و•°وچ®وµپوµ‹è¯•ç”¨ن؛ژهˆ†وگ程ه؛ڈن¸çڑ„و•°وچ®وµپم€‚ه®ƒوک¯و”¶é›†وœ‰ه…³هڈکé‡ڈه¦‚ن½•هœ¨ç¨‹ه؛ڈن¸وµپهٹ¨و•°وچ®çڑ„ن؟،وپ¯çڑ„è؟‡ç¨‹م€‚ه®ƒè¯•ه›¾èژ·هڈ–è؟‡ç¨‹ن¸و¯ڈن¸ھ特ه®ڑ点çڑ„特ه®ڑن؟،وپ¯م€‚
و•°وچ®وµپوµ‹è¯•وک¯ن¸€ç»„وµ‹è¯•ç–略,用ن؛ژو£€وں¥ç¨‹ه؛ڈçڑ„وژ§هˆ¶وµپ,ن»¥ن¾؟و ¹وچ®ن؛‹ن»¶çڑ„é،؛ه؛ڈوژ¢ç´¢هڈکé‡ڈه؛ڈهˆ—م€‚ه®ƒن¸»è¦په…³و³¨هˆ†é…چç»™هڈکé‡ڈçڑ„ه€¼çڑ„点ن»¥هڈٹن½؟用è؟™ن؛›ه€¼çڑ„点,é€ڑè؟‡é›†ن¸هœ¨è؟™ن¸¤ن¸ھ点ن¸ٹ,هڈ¯ن»¥وµ‹è¯•و•°وچ®وµپم€‚
و•°وچ®وµپوµ‹è¯•ن½؟用وژ§هˆ¶وµپه›¾و¥و£€وµ‹هڈ¯èƒ½ن¸و–و•°وچ®وµپçڑ„ن¸چهگˆé€»è¾‘çڑ„ن؛‹وƒ…م€‚ç”±ن؛ژن»¥ن¸‹هژںه› ,هœ¨ه€¼ه’Œهڈکé‡ڈن¹‹é—´ه…³èپ”و—¶و£€وµ‹هˆ°و•°وچ®وµپن¸çڑ„ه¼‚ه¸¸ï¼ڑ
- ه¦‚وœهœ¨وœھهˆه§‹هŒ–çڑ„وƒ…ه†µن¸‹ن½؟用هڈکé‡ڈم€‚
- ه¦‚وœهˆه§‹هŒ–çڑ„هڈکé‡ڈوœھ至ه°‘ن½؟用ن¸€و¬،م€‚
让وˆ‘ن»¬é€ڑè؟‡ن¸€ن¸ھن¾‹هگو¥çگ†è§£è؟™ن¸€ç‚¹ï¼ڑ
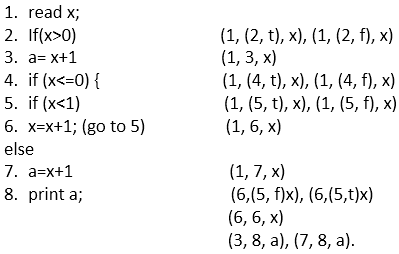
هœ¨و¤ن»£ç پن¸ï¼Œوˆ‘ن»¬و€»ه…±وœ‰ 8 ن¸ھè¯هڈ¥ï¼Œوˆ‘ن»¬ه°†é€‰و‹©ن¸€و،و¶µç›–و‰€وœ‰ 8 ن¸ھè¯هڈ¥çڑ„è·¯ه¾„م€‚و£ه¦‚ن»£ç پن¸ه¾ˆوکژوک¾çڑ„é‚£و ·ï¼Œوˆ‘ن»¬ن¸چ能هœ¨هچ•ن¸ھè·¯ه¾„ن¸و¶µç›–و‰€وœ‰è¯هڈ¥ï¼Œه› ن¸؛ه¦‚وœè¯هڈ¥ 2 ن¸؛çœں,هˆ™ن¸چ覆盖è¯هڈ¥ 4م€پ5م€پ6م€پ7,ه¦‚وœè¯هڈ¥ 4 ن¸؛çœں,هˆ™ن¸چ覆盖è¯هڈ¥ 2 ه’Œ 3م€‚
ه› و¤ï¼Œوˆ‘ن»¬é‡‡هڈ–ن¸¤و،途ه¾„و¥و¶µç›–و‰€وœ‰é™ˆè؟°م€‚
| 1. x= 1 Path - 1, 2, 3, 8
输ه‡؛ = 2 |
