生成式预训练模型是一类通过大规模无监督学习从文本数据中获取通用语言知识,并能够生成连贯、合理文本的深度学习模型。这类模型的核心特点是:
一、GPT 系列模型发展历程
1.1 GPT-1:开创性的起点
GPT-1 (Generative Pre-trained Transformer) 于 2018 年由 OpenAI 发布,首次展示了大规模无监督预训练+有监督微调的有效性。
核心特点 :
1.2 GPT-2:规模化的突破
2019 年发布的 GPT-2 证明了模型规模与性能的正相关关系。
关键升级 :
1.3 GPT-3:量变到质变
2020 年推出的 GPT-3 实现了 few-shot 学习能力,参数规模达到 1750 亿。
革命性进步 :
1.4 GPT-4 及后续发展
2023 年发布的 GPT-4 进一步扩展了模型能力边界。
最新进展 :
二、自回归语言模型原理
2.1 基本概念
自回归 (Autoregressive) 语言模型通过前文预测下一个词的概率分布:
P(x_t | x_<t) = P(x_t | x_1, x_2, ..., x_{t-1})
2.2 数学原理
给定词序列 x = (x₁, ..., xₙ),联合概率分解为:
P(x) = ∏ P(x_t | x_<t)
使用最大似然估计进行训练:
L(θ) = ∑ log P(x_t | x_<t; θ)
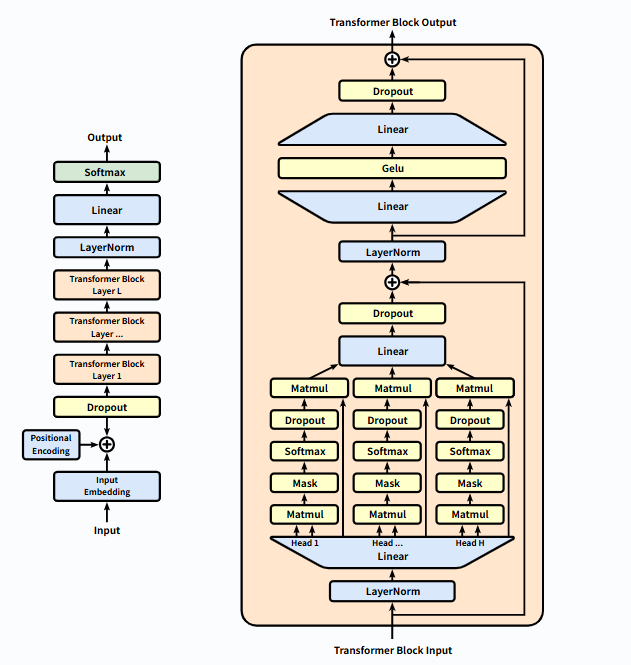
2.3 Transformer 解码器架构
关键组件:
1.掩码自注意力 :
# PyTorch 伪代码 attn_mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1)
2.位置编码 :注入序列顺序信息
3.前馈网络 :逐位置特征变换
三、文本生成技术详解
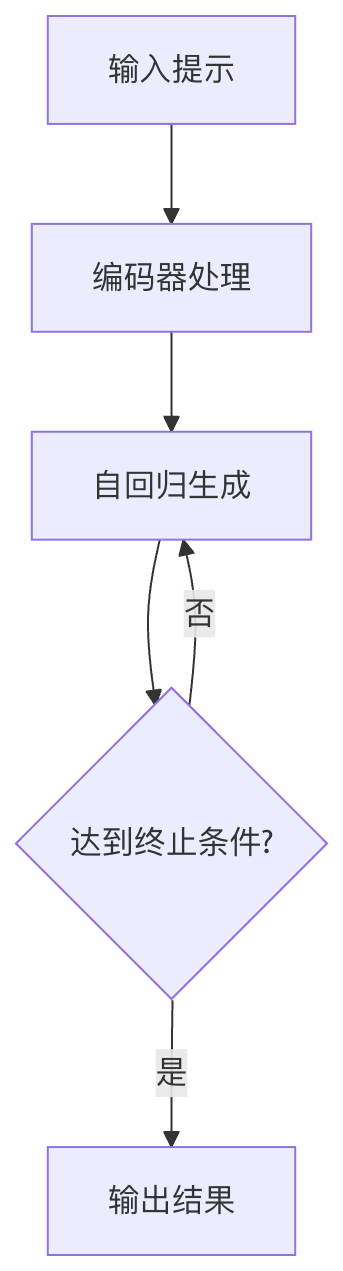
3.1 生成过程
典型文本生成流程:
3.2 解码策略对比
3.3 生成控制参数
关键参数示例:
实例
四、Prompt Engineering 基础
4.1 核心原则
4.2 实用技巧
1.角色设定 :
你是一位资深机器学习工程师,请用通俗语言解释...
2.步骤分解 :
请按以下步骤解决问题: 1. 首先分析... 2. 然后计算... 3. 最后输出...
3.格式指定 :
请用JSON格式输出,包含字段:summary, keywords, confidence
4.3 典型模式
1.指令模板 :
任务:文本分类 输入:{text} 选项:positive, neutral, negative 输出:
2.**思维链 (CoT)**:
请逐步推理:首先... 其次... 因此结论是...
五、实践练习
5.1 基础生成
5.2 参数调优实验
设计对比实验观察不同参数影响:
5.3 Prompt 优化挑战
给定基础 prompt:
写一篇关于气候变化的文章
优化方向:
通过系统学习 GPT 模型的发展历程、自回归原理、生成技术和 Prompt 工程,开发者可以更好地利用现代大语言模型的能力。建议从简单 prompt 开始,逐步实验不同生成参数,观察模型行为变化,最终掌握高效使用生成式 AI 的方法论。