预训练模型(Pre-trained Models)是自然语言处理(NLP)领域近年来最重要的技术突破之一。这类模型通过在大规模文本数据上进行预先训练,学习通用的语言表示能力,然后可以针对特定任务进行微调(Fine-tuning)。
核心思想
与传统方法的对比
预训练模型的发展历程
1. 词嵌入时代(2013-2017)
实例
2. 上下文感知时代(2018-2019)
3. Transformer时代(2019至今)
主流预训练模型架构
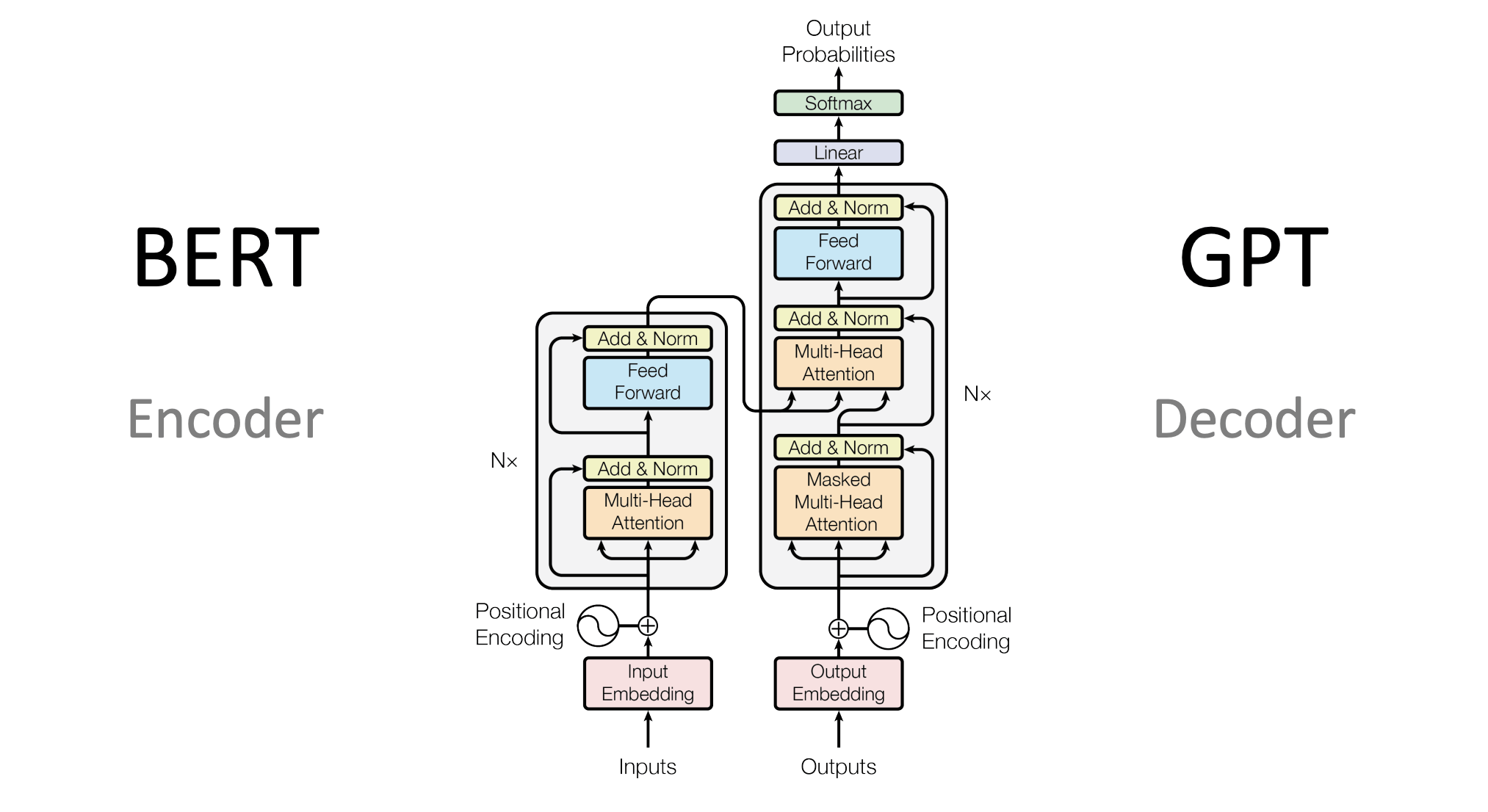
1. Encoder架构(BERT系列)
2. Decoder架构(GPT系列)
3. Encoder-Decoder架构
预训练任务类型
1. 语言模型(LM)
2. 掩码语言模型(MLM)
3. 下一句预测(NSP)
4. 其他任务
如何使用预训练模型
1. 使用Hugging Face Transformers
2. 模型微调流程
3. 关键参数说明
预训练模型的应用场景
1. 文本分类
2. 问答系统
3. 文本生成
4. 其他应用
实践建议
模型选择 :
资源管理 :
性能优化 :
持续学习 :
未来发展方向
预训练模型正在重塑NLP领域的技术格局,理解其核心原理和掌握应用方法,将成为NLP工程师的必备技能。