import pandas
from sklearn import tree
import pydotplus
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import matplotlib.image as pltimg
df = pandas.read_csv("shows.csv")print(df)
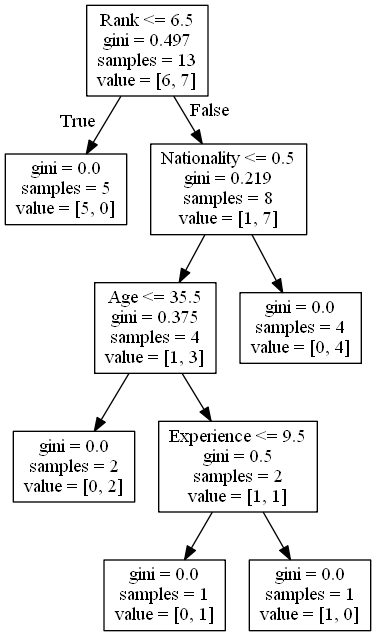
如需制作决策树,所有数据都必须是数字。
我们必须将非数字列 “Nationality” 和 “Go” 转换为数值。
Pandas 有一个 map() 方法,该方法接受字典,其中包含有关如何转换值的信息。
d ={'UK':0,'USA':1,'N':2}
df['Nationality']= df['Nationality'].map(d)
d ={'YES':1,'NO':0}
df['Go']= df['Go'].map(d)print(df)
表示将值 'UK' 转换为 0,将 'USA' 转换为 1,将 'N' 转换为 2。
实例
将字符串值更改为数值:
d ={'UK':0,'USA':1,'N':2}
df['Nationality']= df['Nationality'].map(d)
d ={'YES':1,'NO':0}
df['Go']= df['Go'].map(d)print(df)
然后,我们必须将特征列与目标列分开。
特征列是我们尝试从中预测的列,目标列是具有我们尝试预测的值的列。
实例
X 是特征列,y 是目标列:
features =['Age','Experience','Rank','Nationality']
X = df[features]
y = df['Go']print(X)print(y)