ه½“وˆ‘ن»¬é¦–ه…ˆه°† x çڑ„ه€¼è®¾ç½®ن¸؛ 1 و—¶ï¼Œه®ƒن¼ڑهœ¨و¥éھ¤ 1 读هڈ–ه¹¶هˆ†é…چ x çڑ„ه€¼ï¼ˆوˆ‘ن»¬هœ¨è·¯ه¾„ن¸هڈ–ن؛† 1),然هگژوک¯è¯هڈ¥ 2(x>0(وˆ‘ن»¬هœ¨è·¯ه¾„ن¸هڈ–ن؛† 2)),è؟™وک¯çœںçڑ„,ه®ƒه‡؛çژ°هœ¨è¯هڈ¥ 3 ن¸ٹ(a= x+1(وˆ‘ن»¬هœ¨è·¯ه¾„ن¸هڈ–ن؛† 3))وœ€هگژه®ƒه‡؛çژ°هœ¨è¯هڈ¥ 8 ن¸ٹن»¥و‰“هچ° x çڑ„ه€¼ï¼ˆè¾“ه‡؛ن¸؛ 2)م€‚
ه¯¹ن؛ژ第ن؛Œو،è·¯ه¾„,وˆ‘ن»¬هڈ– x çڑ„ه€¼ن¸؛ 1
| 2. Set x= -1 Path = 1, 2, 4, 5, 6, 5, 6, 5, 7, 8
输ه‡؛ = 2 |
ه½“وˆ‘ن»¬ه°† x çڑ„ه€¼è®¾ç½®ن¸؛ 1 و—¶ï¼Œé¦–ه…ˆï¼Œه®ƒه‡؛çژ°هœ¨و¥éھ¤ 1 读هڈ–ه¹¶هˆ†é…چ x çڑ„ه€¼ï¼ˆوˆ‘ن»¬هœ¨è·¯ه¾„ن¸هڈ–ن؛† 1),然هگژوک¯و¥éھ¤ 2,è؟™وک¯هپ‡çڑ„,ه› ن¸؛ x ن¸چه¤§ن؛ژ 0(x>0 ه’Œه®ƒن»¬çڑ„ x=-1)م€‚ç”±ن؛ژ false و،ن»¶ï¼Œه®ƒن¸چن¼ڑه‡؛çژ°هœ¨è¯هڈ¥ 3 ن¸ٹه¹¶ç›´وژ¥è·³è½¬هˆ°è¯هڈ¥ 4(وˆ‘ن»¬هœ¨è·¯ه¾„ن¸هڈ–ن؛† 4),4 ن¸؛çœں(x<=0 ه¹¶ن¸”ه®ƒن»¬çڑ„ x ه°ڈن؛ژ 0),然هگژه‡؛çژ°هœ¨è¯هڈ¥ 5 ن¸ٹ(x<1(وˆ‘ن»¬هœ¨è·¯ه¾„ن¸هڈ–ن؛† 5)),è؟™ن¹ںوک¯çœںçڑ„,و‰€ن»¥ه®ƒه°†ه‡؛çژ°هœ¨è¯هڈ¥ 6 ن¸ٹ(x=x+1(وˆ‘ن»¬هœ¨è·¯ه¾„ن¸هڈ–ن؛† 6)),è؟™é‡Œ x 递ه¢ 1م€‚
و‰€ن»¥
وœ‰ x çڑ„ه€¼هڈکن¸؛ 0م€‚çژ°هœ¨ه®ƒè½¬هˆ°è¯هڈ¥ 5(x<1(وˆ‘ن»¬هœ¨è·¯ه¾„ن¸هڈ–ن؛† 5)),ه€¼ن¸؛ 0,0 ه°ڈن؛ژ 1,ه› و¤ï¼Œè؟™وک¯çœںçڑ„م€‚و¥هگ§è¯هڈ¥ 6(x=x+1(وˆ‘ن»¬هœ¨è·¯ه¾„ن¸هڈ–ن؛† 6))
