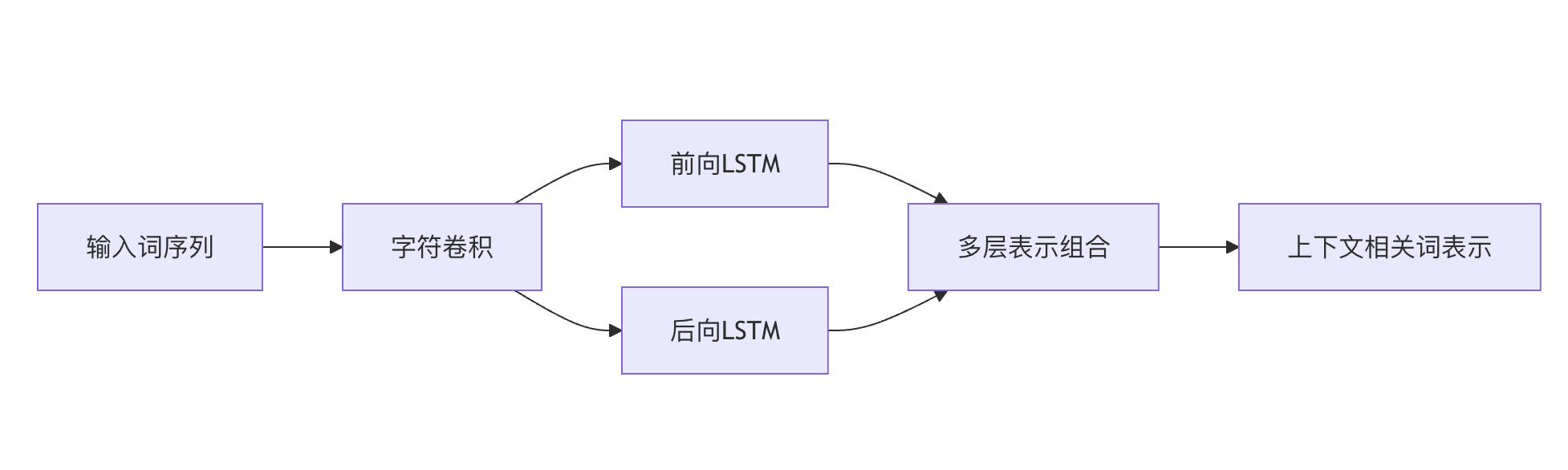
ELMo(Embeddings from Language Models)是最早的上下文相关词表示方法之一。
核心特点
基于双向LSTM语言模型
词语的表示取决于整个输入句子
生成多层表示(可以组合不同层次的语义)
架构示意图
BERT 及其变体
BERT(Bidirectional Encoder Representations from Transformers)是 Google 提出的预训练语言模型。
关键创新
Transformer 架构
掩码语言模型(MLM)训练目标
下一句预测(NSP)任务
常见变体
RoBERTa :优化训练策略
DistilBERT :轻量版BERT
ALBERT :参数共享减少模型大小
代码示例
实例
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
预训练语言模型概述
现代NLP主要使用预训练+微调范式:
预训练阶段 :在大规模语料上训练通用语言表示
微调阶段 :在特定任务数据上调整模型参数
模型比较
模型
发布时间
主要特点
Word2Vec
2013
静态词向量
GloVe
2014
全局统计+局部窗口
ELMo
2018
双向LSTM,上下文相关
BERT
2018
Transformer,双向上下文
GPT-3
2020
单向Transformer,生成能力强
文档级表示
Doc2Vec
Doc2Vec 是 Word2Vec 的扩展,可以直接学习文档的向量表示。
两种模型
PV-DM(Distributed Memory) :类似CBOW,加入文档ID
PV-DBOW(Distributed Bag of Words) :类似Skip-gram
代码示例
实例
from gensim.modelsimport Doc2Vec from gensim.models.doc2vecimport TaggedDocument
documents =[TaggedDocument(doc,[i])for i, doc inenumerate(corpus)]
model = Doc2Vec(documents, vector_size=100, window=5, min_count=1, workers=4)
vector = model.infer_vector(["new","document","text"])
句向量与文档向量
常用方法
平均法 :对词向量取平均
SIF :平滑逆频率加权平均
BERT句向量 :使用[CLS]标记或平均所有词向量
代码示例(使用Sentence-BERT)
实例
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences =["This is an example sentence","Each sentence is converted"]
embeddings = model.encode(sentences)
主题模型(LDA)
潜在狄利克雷分配(LDA)是一种无监督的主题建模方法。
基本原理
将文档表示为多个主题的混合
每个主题是词语的概率分布
通过变分推断或Gibbs采样学习
代码示例
实例
from sklearn.decompositionimport LatentDirichletAllocation from sklearn.feature_extraction.textimport CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
lda = LatentDirichletAllocation(n_components=2)
lda.fit(X)