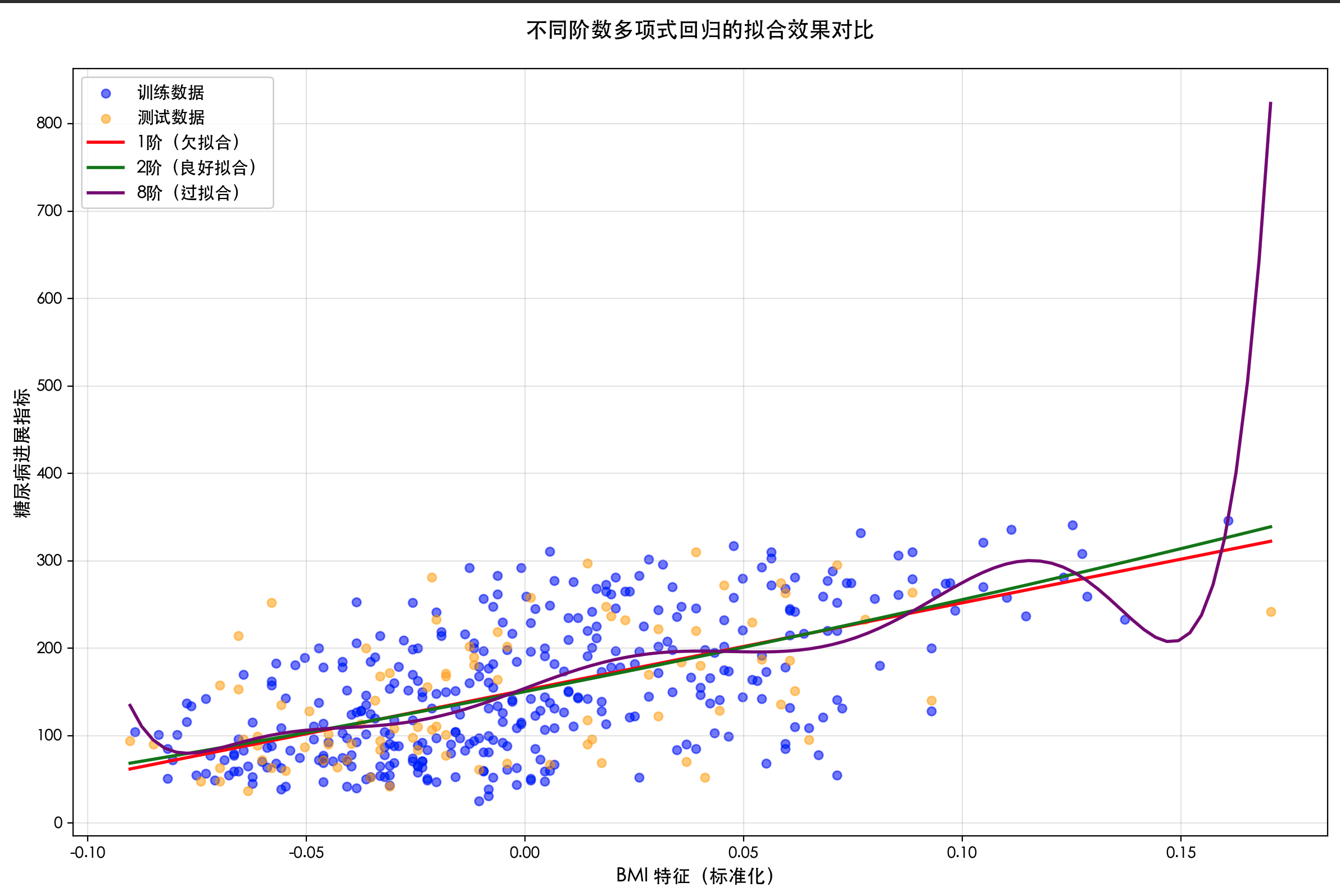
import numpy as np import matplotlib.pyplotas plt from sklearn.linear_modelimport LinearRegression from sklearn.preprocessingimport PolynomialFeatures from sklearn.metricsimport mean_squared_error
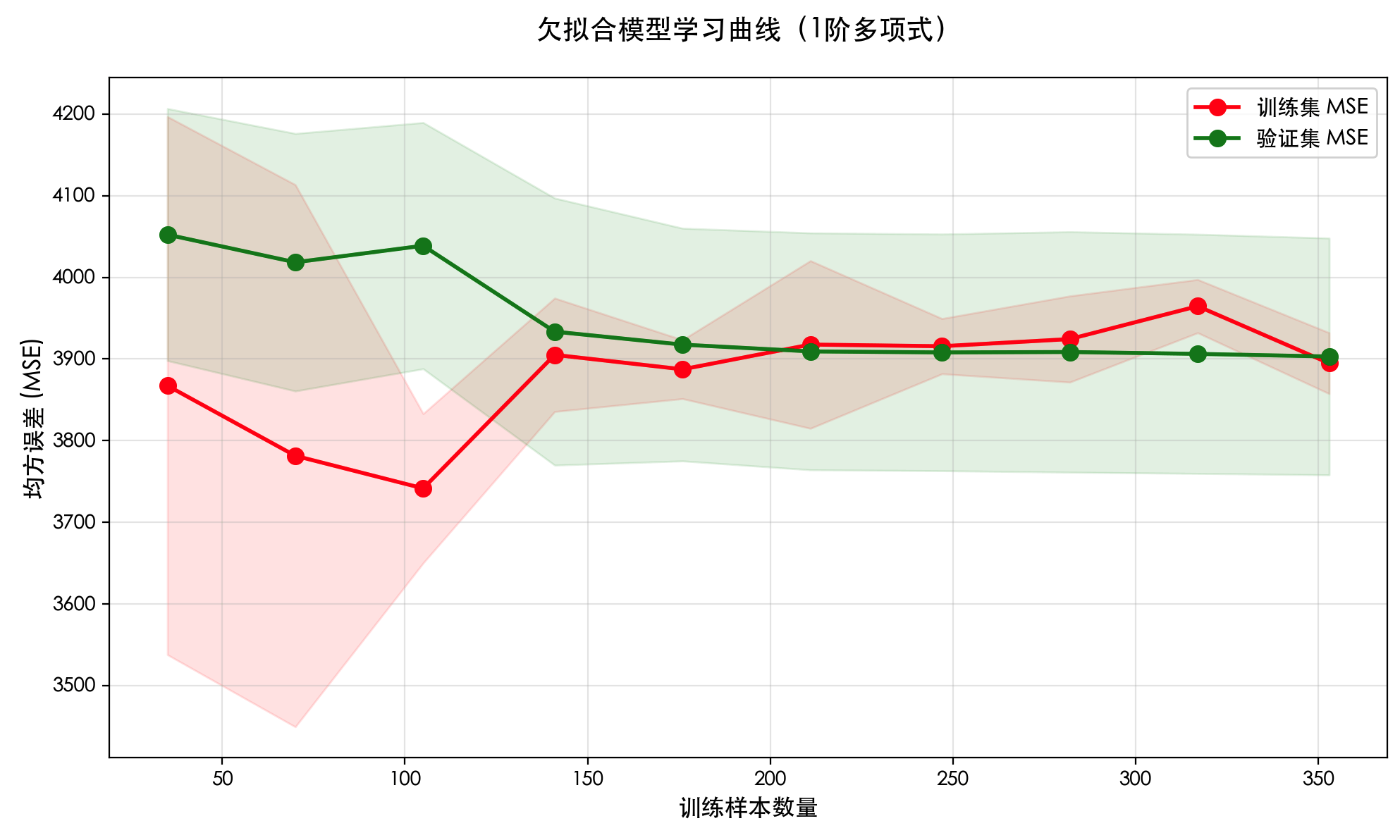