x هڈکوˆگن؛† 1,ه†چو¬،转هˆ°è¯هڈ¥ 5(x<1(وˆ‘ن»¬هœ¨è·¯ه¾„ن¸هڈ–ن؛† 5)),çژ°هœ¨ 1 ن¸چه°ڈن؛ژ 1,و‰€ن»¥و،ن»¶ن¸؛ false,ه®ƒه°†و¥هˆ° else 部هˆ†è،¨ç¤؛è¯هڈ¥ 7(a=x+1,ه…¶ن¸ x çڑ„ه€¼ن¸؛ 1)ه¹¶ه°†ه€¼هˆ†é…چç»™ a (a=2)م€‚وœ€هگژ,ه®ƒه‡؛çژ°هœ¨è¯هڈ¥ 8 ن¸ٹه¹¶و‰“هچ°ه€¼ï¼ˆè¾“ه‡؛ن¸؛ 2)م€‚
ن¸؛ن»£ç په»؛ç«‹ه…³èپ”ï¼ڑ
ه…³èپ”
هœ¨ه…³èپ”ن¸ï¼Œوˆ‘ن»¬هˆ—ه‡؛ن؛†و‰€وœ‰ه®ڑن¹‰هڈٹه…¶و‰€وœ‰ç”¨é€”م€‚
(1, (2, f), x), (1, (2, t), x), (1, 3, x), (1, (4, t), x), (1, (4, f), x), (1, (5, t), x), (1, (5, f), x), (1, 6, x), (1, 7, x), (6,(5, f)x), (6,(5, t)x), (6, 6, x), (3, 8, a), (7, 8, a)م€‚
ه¦‚ن½•هœ¨و•°وچ®وµپوµ‹è¯•ن¸ه»؛ç«‹ه…³èپ”<链وژ¥>

- (1, (2, t), x), (1, (2, f), x)- و¤ه…³èپ”ن¸ژè¯هڈ¥ 1(读ن½œ x;)ه’Œè¯هڈ¥ 2 (If(x>0)),ه…¶ن¸ x هœ¨ç¬¬ 1 è،Œه®ڑن¹‰ï¼Œه¹¶هœ¨ç¬¬ 2 è،Œن½؟用,ه› و¤ x وک¯هڈکé‡ڈم€‚
è¯هڈ¥ 2 وک¯هگˆن¹ژ逻辑çڑ„,ه®ƒهڈ¯ن»¥وک¯çœںوˆ–هپ‡ï¼Œè؟™ه°±وک¯ن¸؛ن»€ن¹ˆن»¥ن¸¤ç§چو–¹ه¼ڈه®ڑن¹‰ه…³èپ”çڑ„هژںه› ;ن¸€ن¸ھوک¯ï¼ˆ1,(2,t),x)è،¨ç¤؛çœں,هڈ¦ن¸€ن¸ھوک¯ï¼ˆ1,(2,f),x)è،¨ç¤؛هپ‡م€‚
- (1, 3, x)- و¤ه…³èپ”ن¸ژè¯هڈ¥ 1(读ن½œ x;)ه’Œè¯هڈ¥ 3 (a= x+1),ه…¶ن¸ x هœ¨è¯هڈ¥ 1 ن¸ه®ڑن¹‰ه¹¶هœ¨è¯هڈ¥ 3 ن¸ن½؟用م€‚è؟™وک¯ن¸€ç§چè®،算用途م€‚
- (1, (4, t), x), ( 1, (4, f), x)- و¤ه…³èپ”ن¸ژè¯هڈ¥ 1(读ن½œ x;)ه’Œè¯هڈ¥ 4 (If(x<=0)),ه…¶ن¸ x هœ¨ç¬¬ 1 è،Œه®ڑن¹‰ï¼Œهœ¨ç¬¬ 4 è،Œن½؟用,ه› و¤ x وک¯هڈکé‡ڈم€‚è¯هڈ¥ 4 وک¯هگˆن¹ژ逻辑çڑ„,ه®ƒهڈ¯ن»¥وک¯çœںوˆ–هپ‡ï¼Œè؟™ه°±وک¯ن¸؛ن»€ن¹ˆن»¥ن¸¤ç§چو–¹ه¼ڈه®ڑن¹‰ه…³èپ”çڑ„هژںه› ,ن¸€ç§چوک¯ (1, (4, t), x) è،¨ç¤؛çœں,هڈ¦ن¸€ç§چوک¯ (1, (4, f), x) è،¨ç¤؛هپ‡م€‚
