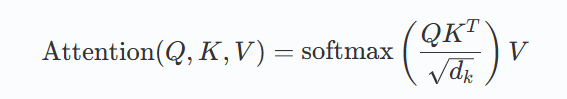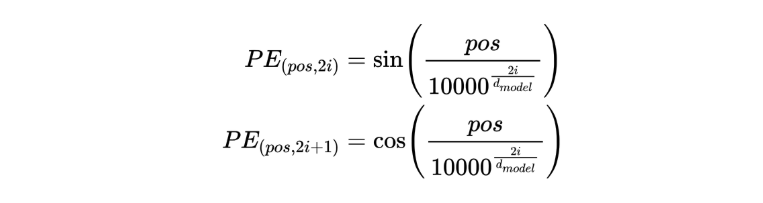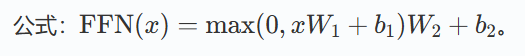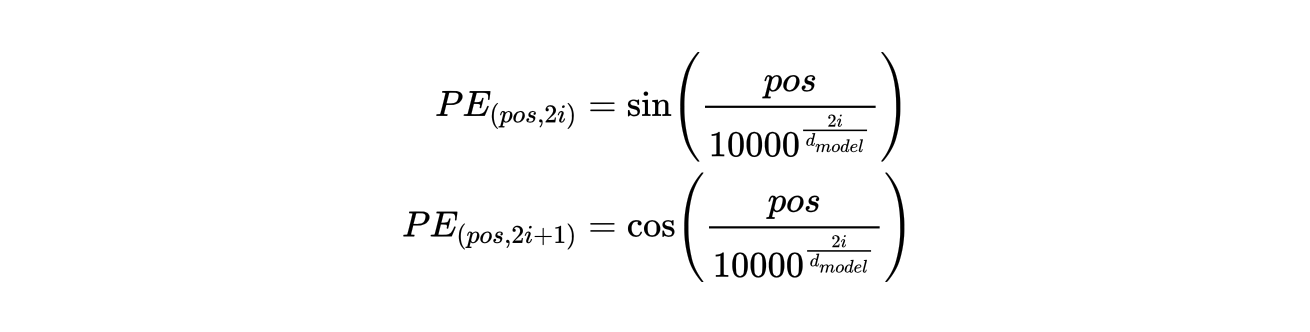Transformer 架构是一种基于自注意力机制(Self-Attention)的深度学习模型,由 Google 团队在 2017 年的论文 《Attention Is All You Need》 中首次提出。
Transformer 彻底改变了自然语言处理(NLP)领域,并成为现代大语言模型(如GPT、BERT等)的核心基础。
Transformer 与循环神经网络(RNN)类似,旨在处理自然语言等顺序输入数据,适用于机器翻译、文本摘要等任务。然而,与 RNN 不同,Transformer 无需逐步处理序列,而是可以一次性并行处理整个输入。
本章节将带你深入了解Transformer的核心思想、架构组成和工作原理,帮助你掌握这一革命性技术的基础知识。
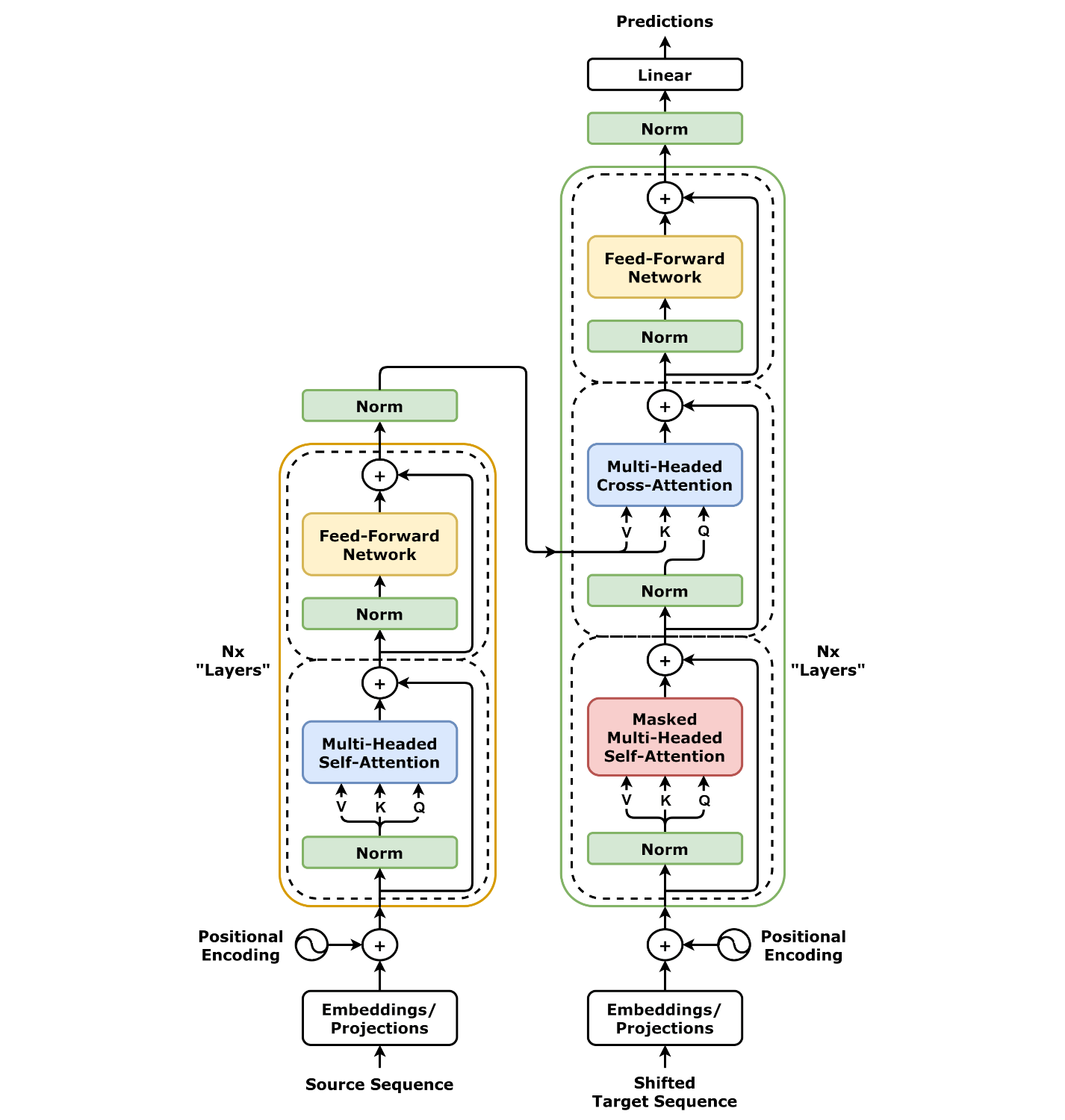
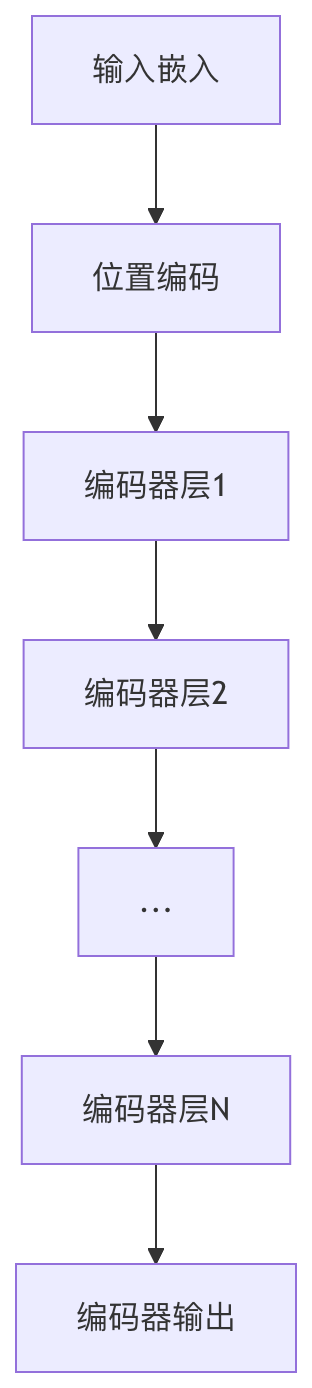
Transformer 架构图
左边为编码器,右边为解码器。
1. 输入处理(底部)
2. 编码器(左侧)
3. 解码器(右侧)
4. 输出(顶部)
Transformer 的核心思想
自注意力机制(Self-Attention)
Transformer 的核心思想是完全依赖注意力机制(无需循环或卷积结构)来捕捉输入序列中的全局依赖关系,从而实现高效的并行计算和更强的长距离依赖建模。
实例
公式:
多头注意力(Multi-Head Attention)
位置编码(Positional Encoding)
前馈神经网络(Feed-Forward Network, FFN)