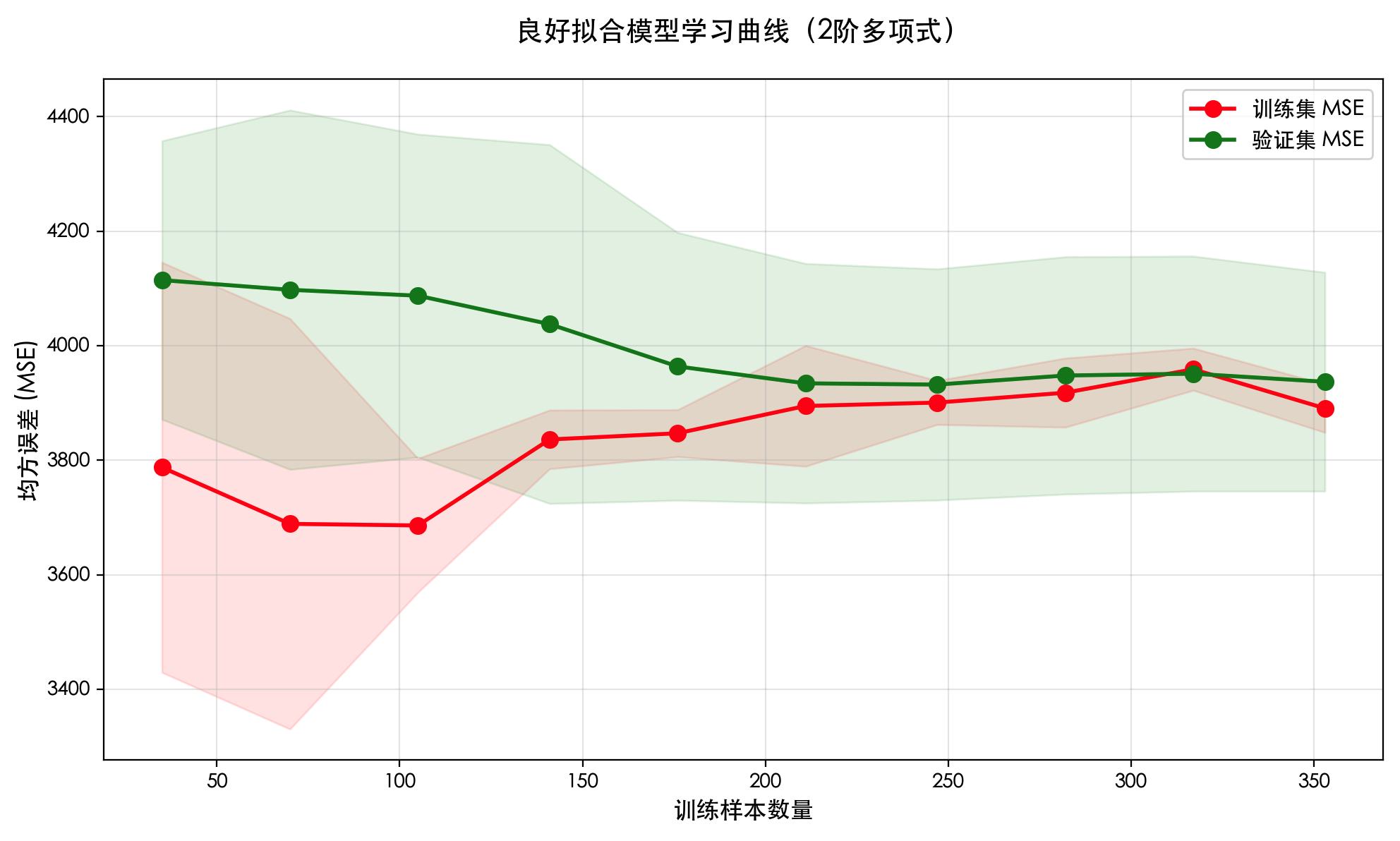
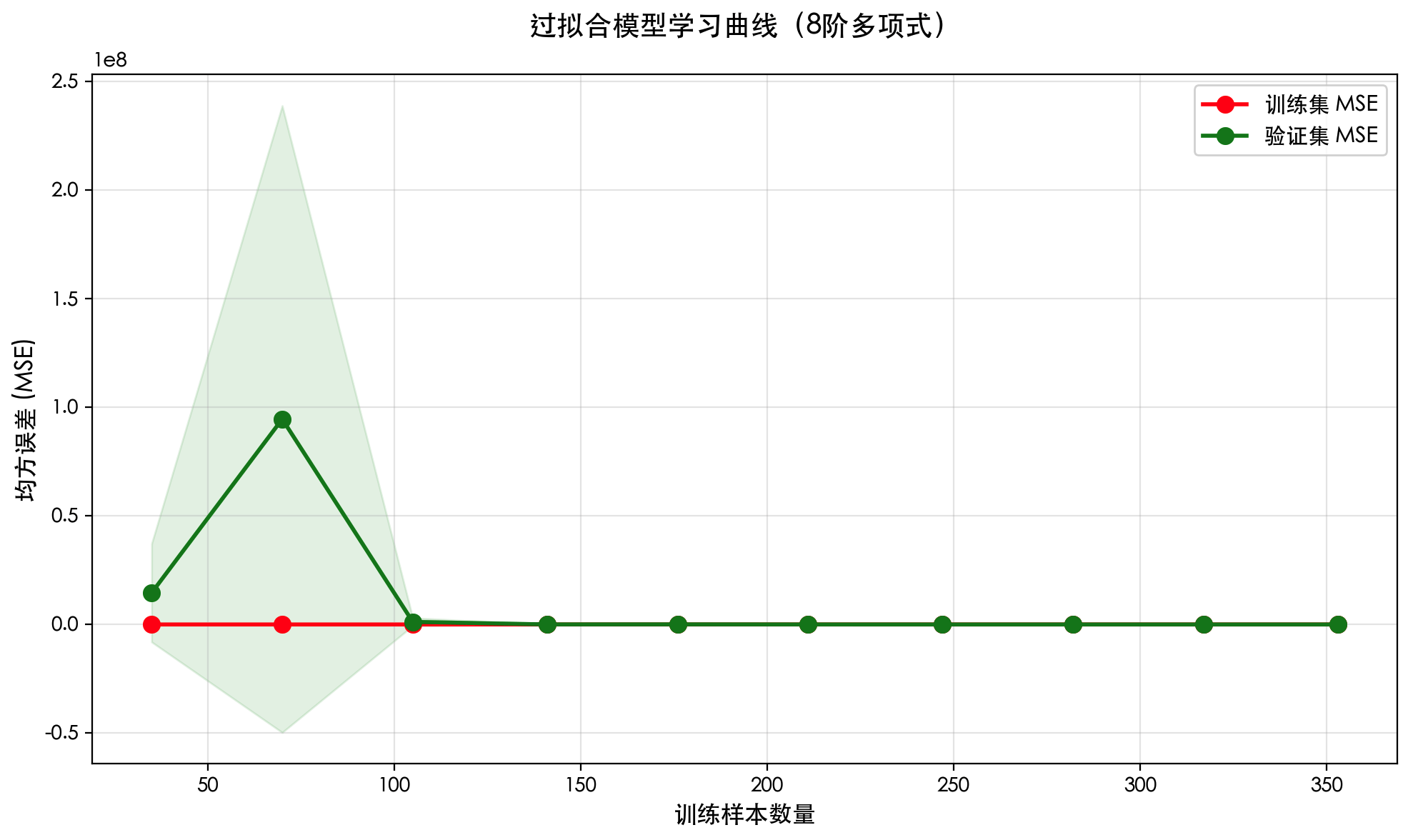
import numpy as np import matplotlib.pyplotas plt from sklearn.datasetsimport load_diabetes from sklearn.model_selectionimport train_test_split from sklearn.model_selectionimport