BERT(Bidirectional Encoder Representations from Transformers)是2018年由Google提出的革命性自然语言处理模型,它彻底改变了NLP领域的研究和应用范式。
本文将系统介绍BERT的核心原理、训练方法、微调技巧以及主流变体模型。
BERT的架构与训练
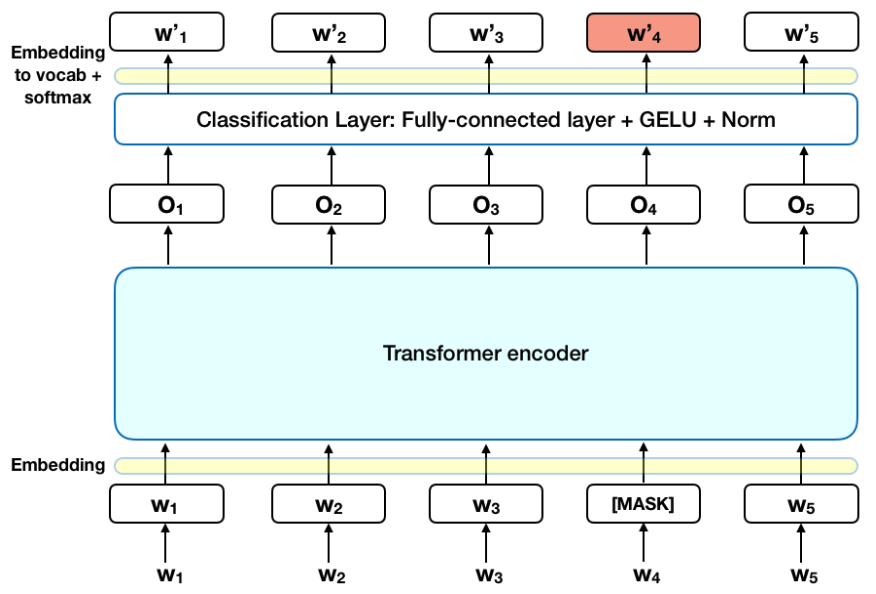
下图展示了 BERT(Bidirectional Encoder Representations from Transformers) 模型的核心架构和预训练过程中的掩码语言建模(Masked Language Modeling, MLM)任务。
1. 输入层(Embedding)
2. Transformer 编码器(Transformer Encoder)
3. 掩码语言建模(MLM)任务
Transformer编码器结构
BERT基于Transformer的编码器部分构建,其核心是多层自注意力机制:
实例
关键创新:双向上下文建模
与传统语言模型不同,BERT通过以下两种预训练任务实现双向上下文理解:
训练参数与配置
BERT的微调方法
标准微调流程
高效微调技术
常用微调策略对比
主流BERT变体模型
RoBERTa (Robustly Optimized BERT)
ALBERT (A Lite BERT)
其他重要变体
中文BERT模型
中文预训练模型概览
中文BERT使用示例
中文任务微调建议
实践建议与资源
学习路线图
推荐资源
通过系统学习和实践,BERT系列模型可以成为你解决NLP问题的强大工具。建议从基础版本开始,逐步探索更高级的变体和优化技术。