残差连接与层归一化(Residual Connection & Layer Norm)
并行处理能力
与传统RNN/LSTM不同,Transformer可以并行处理整个序列,极大提高了训练效率。
全局依赖建模
无论词与词之间的距离有多远,Transformer都能直接建立依赖关系,解决了长距离依赖问题。
编码器-解码器结构
Transformer采用经典的编码器-解码器架构,但每个部分都由多层相同的模块堆叠而成。
编码器(Encoder)
解码器(Decoder)
解码器在编码器基础上增加了:
位置编码(Positional Encoding)
由于Transformer没有循环结构,需要显式地注入位置信息。
正弦位置编码公式
公式分为两部分,分别对应位置编码向量的偶数维和奇数维: 偶数维(2i) , 奇数维(2i+1) 。
参数说明:
pos :词在序列中的位置(如第 1 个词、第 2 个词等)。
i :位置编码向量的维度索引( 0 ≤ i < d_model/2 )。
d_model :位置编码的维度(通常与词向量的维度相同,如 512、768 等)。
位置编码的特点
Transformer 的优势
与传统架构的对比
实际应用优势
实践练习
练习1:实现基础的自注意力
练习2:理解位置编码
常见问题解答
Q: Transformer为什么比RNN更适合长文本? A: RNN需要逐步传递信息,长距离依赖容易丢失;而Transformer可以直接建立任意两个词之间的关系。
Q: 位置编码为什么选择正弦函数? A: 正弦函数具有周期性且可以表示相对位置关系,同时可以扩展到训练时未见过的序列长度。
Q: Transformer的主要计算瓶颈在哪里? A: 自注意力机制的空间复杂度是O(n²),处理长序列时会消耗大量内存。
总结
Transformer架构通过自注意力机制彻底改变了序列建模的方式,其核心优势在于:
掌握Transformer的基本原理是学习现代NLP技术的重要基础,也是理解BERT、GPT等前沿模型的关键。