learning_curve from sklearn.pipelineimport make_pipeline from sklearn.linear_modelimport LinearRegression from sklearn.preprocessingimport PolynomialFeatures, StandardScaler from sklearn.metricsimport mean_squared_error importwarnings warnings.filterwarnings('ignore')
for i, order inenumerate(orders):
model = make_pipeline(StandardScaler(), PolynomialFeatures(order), LinearRegression())
model.fit(X_train, y_train)
y_plot = model.predict(X_plot)
plt.plot(X_plot, y_plot, color=colors[i], linewidth=2, label=labels[i])
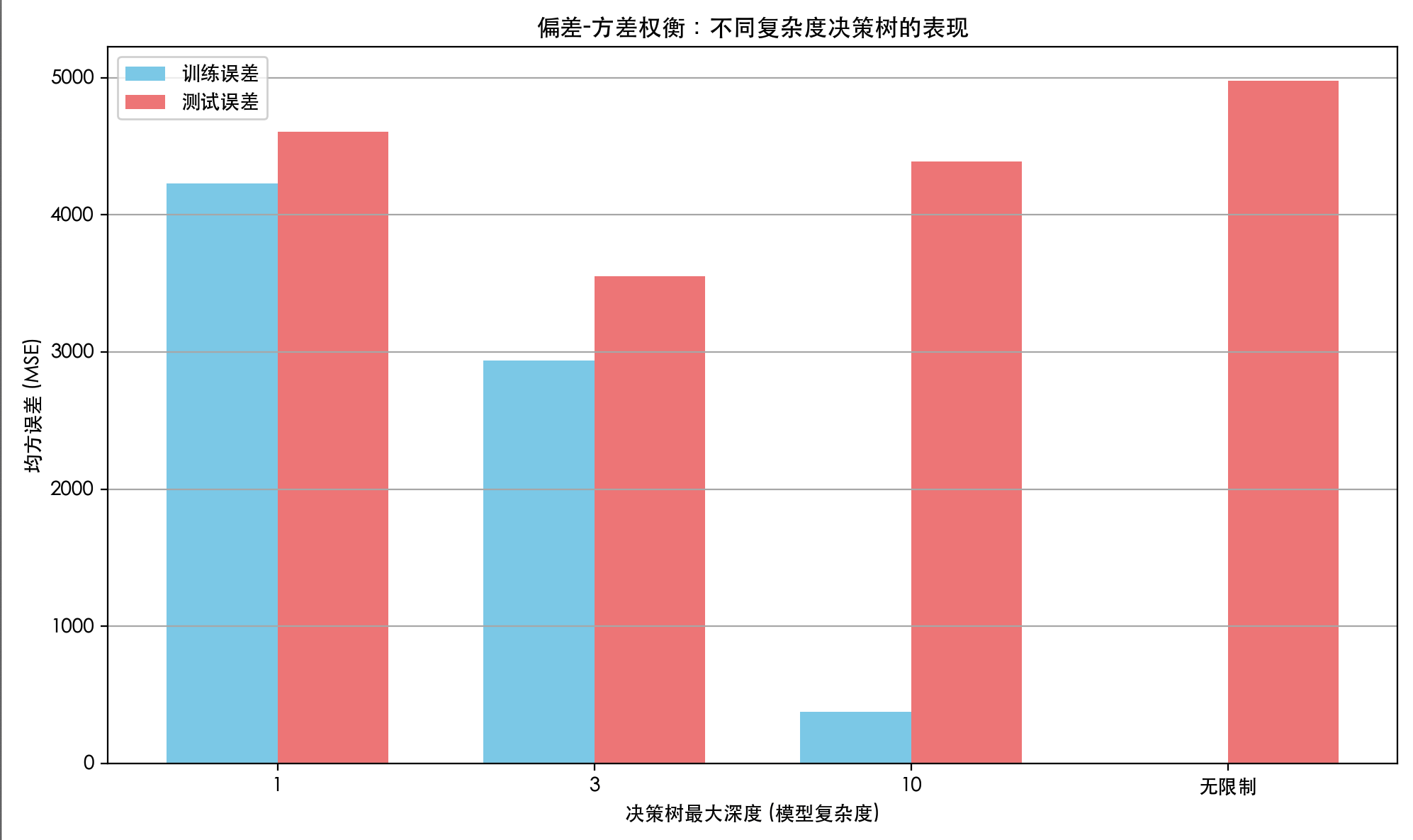
import numpy as np import matplotlib.pyplotas plt from sklearn.datasetsimport load_diabetes from sklearn.model_selectionimport train_test_split from sklearn.treeimport DecisionTreeRegressor from sklearn.metricsimport mean_squared_error