| ��Kubernetes�У���С�Ĺ���Ԫ�ز���һ��������������������Pod,Pod����С�ģ��������������ƻ�����С��Ԫ.
ʲô��Pod
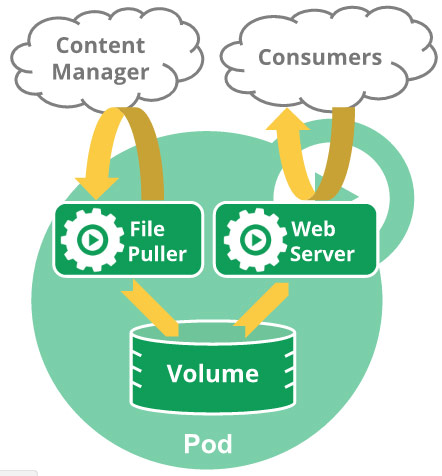
һ��Pod������һȺ���㣬����һ���㶹�У��൱��һ������context�������飬��ͬһ��context�£�Ӧ�ÿ��ܻ����ж�����cgroup������ƣ�һ��Pod��һ�����������µġ����������������ܰ���һ�����߶������������Ӧ�ã���ЩӦ�ÿ�������ͬһ������������������ϡ�
Pod ��context��������ɶ��linux�����ռ������
PID �����ռ䣨ͬһ��Pod��Ӧ�ÿ��Կ����������̣�
���� �����ռ䣨ͬһ��Pod���е�Ӧ�ö���ͬ��IP��ַ�Ͷ˿���Ȩ�ޣ�
IPC �����ռ䣨ͬһ��Pod�е�Ӧ�ÿ���ͨ��VPC����POSIX����ͨ�ţ�
UTS �����ռ䣨ͬһ��Pod�е�Ӧ�ù���һ���������ƣ�
ͬһ��Pod�е�Ӧ�ÿ��Թ������̣�������Pod���ģ�Ӧ�ÿ���ͨ���ļ�ϵͳ���ã�����ģ�һ��Pod���ܻᶨ�嶥����cgroup���룬�����Ļ����κ�һ��Ӧ�ã��ðɣ��������û��ô����������˵Pod��Ӧ�ã����룩
����docker�ļܹ���һ��Pod���ɶ����صIJ��ҹ������̵�������ɣ�Pid�������ռ乲����û��Ӧ�õ�Docker��
�������������һ����Pod��һ����Զ��ݵĴ��ڣ������dz־ô��ڵģ�����������Pod�������������ᵽ�ģ�Pod�����ŵ�����ϣ����ұ���������ڵ���ֱ������ֹ�������������趨�����߱�ɾ������һ���ڵ�����֮�����������Pod���ᱻɾ���������Pod��Զ���ᱻת�Ƶ��������Ľڵ㣬��Ϊ��������DZ��뱻replace.