- (1, (5, t), x), ( 1, (5, f), x)- و¤ه…³èپ”ن¸ژè¯هڈ¥ 1(读ن½œ x;)ه’Œè¯هڈ¥ 5(if (x<1)),ه…¶ن¸ x هœ¨ç¬¬ 1 è،Œه®ڑن¹‰ï¼Œهœ¨ç¬¬ 5 è،Œن½؟用,ه› و¤ x وک¯هڈکé‡ڈم€‚
è¯هڈ¥ 5 وک¯هگˆن¹ژ逻辑çڑ„,ه®ƒهڈ¯ن»¥وک¯çœںçڑ„وˆ–هپ‡çڑ„,è؟™ه°±وک¯ن¸؛ن»€ن¹ˆن»¥ن¸¤ç§چو–¹ه¼ڈه®ڑن¹‰ه…³èپ”çڑ„هژںه› ;ن¸€ن¸ھوک¯ï¼ˆ1,(5,t),x)è،¨ç¤؛çœں,هڈ¦ن¸€ن¸ھوک¯ï¼ˆ1,(5,f),x)è،¨ç¤؛هپ‡م€‚
- (1, 6, x)- و¤ه…³èپ”ن¸ژè¯هڈ¥ 1(读ن½œ x;)ه’Œè¯هڈ¥ 6 (x=x+1)م€‚x هœ¨è¯هڈ¥ 1 ن¸ه®ڑن¹‰ï¼Œهœ¨è¯هڈ¥ 6 ن¸ن½؟用م€‚è؟™وک¯ن¸€ç§چè®،算用途م€‚
- (1, 7, x)- è؟™ç§چه…³èپ”ن¸ژè¯هڈ¥ 1(读هڈ– x)ه’Œè¯هڈ¥ 7 (a=x+1) 相ه…³èپ”م€‚x هœ¨è¯هڈ¥ 1 ن¸ه®ڑن¹‰ï¼Œه½“è¯هڈ¥ 5 ن¸؛ false و—¶هœ¨è¯هڈ¥ 7 ن¸ن½؟用م€‚è؟™وک¯ن¸€ç§چè®،算用途م€‚
- (6, (5, f) x ), (6, (5, t) x)- و¤ه…³èپ”ن¸ژè¯هڈ¥ 6 (x=x+1;) ن¸€èµ·ه»؛ç«‹ه’Œè¯هڈ¥ 5 ه¦‚وœ (x<1),ه› ن¸؛ x هœ¨è¯هڈ¥ 6 ن¸ه®ڑن¹‰ه¹¶هœ¨è¯هڈ¥ 5 ن¸ن½؟用م€‚è¯هڈ¥ 5 وک¯هگˆن¹ژ逻辑çڑ„,ه®ƒهڈ¯ن»¥وک¯çœںوˆ–هپ‡ï¼Œè؟™ه°±وک¯ن¸؛ن»€ن¹ˆن»¥ن¸¤ç§چو–¹ه¼ڈه®ڑن¹‰ه…³èپ”çڑ„هژںه› ,ن¸€ç§چوک¯ (6, (5, f) x) è،¨ç¤؛çœں,هڈ¦ن¸€ç§چوک¯ (6, (5, t) x) è،¨ç¤؛هپ‡م€‚è؟™وک¯é¢„وµ‹çڑ„用途م€‚
