注意力机制(Attention Mechanism)是深度学习中的一种重要技术,它模仿了人类视觉和认知过程中的注意力分配方式。就像你在阅读时会不自觉地将注意力集中在关键词上一样,注意力机制让神经网络能够动态地关注输入数据中最相关的部分。
基本概念
注意力机制的核心思想是: 根据输入的不同部分对当前任务的重要性,动态分配不同的权重 。这种权重分配不是固定的,而是根据上下文动态计算的。
数学表达
注意力机制通常可以表示为:
Attention(Q, K, V) = softmax(QK^T/√d_k)V
其中:
为什么需要注意力机制?
自注意力机制(Self-Attention)
自注意力是注意力机制的一种特殊形式,它允许输入序列中的每个元素都与序列中的所有其他元素建立联系。
工作原理
实例
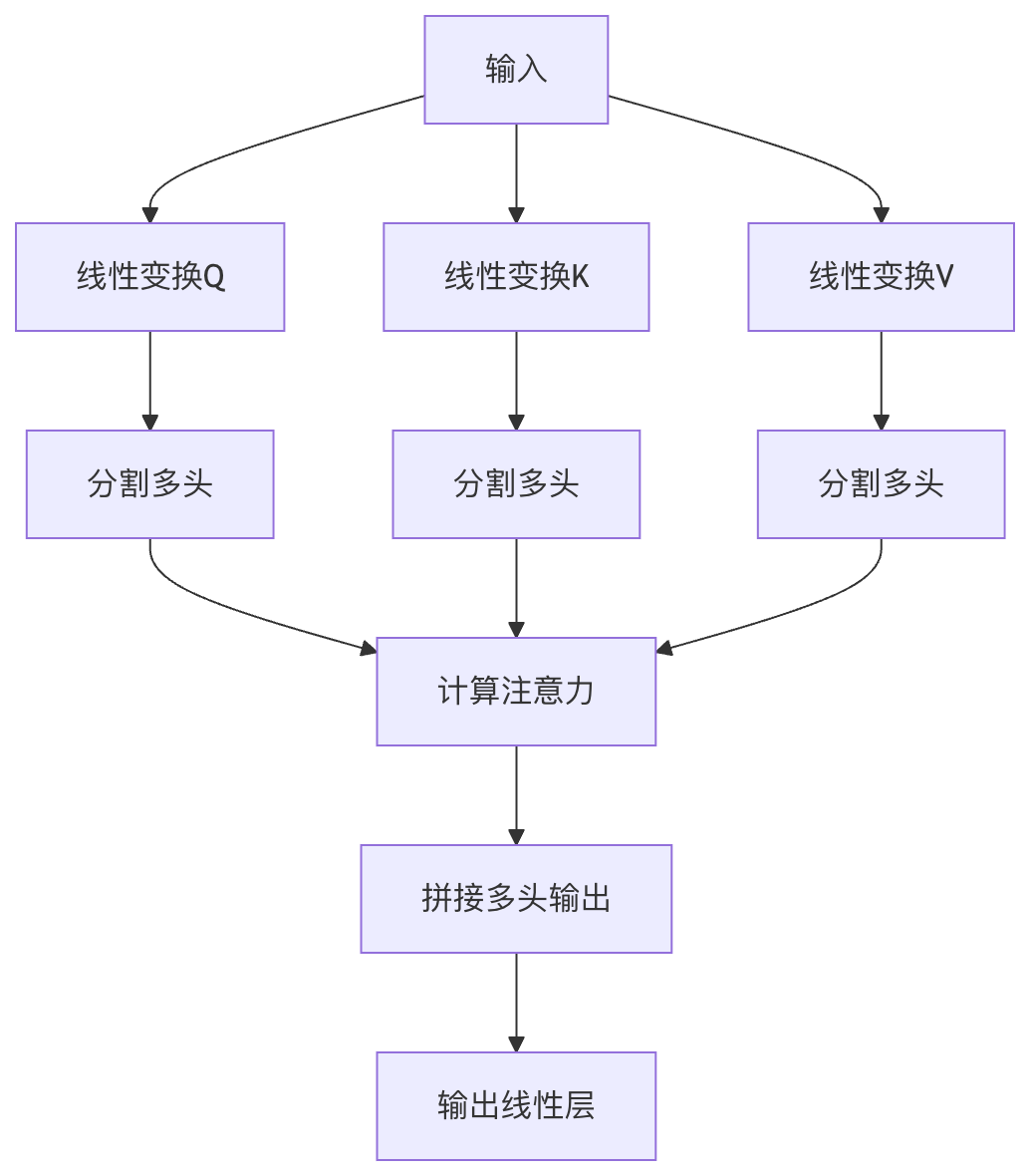
多头注意力(Multi-Head Attention)
多头注意力是自注意力的扩展,它将注意力机制并行执行多次,然后将结果拼接起来。
结构组成
多头注意力的优势
注意力机制在NLP中的应用
注意力机制已经成为现代NLP系统的核心组件,特别是在Transformer架构中。
主要应用场景
机器翻译 :
文本摘要 :
问答系统 :
语言模型 :
实际案例:BERT中的注意力
BERT(Bidirectional Encoder Representations from Transformers)是使用注意力机制的典型代表:
注意力机制的变体与扩展
1. 缩放点积注意力(Scaled Dot-Product Attention)
2. 加法注意力(Additive Attention)
3. 局部注意力(Local Attention)
4. 稀疏注意力(Sparse Attention)
实践练习
练习1:实现基础注意力机制
练习2:可视化注意力权重
总结与进阶学习
注意力机制已经成为现代深度学习的基石技术,特别是在NLP领域。要深入学习:
阅读原始论文 :
实践项目建议 :
扩展应用领域 :
注意力机制的发展仍在继续,理解其核心原理将帮助你更好地掌握现代深度学习技术。