Pod�ķ�չ
��Դ�Ĺ�����ͨ��
PodʹPod�ڵ����ݹ�����ͨ�ű������
Pod���е�Ӧ�þ�ʹ����ͬ�����������ռ估�˿ڣ����ҿ���ͨ��localhost���ֲ���ͨ����Ӧ�ã�ÿ��Pod����һ����ƽ�������������ռ���IP��ַ������Pod���Ժ��������������������������������ϰ�ͨ�ţ���The
hostname is set to the pod��s Name for the application
containers within the pod��������������ΪPod�����ƣ����û�����������
���˶�������Pod�����е�Ӧ��֮�⣬Pod��������һϵ�еĹ����Ĵ��̣���������Щ����������������ʱ�ض�ʧ���ҿ��Խ���Щ������Pod�е�Ӧ�ý��й���
����
Podͨ���ṩһ���߲�γ�������ǵײ�Ľӿڼ���Ӧ�õIJ�������Pod ��Ϊ��С�IJ�������λ��λ�ù������������ƣ���Դ������������ϵ�����Զ������ġ���fate
sharing���ƾ�˵ʲôʱ������ˣ�ʲôʱ�������һ���ˡ���
Pod��ʹ��
Pod������Ϊ��ֱӦ�����ϵ����壬����������Ҫ�ص���֧��ͬ��Э����ͬ�ع����������磺
���ݹ���ϵͳ���ļ������ݼ��أ����ػ���ȵ�
��־�ͼ��㱸�ݣ�ѹ����ѭ�������յȵ�
���ݽ�����أ���־�٣���־��¼�ͼ�����������Լ��¼������ȵ�
���������ţ�������
���ƣ����������ã�����
������˵��������Pod����ȥ���ض����ͬ��Ӧ��ʵ��
���ǹ�����������
Ϊʲô��ֱ����һ���������������е�Ӧ�ã�
����Pod�е������Ի�����ʩ�ɼ�ʹ�Ļ�����ʩ���Ը������ṩ���������̹߳�������Դ��أ���Ϊ�û��ṩ�ܶ����
��������������ϵ,�������������Զ����Ľ����ؽ������·�����Kubernetes �������ڽ���֧�ֶ���������ʵʱ����
���ã��û�����Ҫ�����Լ����̹߳�������Ҳ����Ҫ���ij�����ź��Լ��쳣�������
��Ч����Ϊ������ʩ�����˸�������Σ������������Ը��Ӹ�Ч
Ϊʲô��֧��������Эͬ����
������Эͬ���ȿ����ṩ�����������߱�Pod�Ĵ�����ŵ㣬������Դ������IPC��ѡ����ƣ�������
Pod�ij־���
Pod�����DZ���Ƴ�һ���־û�����Դ���������ڵ���ʧ�ܣ��ڵ�������������������У�������Ϊ��Դ��ȱ��������������ά���У��Ҵ�����
������˵���û����ֱ��ȥ����Pod������һֱʹ��controller(replication
controller),��ʹ��һ���ڵ�������������Ϊcontroller�ṩ�˼�Ⱥ��Χ�ڵ����������Լ����ƻ���չʾ����
��ȺAPI��ʹ�����û�����Ҫʹ�÷�ʽ����������ձ���������ƹ���ƽ̨�У� Borg, Marathon,
Aurora, and Tupperware.��
Pod��ֱ�ӱ�¶�����²�����ø�����
���Ⱥ�����������
��û�д����������ͨ��API���Զ�Pod���в���
Pod��������������������������ڵķ���
��ż�������ͷ���ι������������Pod
���������Kubelet����Ĺ�������ƽ̨����Ĺ��ܣ�kubelet ʵ������һ��Pod������
�߿��ã�������һЩɾ������ά���Ĺ���ʱ��Pod���Զ��������DZ���ֹ֮ǰ�����µ����
Ŀǰ���ڳ�������ʵ���ǣ�����һ����������1���ж�Ӧservice��һ��replication������������������̫�鷳����������������������
��������ֹ
��Ϊpod������һ����Ⱥ�нڵ������еĽ��̣�����Щ���̲��ٱ���Ҫ�����ŵ��˳��Ǻ���Ҫ�ģ���ֱ�����һ��KILL�ź�ȥ��������Ӧ��û�л�������������������û�Ӧ��������ɾ�����������ҽ�����ֹ���������֪��������Ҳ�ܱ�֤ɾ��������ɡ���һ���û�����ɾ��pod��ϵͳ��¼��Ҫ�������˳�ʱ��Σ�����֮ǰPod��������ǿ�Ƶ�ɱ����TERM�źŻᷢ��������Ҫ�Ľ��̡�һ�������˳��������ˣ�KILL�źŻ��͵���Щ���̣�pod���API���������б�ɾ��������ڵȴ����̽�����ʱ��Kubelet�������������������ˣ������Ĺ��̻���������������˳�ʱ��ν������ԡ�
һ��ʾ�����̣�
1. �û�����һ��������ɾ��Pod��Ĭ�ϵ������˳�ʱ����30��
2. API�������е�Pod����ʱ�䣬������ʱ��Pod����Ϊ����
3. �ڿͻ�������ĵ����棬Pod��ʾΪ��Terminating���˳��У�����״̬
4. �����3ͬʱ����Kubelet����Pod���Ϊ�˳��е�ʱ����Ϊ��2����ʱ���Ѿ������ˣ�����ʼpod�رյ�����
i. �����Pod������һ��ֹͣǰ�Ĺ��ӣ������pod�ڲ������á���������������˳�ʱ��γ�ʱ��Ȼ�����У��ڶ�������һ����С������ʱ��ϱ�����
ii. ���̱�����TERM���ź�
5. ���������ͬʱ���У�Pod��service���б��б�ɾ�������ڱ���Ϊ�������ŵ�pod��һ���֡������رյ�pod���Լ�������������ؾ����������������Ƴ���
6. �������˳�ʱ�䳬ʱ�ˣ��κ�pod���������еĽ��̻ᱻ����SIGKILL�źű�ɱ����
7. Kubelet�����pod��ɾ�����������˳���ʱ������Ϊ0����ʾ����ɾ������pod��API��ɾ�������ڶԿͻ��˿ɼ���
Ĭ������£����е�ɾ�������������˳�ʱ�䶼��30�����ڡ�kubectl delete����֧�֨Cgraceperiod=��ѡ��������û�����Ĭ��ֵ��0��ʾɾ������ִ�У�����������API��ɾ��pod����һ���µ�pod����ͬʱ���������ڽڵ��ϣ������������������ĵ�pod����Ȼ���һ���̵ܶ������˳�ʱ��Σ��ŻῪʼ��ǿ��ɱ����
ʹ��Volume
Volume����Ϊ�����ṩ�־û��洢������
apiVersion:
v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
volumeMounts:
- name: redis-storage
mountPath: /data/redis
volumes:
- name: redis-storage
emptyDir: {} |
������ش洢���ķ����ο�Volume��
˽�о���
��ʹ��˽�о���ʱ����Ҫ����һ��docker registry secret���������������á�
����docker registry secret��
kubectl
create secret docker-registry regsecret
--docker-server=<your-registry-server>
--docker-username=<your-name> --docker-password=<your-pword>
--docker-email=<your-email> |
���������ø�secret��
apiVersion:
v1
kind: Pod
metadata:
name: private-reg
spec:
containers:
- name: private-reg-container
image: <your-private-image>
imagePullSecrets:
- name: regsecret |
RestartPoliy
֧������RestartPolicy
Always��ֻҪ�˳�������
OnFailure��ʧ���˳���exit code������0��ʱ����
Never��ֻҪ�˳��Ͳ�������
ע�⣬�����������ָ��Pod����Node���汾����������������ȵ�����Node��ȥ��
��������
��������Ϊ�����ṩ��һЩ��Ҫ����Դ������������Pod�Ļ�����Ϣ�Լ���Ⱥ�з������Ϣ�ȣ�
(1) hostname
HOSTNAME�������������˸�Pod��hostname��
��2��������Pod�Ļ�����Ϣ
Pod�����֡������ռ䡢IP�Լ������ļ�����Դ���Ƶȿ�����Downward API�ķ�ʽ��ȡ���洢�����������С�
|
apiVersion:
v1
kind: Pod
metadata:
name: test
spec:
containers:
- name: test-container
image: gcr.io/google_containers/busybox
command: [ "sh", "-c"]
args:
- env
resources:
requests:
memory: "32Mi"
cpu: "125m"
limits:
memory: "64Mi"
cpu: "250m"
env:
- name: MY_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: MY_POD_SERVICE_ACCOUNT
valueFrom:
fieldRef:
fieldPath: spec.serviceAccountName
- name: MY_CPU_REQUEST
valueFrom:
resourceFieldRef:
containerName: test-container
resource: requests.cpu
- name: MY_CPU_LIMIT
valueFrom:
resourceFieldRef:
containerName: test-container
resource: limits.cpu
- name: MY_MEM_REQUEST
valueFrom:
resourceFieldRef:
containerName: test-container
resource: requests.memory
- name: MY_MEM_LIMIT
valueFrom:
resourceFieldRef:
containerName: test-container
resource: limits.memory
restartPolicy: Never |
(3) ��Ⱥ�з������Ϣ
�����Ļ��������л���������������ǰ���������з������Ϣ������Ĭ�ϵ�kubernetes�����Ӧ�˻�������
|
KUBERNETES_PORT_443_TCP_ADDR=10.0.0.1
KUBERNETES_SERVICE_HOST=10.0.0.1
KUBERNETES_SERVICE_PORT=443
KUBERNETES_SERVICE_PORT_HTTPS=443
KUBERNETES_PORT=tcp://10.0.0.1:443
KUBERNETES_PORT_443_TCP=tcp://10.0.0.1:443
KUBERNETES_PORT_443_TCP_PROTO=tcp
KUBERNETES_PORT_443_TCP_PORT=443 |
���ڻ����������ڴ���˳��ľ����ԣ����������в��������������ķ����Ƽ�ʹ��DNS����������
ImagePullPolicy
֧������ImagePullPolicy
Always�����ܾ����Ƿ���ڶ������һ����ȡ��
Never�����ܾ����Ƿ���ڶ����������ȡ
IfNotPresent��ֻ�о�����ʱ���Ż���о�����ȡ��
ע�⣺
Ĭ��ΪIfNotPresent����:latest��ǩ�ľ���Ĭ��ΪAlways��
��ȡ����ʱdocker�����У�飬��������е�MD5��û�б䣬����ȡ�������ݡ�
����������Ӧ�þ�������ʹ��:latest��ǩ�������������п��Խ���:latest��ǩ�Զ���ȡ���µľ���
��Դ����
Kubernetesͨ��cgroups����������CPU���ڴ�ȼ�����Դ������requests������������֤���ȵ���Դ�����Node�ϣ���limits�����ޣ��ȣ�
spec.containers[] .resources.limits.cpu��CPU���ޣ����Զ��ݳ���������Ҳ���ᱻֹͣ
spec.containers[] .resources.limits.memory���ڴ����ޣ������Գ���������������������ܻᱻֹͣ����ȵ�������Դ����Ļ�����
spec.containers[] .resources.requests.cpu��CPU�����Գ���
spec.containers[].resources.requests.memory���ڴ������Գ�����������������������ܻ���Node�ڴ治��ʱ����
����nginx��������30%��CPU��56MB���ڴ棬���������ֻ��50%��CPU��128MB���ڴ棺
|
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx
name: nginx
spec:
containers:
- image: nginx
name: nginx
resources:
requests:
cpu: "300m"
memory: "56Mi"
limits:
cpu: "500m"
memory: "128Mi" |
ע�⣬CPU�ĵ�λ��milicpu��500mcpu=0.5cpu�����ڴ�ĵ�λ�����E, P,
T, G, M, K, Ei, Pi, Ti, Gi, Mi, Ki�ȡ�
�������
Ϊ��ȷ�������ڲ����ȷʵ������������״̬��Kubernetes�ṩ������̽�루Probe��֧��exec��tcp��httpGet��ʽ����̽��������״̬��
LivenessProbe��̽��Ӧ���Ƿ��ڽ���״̬�������������ɾ���ؽ�������
ReadinessProbe��̽��Ӧ���Ƿ�������ɲ��Ҵ�����������״̬����������������������״̬
|
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx
name: nginx
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: http
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 15
timeoutSeconds: 1
readinessProbe:
httpGet:
path: /ping
port: 80
initialDelaySeconds: 5
timeoutSeconds: 1 |
Init Container
Init Container��������������֮ǰִ�У�run-to-completion������������ʼ�����á�
|
apiVersion: v1
kind: Pod
metadata:
name: init-demo
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: workdir
mountPath: /usr/share/nginx/html