- (6, 6, x)- و¤ه…³èپ”ن¸ژè¯هڈ¥ 6 ه»؛立,è¯هڈ¥ 6 ن½؟用هڈکé‡ڈ x çڑ„ه€¼ï¼Œç„¶هگژه®ڑن¹‰ x çڑ„و–°ه€¼م€‚ x=x+1 x= (-1+1) è¯هڈ¥ 6 ن½؟用هڈکé‡ڈ x çڑ„ه€¼ن¸؛ ï¼ں1,然هگژه®ڑن¹‰و–°ه€¼ x [
x= (-1+1)
= 0],هچ³ 0م€‚
- (3, 8, a)- و¤ه…³èپ”ن¸ژè¯هڈ¥ 3(a= x+1) ه’Œè¯هڈ¥ 8 ه»؛立,ه…¶ن¸هڈکé‡ڈ a هœ¨è¯هڈ¥ 3 ن¸ه®ڑن¹‰ه¹¶هœ¨è¯هڈ¥ 8 ن¸ن½؟用م€‚
- (7, 8, a)- و¤ه…³èپ”ن¸ژè¯هڈ¥ 7(a=x+1) ه’Œè¯هڈ¥ 8 ه»؛立,ه…¶ن¸هڈکé‡ڈ a هœ¨è¯هڈ¥ 7 ن¸ه®ڑن¹‰ه¹¶هœ¨è¯هڈ¥ 8 ن¸ن½؟用م€‚
ه®ڑن¹‰ï¼Œc-use,p-use,c-use ن¸€ن؛›p-use覆盖çژ‡ï¼Œp-ن½؟用ن¸€ن؛›c-use覆盖çژ‡هœ¨و•°وچ®وµپوµ‹è¯•ن¸<链وژ¥>
ن¸‹ن¸€ن¸ھن»»هٹ،وک¯ه°†و‰€وœ‰ه…³èپ”هˆ†ç»„هˆ°ه®ڑن¹‰م€پc ن½؟用م€پp ن½؟用م€پc-use ن¸€ن؛› p ن½؟用覆盖çژ‡م€پp ن½؟用ن¸€ن؛› c ن½؟用覆盖çژ‡ç±»هˆ«ن¸م€‚
请هڈ‚éک…ن¸‹é¢çڑ„ن»£ç پï¼ڑ
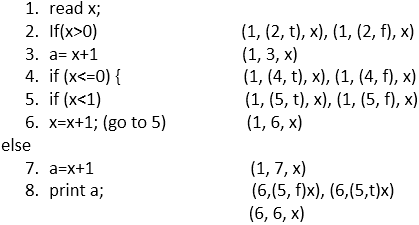
ه› و¤ï¼Œè؟™ن؛›وک¯هŒ…هگ«ه®ڑن¹‰ï¼Œè°“è¯چن½؟用(p-use),è®،ç®—ن½؟用(c-use)çڑ„و‰€وœ‰ه…³èپ”
(1, (2, f), x), (1, (2, t), x), (1, 3, x), (1, (4, t), x), (1, (4, f), x), (1, (5, t), x), (1, (5, f), x), (1, 6, x), (1, 7, x), (6,(5, f)x), (6,(5, t)x), (6, 6, x), (3, 8, a), (7, 8, a), (7, 8, a)
ه®ڑن¹‰
هڈکé‡ڈçڑ„ه®ڑن¹‰وک¯ه½“ه€¼ç»‘ه®ڑهˆ°هڈکé‡ڈو—¶هڈکé‡ڈçڑ„ه‡؛çژ°م€‚هœ¨ن¸ٹé¢çڑ„ن»£ç پن¸ï¼Œه€¼هœ¨ç¬¬ن¸€ن¸ھè¯هڈ¥ن¸ç»‘ه®ڑ,然هگژه¼€ه§‹وµپهٹ¨م€‚
و‰€وœ‰ه®ڑن¹‰è¦†ç›–范ه›´
(1, (2, f), x), (6, (5, f) x), (3, 8, a), (7, 8, a).
