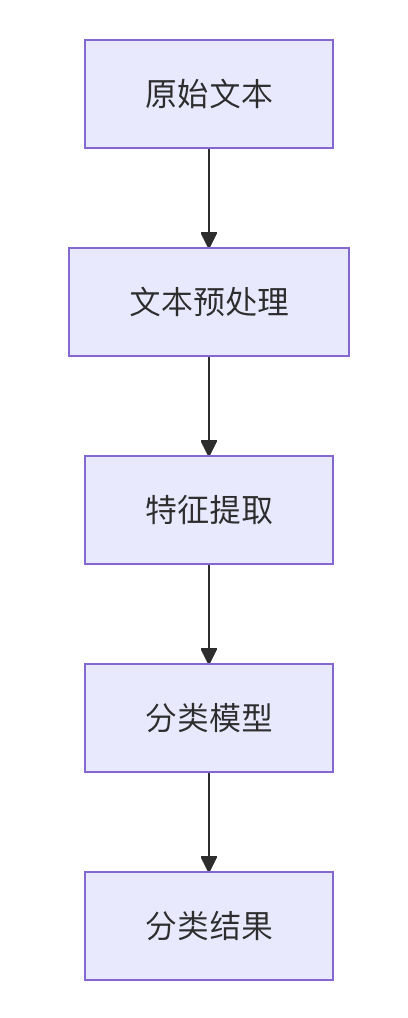
importre import nltk from nltk.corpusimport stopwords from nltk.stemimport PorterStemmer
def preprocess_text(text): # 转换为小写
text = text.lower() # 移除特殊字符和数字
text =re.sub(r'[^a-zA-Z\s]','', text) # 分词
words = text.split() # 移除停用词
stop_words =set(stopwords.words('english'))
words =[word for word in words if word notin stop_words] # 词干提取
stemmer = PorterStemmer()
words =[stemmer.stem(word)for word in words] return' '.join(words)