# These containers are run during pod initialization
initContainers:
- name: install
image: busybox
command:
- wget
- "-O"
- "/work-dir/index.html"
- http://kubernetes.io
volumeMounts:
- name: workdir
mountPath: "/work-dir"
dnsPolicy: Default
volumes:
- name: workdir
emptyDir: {} |
�����������ڹ���
�����������ڹ��ӣ�Container Lifecycle Hooks�����������������ڵ��ض��¼��������¼�����ʱִ����ע��Ļص�������֧�����ֹ��ӣ�
postStart�� ����������ִ�У�ע���������첽ִ�У�������֤һ����ENTRYPOINT֮�����С����ʧ�ܣ������ᱻɱ����������RestartPolicy�����Ƿ�����
preStop������ֹͣǰִ�У���������Դ���������ʧ�ܣ�����ͬ��Ҳ�ᱻɱ��
�����ӵĻص�����֧�����ַ�ʽ��
exec����������ִ������
httpGet����ָ��URL����GET����
postStart��preStop����ʾ����
|
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c",
"echo Hello from the postStart handler
> /usr/share/message"]
preStop:
exec:
command: ["/usr/sbin/nginx","-s","quit"] |
ָ��Node
ͨ��nodeSelector��һ��Pod����ָ��������Ҫ���е�Node�ڵ㡣
���ȸ�Node���ϱ�ǩ��
|
kubectl label nodes <your-node-name>
disktype=ssd |
���ţ�ָ����Podֻ�������ڴ���disktype=ssd��ǩ��Node�ϣ�
|
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
disktype: ssd |
ʹ��Capabilities
Ĭ������£����������Է���Ȩ�����ķ�ʽ���С����磬�����������д������������������������硣
Kubernetes�ṩ����Capabilities�Ļ��ƣ�������Ҫ�����������ӻ�ɾ����������������ø�����������CAP_NET_ADMIN��ɾ����CAP_KILL��
|
apiVersion: v1
kind: Pod
metadata:
name: hello-world
spec:
containers:
- name: friendly-container
image: "alpine:3.4"
command: ["/bin/echo", "hello",
"world"]
securityContext:
capabilities:
add:
- NET_ADMIN
drop:
- KILL |
�����������
����ͨ����Pod����kubernetes.io/ingress-bandwidth��kubernetes.io/egress-bandwidth������annotation������Pod���������
|
apiVersion: v1
kind: Pod
metadata:
name: qos
annotations:
kubernetes.io/ingress-bandwidth: 3M
kubernetes.io/egress-bandwidth: 4M
spec:
containers:
- name: iperf3
image: networkstatic/iperf3
command:
- iperf3
- -s |
��kubenet֧�����ƴ���
Ŀǰֻ��kubenet������֧�������������������CNI�������ݲ�֧��������ܡ�
kubenet���������������ʵ��ͨ��tc��ʵ�ֵ�
|
# setup qdisc (only once)
tc qdisc add dev cbr0 root handle 1: htb
default 30
# download rate
tc class add dev cbr0 parent 1: classid
1:2 htb rate 3Mbit
tc filter add dev cbr0 protocol ip parent
1:0 prio 1 u32 match ip dst 10.1.0.3/32
flowid 1:2
# upload rate
tc class add dev cbr0 parent 1: classid
1:3 htb rate 4Mbit
tc filter add dev cbr0 protocol ip parent
1:0 prio 1 u32 match ip src 10.1.0.3/32
flowid 1:3 |
���ȵ�ָ����Node��
����ͨ��nodeSelector��nodeAffinity��podAffinity�Լ�Taints��tolerations������Pod���ȵ���Ҫ��Node�ϡ�����ʹ�÷�����ο��������½� |









