import numpy as np import matplotlib.pyplotas plt from sklearn import svm, datasets from sklearn.model_selectionimport train_test_split from sklearn.metricsimport accuracy_score
3. 加载数据集
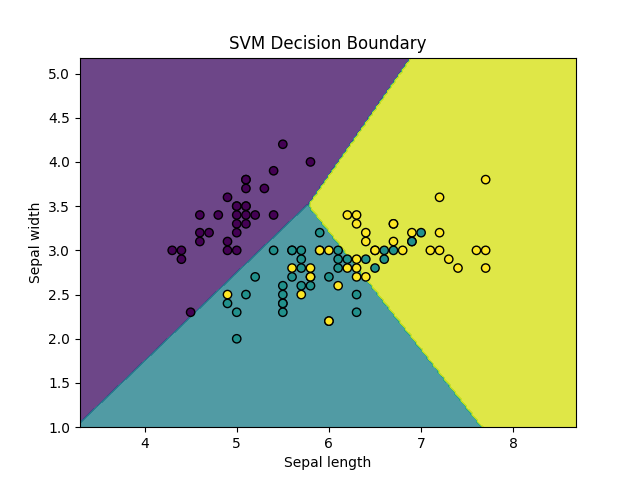
我们将使用 scikit-learn 自带的鸢尾花(Iris)数据集。
实例
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data[:, :2]# 只使用前两个特征
y = iris.target
import numpy as np import matplotlib.pyplotas plt from sklearn import svm, datasets from sklearn.model_selectionimport train_test_split from sklearn.metricsimport accuracy_score
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data[:, :2]# 只使用前两个特征
y = iris.target