| 在下面的例子中,你会学习使用Kubernetes和Docker创建一个能够使用的阿帕奇Spark集群。我们使用Spark的单例模式创建一个Spark
master节点服务和一系列Spark workers节点。
对于不耐心的专家,直接跳到这个部分
资源
Docker镜像很重,基于https://github.com/mattf/docker-spark
步骤0:预备知识
下面的例子假设你已经安装和运行一个Kubernetes集群,并且你也下载好kubectl命令行工具以及配置在你的path中。
步骤一:启动Master服务
Master服务是一个Spark集群的主服务(或头服务)。
使用examples/spark/spark-master.json文件创建运行在Master服务中的pod。
| $
kubectl create -f examples/spark/spark-master.json |
然后使用examples/spark/spark-master-service.json文件创建一个逻辑服务端点供Spark
workers节点使用连接Matser pod。
| $
kubectl create -f examples/spark/spark-master-service.json |
检查Master节点使用运行并且能够连接

检查日志查看master节点的状态:
| $
kubectl logs spark-master
starting org.apache.spark.deploy.master.Master,
logging to /opt/spark-1.4.0-bin-hadoop2.6/sbin/../logs/spark--org.apache.spark.deploy.master.Master-1-spark-master.out
Spark Command: /usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java
-cp /opt/spark-1.4.0-bin-hadoop2.6/sbin/../conf/:/opt/spark-1.4.0-bin-hadoop2.6/lib/spark-assembly-1.4.0-hadoop2.6.0.jar:/opt/spark-1.4.0-bin-hadoop2.6/lib/datanucleus-api-jdo-3.2.6.jar:/opt/spark-1.4.0-bin-hadoop2.6/lib/datanucleus-rdbms-3.2.9.jar:/opt/spark-1.4.0-bin-hadoop2.6/lib/datanucleus-core-3.2.10.jar
-Xms512m -Xmx512m -XX:MaxPermSize=128m org.apache.spark.deploy.master.Master
--ip spark-master --port 7077 --webui-port
8080
========================================
15/06/26 14:01:49 INFO Master: Registered
signal handlers for [TERM, HUP, INT]
15/06/26 14:01:50 WARN NativeCodeLoader:
Unable to load native-hadoop library for
your platform... using builtin-java classes
where applicable
15/06/26 14:01:51 INFO SecurityManager:
Changing view acls to: root
15/06/26 14:01:51 INFO SecurityManager:
Changing modify acls to: root
15/06/26 14:01:51 INFO SecurityManager:
SecurityManager: authentication disabled;
ui acls disabled; users with view permissions:
Set(root); users with modify permissions:
Set(root)
15/06/26 14:01:51 INFO Slf4jLogger: Slf4jLogger
started
15/06/26 14:01:51 INFO Remoting: Starting
remoting
15/06/26 14:01:52 INFO Remoting: Remoting
started; listening on addresses :[akka.tcp://sparkMaster@spark-master:7077]
15/06/26 14:01:52 INFO Utils: Successfully
started service 'sparkMaster' on port 7077.
15/06/26 14:01:52 INFO Utils: Successfully
started service on port 6066.
15/06/26 14:01:52 INFO StandaloneRestServer:
Started REST server for submitting applications
on port 6066
15/06/26 14:01:52 INFO Master: Starting
Spark master at spark://spark-master:7077
15/06/26 14:01:52 INFO Master: Running Spark
version 1.4.0
15/06/26 14:01:52 INFO Utils: Successfully
started service 'MasterUI' on port 8080.
15/06/26 14:01:52 INFO MasterWebUI: Started
MasterWebUI at http://10.244.2.34:8080
15/06/26 14:01:53 INFO Master: I have been
elected leader! New state: ALIVE |
步骤二:启动Spark workers
在Spark集群中Spark workers做繁重的工作。它们为你的程序提供计算资源和数据缓存的能力。
Spark workers需要Master服务支持才能运行。
使用examples/spark/spark-worker-controller.json文件创建复制控制器管理workers
pod。
| $
kubectl create -f examples/spark/spark-worker-controller.json |
检查workers节点是否运行

步骤三:使用集群做点什么
获取Master服务的地址和端口。

使用SSH连接集群中的一个节点,在GCE/GKE(【译者注】指云服务谷歌计算引擎和谷歌Kubernetes引擎)上,你可以使用开发者控制台或者运行gcloud
compute ssh ,name可以通过kubectl get nodes命令获得。

一旦登陆成功就可以使用Spark基础镜像了。在镜像中有一个脚本用来设置基于Master的IP和端口环境。
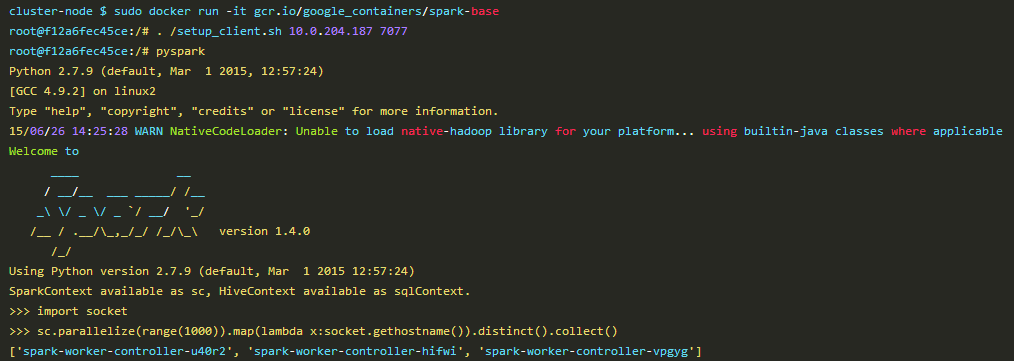
结果
现在你已经为你的Spark master节点和Spark workers节点创建了服务、复制控制器和pods。你可以在下一篇文档中继续使用这个例子以及使用这个Spark集群。点击Spark文档获取更多信息。
tl;dr
| kubectl
create -f spark-master.json
kubectl create -f spark-master-service.json
Make sure the Master Pod is running (use:
kubectl get pods).
kubectl create -f spark-worker-controller.json |
|