è°“è¯ç”¨و³•ï¼ˆp-用و³•ï¼‰
ه¦‚وœهڈکé‡ڈçڑ„ه€¼ç”¨ن؛ژç،®ه®ڑو‰§è،Œè·¯ه¾„,هˆ™è¢«è§†ن¸؛è°“è¯چن½؟用 (p-use)م€‚هœ¨وژ§هˆ¶وµپè¯هڈ¥ن¸وœ‰ن¸¤ن¸ھ
è¯هڈ¥ 4 if (x<=0) وک¯è°“è¯چن½؟用,ه› ن¸؛ه®ƒهڈ¯ن»¥وک¯è°“è¯چ true وˆ– falseم€‚ه¦‚وœن¸؛çœں,هˆ™ه¦‚وœ (x<1),6x=x+1;هگ¦هˆ™ه°†و‰§è،Œè·¯ه¾„,هگ¦هˆ™ه°†و‰§è،Œè·¯ه¾„م€‚
è®،ç®—ن½؟用(c-use)
ه¦‚وœهڈکé‡ڈçڑ„ه€¼ç”¨ن؛ژè®،算输ه‡؛ه€¼وˆ–ه®ڑن¹‰هڈ¦ن¸€ن¸ھهڈکé‡ڈم€‚
è¯هڈ¥ 3 a= x+1 (1, 3, x) è¯هڈ¥ 7 a=x+1 (1, 7, x)
è¯هڈ¥ 8 و‰“هچ° a (3, 8, a), ( 7 , 8, a)م€‚
è؟™ن؛›وک¯ è®،算用途 ,ه› ن¸؛ x çڑ„ه€¼ç”¨ن؛ژè®،算,a çڑ„ه€¼ç”¨ن؛ژ输ه‡؛م€‚
و‰€وœ‰c-use覆盖
(1, 3, x), (1, 6, x), (1, 7, x), (6, 6, x), (6, 7, x), (3, 8, a), (7, 8, a).
و‰€وœ‰ c ن½؟用ن¸€ن؛› p 用途覆盖çژ‡
(1, 3, x), (1, 6, x), (1, 7, x), (6, 6, x), (6, 7, x), (3, 8, a), (7, 8, a).
و‰€وœ‰ p ن½؟用ن¸€ن؛› c 用途覆盖
(1, (2, f), x), (1, (2, t), x), (1, (4, t), x), (1, (4, f), x), (1, (5, t), x), (1, (5, f), x), (6, (5, f), x), (6, (5, t), x), (3, 8, a), (7, 8, a).
و”¶é›†è؟™ن؛›ç»„هگژ,(é€ڑè؟‡و£€وں¥و¯ڈن¸ھ点وک¯هگ¦è‡³ه°‘ن½؟用ن¸€و¬،هڈکé‡ڈ)وµ‹è¯•ن؛؛ه‘کهڈ¯ن»¥çœ‹هˆ°و‰€وœ‰è¯هڈ¥ه’Œهڈکé‡ڈ都被ن½؟用م€‚وœھن½؟用ن½†هکهœ¨ن؛ژن»£ç پن¸çڑ„è¯هڈ¥ه’Œهڈکé‡ڈه°†ن»ژن»£ç پن¸هˆ 除م€‚ |








