多模态预训练模型(Multimodal Pre-trained Models)是指能够同时处理和理解 多种数据模态 (如文本、图像、音频等)的深度学习模型。与传统的单模态模型不同,这些模型通过大规模预训练学习不同模态之间的关联和对应关系。
多模态学习的核心优势
CLIP:图文对比学习的里程碑
基本概念
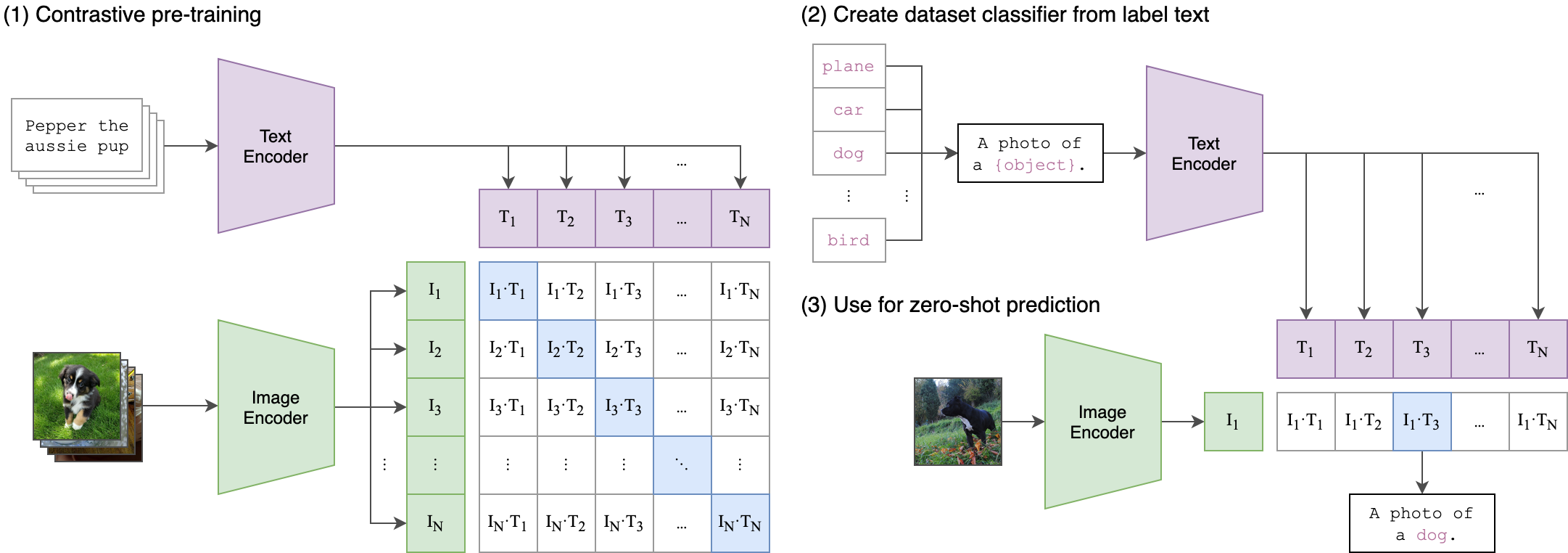
CLIP(Contrastive Language-Image Pre-training)是 OpenAI 于 2021 年提出的多模态模型,通过对比学习的方式建立图像和文本之间的关联。
CLIP 包含两个核心组件:
工作流程:
两者输出的特征向量会被映射到同一语义空间,通过对比学习对齐图像和文本的表示。
图中关键部分说明
表格部分:对比学习矩阵
表格展示了图像-文本对的相似度计算(假设有 N 个文本和 4 个图像):
目标 : 最大化对角线上的相似度(正确配对,如 I1-T1 ),最小化非对角线相似度(错误配对,如 I1-T2 )。这是对比学习的核心思想。
示例部分
模型架构
训练过程
实例
应用场景
DALL-E:文本到图像的生成魔法
DALL-E 是 OpenAI 开发的文本到图像生成模型,能够根据自然语言描述生成高质量的图像。
技术特点
生成过程示例
模型演进
其他重要多模态模型
ALIGN(Google)
Flamingo(DeepMind)
BEiT-3(Microsoft)
多模态模型的应用挑战
实践练习:使用 CLIP 进行零样本分类
未来发展方向
多模态预训练模型正在重塑人机交互的方式,从 CLIP 的跨模态理解到 DALL-E 的创造性生成,这些技术为 AI 应用开辟了全新的可能性。